The key promise of cloud computing is flexibility, so it’s ok if you don’t know exactly which resources or how much capacity you need. The cloud scales up or down according to your needs. No need to plan or understand the nitty gritty details of how it works—the cloud adapts automatically.
OpenSearch is an incredibly popular search technology in the cloud. With OpenSearch, you have a rich, open source feature set without any proprietary dependencies. But while the cloud is a natural place to host OpenSearch, no OpenSearch cloud services have achieved the real promise of the cloud: Full flexibility to scale to your needs. Horizontal scaling (adding more nodes) is straightforward, but vertical scaling, where you change the hardware specifications of your data nodes, might be a long project! Because OpenSearch isn’t flexible, many users end up overprovisioning and paying for cloud capacity they’re not using to avoid the pain of adding more capacity later.
At Oracle Cloud Infrastructure (OCI), we adhere to the following principles across all of our services:
- Meet the customers where they are: Minimize changes on the customer transitioning their workloads to the cloud.
- Pay exactly per what you use with a clear and fair billing strategy.
In accordance with these OCI principles, we developed a cloud offering to take on the problem of vertical scaling and transform it from a hard edge case to a simple common case for the customer to change specification. To handle this problem, we designed a way to automatically scale hardware specifications behind the scenes, so customers don’t have to purchase extra capacity, juggle performance tradeoffs, or be OpenSearch subject matter experts (SMEs). Resizing your instance should require just an API call, not a project plan.
In this part 1 of our two-part series on improving OpenSearch flexibility, we cover how our OCI OpenSearch team took on the problem of vertical scaling and how we created an OpenSearch Service architecture that you can scale seamlessly without performance degradation. In the next post, we cover how we improved the experience of horizontal scaling, increasing the OpenSearch cluster limit of 250 data nodes to 750 data nodes.
First, let’s cover some OpenSearch basics. If you’re already familiar with OpenSearch terminology, you can skip ahead.
OpenSearch basics
OpenSearch is an open source distributed search and analytics engine. It’s especially popular as a cloud-hosted tool because it can be an operational headache. Managing nodes, clusters, and indices while maintaining both low latency and high availability is a real challenge! As a result, many enterprises rely on OpenSearch cloud services. At OCI, we’re dedicated to deliver the performance that OpenSearch is beloved for.
An OpenSearch cluster is a set of interconnected servers, each called a node, which work together to quickly store, search, and analyze vast amounts of data in near real-time. Data is organized into collections, known as indices, and each index consists of documents, which are individual records or data entries. To efficiently manage and distribute data, indices are divided into even smaller parts called shards. This structure allows OpenSearch to efficiently handle large-scale data operations.
To illustrate a basic OpenSearch cluster, let’s consider a four-node cluster with two indices (index a and index b), and opaque green boxes represent a primary shard and the transparent boxes represent a replica shard.
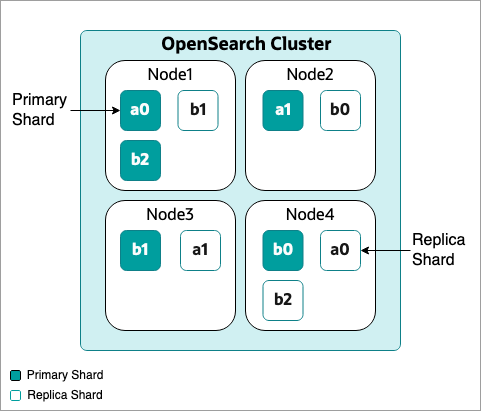
Figure 1: A basic OpenSearch cluster with four nodes, two indices, and multiple shards
In OpenSearch, replication improves both data availability and read performance. Replication means that data is copied across multiple nodes of a cluster, so that if one node fails, the data is still accessible from another node, making the OpenSearch instance fault-tolerant. Having replicas also allows OpenSearch to handle more read requests concurrently by spreading the load across different copies, which increases the system’s capacity to serve data.
Solving the customer problem
Generally, the way an OpenSearch customer sets up a cloud environment is to purchase a set of nodes to form a cluster and define the hardware specification, such as storage and performance, for each of their nodes based on their anticipated needs. The hardware specification of this storage and performance capacity is known as a shape. Usually, a cloud provider has a set of predefined shapes to choose from, though they might also allow for some customization.
The challenge with purchasing a predefined OpenSearch cluster shape is that it’s hard to predict the future. When customers need to change their shape and scale up their nodes to handle unanticipated search demand, they get hit with operational cost and performance penalties.
One way to avoid having to change your cluster is to pick and stay with bigger shapes than necessary. But we didn’t want to deliver such a self-serving message to customers. We knew we needed to solve this problem of predefined shapes and create a better experience for scaling up hardware. So, we got to work designing a flexible OpenSearch service architecture that could easily scale, without requiring laborious operational overhead or sacrificing performance.
Pay As You Go (PAYG)
In many traditional, predefined OpenSearch shapes, storage and compute were part of a package deal. The best storage specs were usually grouped with the best compute specs. This setup led to some confusion about what customer needs were. We heard from many customers who wanted top-of-the-line bare metal storage, but after we investigated, what they needed was more compute capability, not storage! They thought they needed bare metal because it was historically combined with the best-performant shapes.
OCI understands the significance for customers to have the flexibility to scale different hardware specs independently. To achieve, this storage with the right size and guaranteed performance has been separated from the compute into block storage resources. Then we launched flex shapes for compute to let customers to specify the OCPU and memory quantities independently. So, you can optimize your compute and have any variant of the shape you need without paying for extra storage you didn’t need.
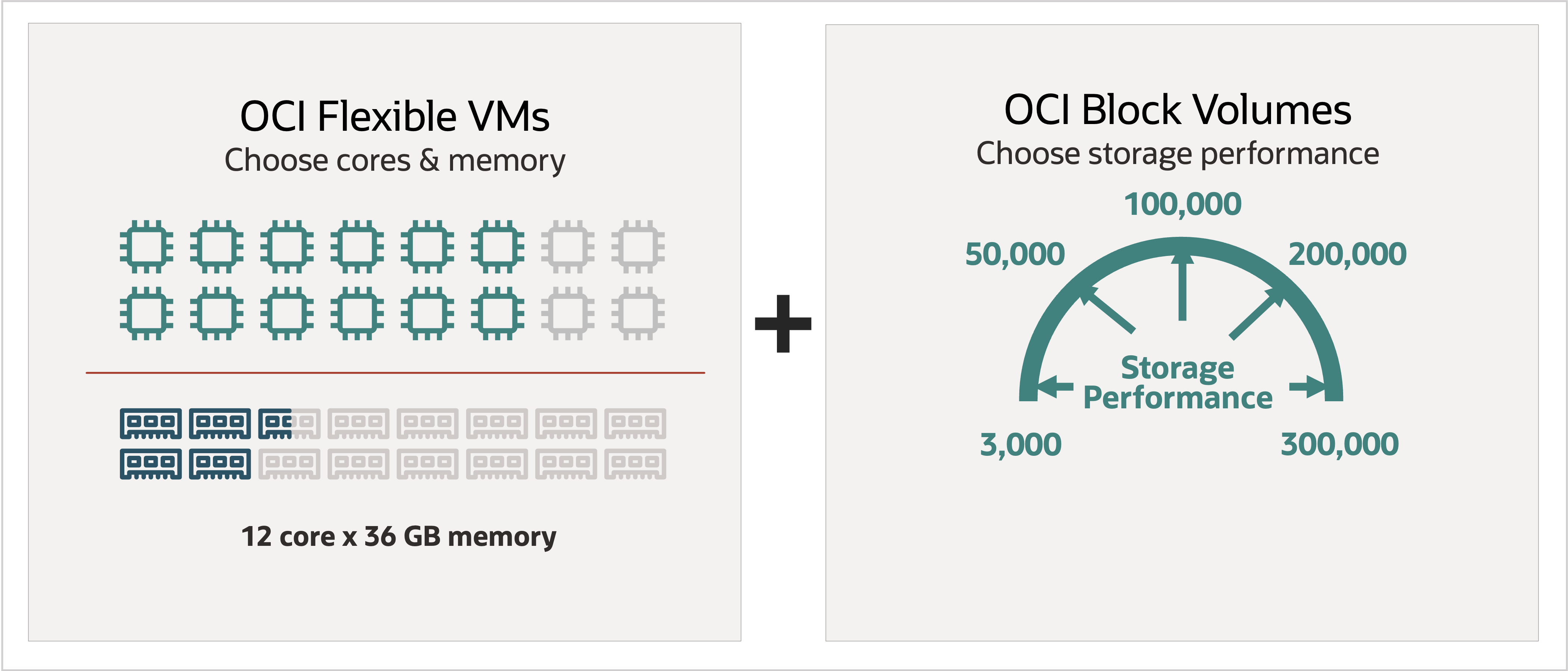
Figure 2: OCI Flex shapes enable customers to customize the number of cores, memory, and storage for more efficiency
Solving the next problem: Vertical scaling
Splitting compute and storage gave us a much more elastic, flexible architecture, and was a big win for customers. But while customers could purchase storage and compute independently, they still had a problem. When running software like OpenSearch, simply provisioning a new, better fitting computer doesn’t automatically upgrade or replace the existing computer. We got to work, thinking about how to make these scale-up transitions smoother.
To enable customers to utilize the flexible arch we built, we needed a good solution around vertical scaling. Vertical scaling is the process of increasing the hardware specs of your existing nodes without changing the number of nodes. For example, you might vertically scale your nodes if you want to improve your query performance. Contrast vertical scaling with horizontal scaling, which adds more nodes to the cluster instead of changing nodes’ hardware specs.
Vertical scaling with blue-green deployments
The simplest way to vertically scale nodes is to shut down the nodes, add the new capacity, such as number of CPU cores or more RAM, and then restart the nodes. But then the nodes are offline for as long as it takes you to add the new capacity. To avoid downtime, you might vertically scale a node using a blue-green deployment.
Blue-green is a software release strategy that reduces downtime and risk by running two identical production environments—respectively called blue and green—then switching traffic from the older blue environment to the new green environment when it’s tested and ready. Vertically scaling using a blue-green deployment uses the following steps:
- Creating entirely new nodes with the new specs (green environment)
- Moving the data shards from the old nodes (blue environment) to the new nodes (green environment)
- Releasing the old nodes (blue environment)
This blue-green deployment takes advantage of OpenSearch’s relocation mechanism, which reallocates shards in the cluster to be more efficient and resilient. For example, if your new green environment has different node structure (perhaps because of scaling or hardware changes), you might need to relocate shards to these new nodes before the switch to ensure that the data is balanced and optimized before the blue nodes are deleted.
Figure 3: The process of blue green deployments, enabling customers to add new capacity to nodes with little downtime
The performance limitations of flexible shapes
While this blue-green solution works well for vertically scaling basic node clusters, it runs into performance limitations in large-scale deployments that store lots of data. Let’s take a closer look at the steps required to copy a chunk of data from one node to another with a blue-green deployment:
- Read data from block volume disk: This involves network IO bandwidth because the block volume is a remote attachment, not a local disk.
- Copy data to RAM, which is stored in the operating system cache.
- Copy data from operating system cache into the Java virtual machine (JVM).
- Send data to the new node: From JVM, the data is copied again to outbound buffer and out into the remote host, which requires both CPU cycles and network IO.
These processes are computationally expensive. They consume network IO and some CPU cycles proportional to the size of the data being copied. A node reading and sending large amounts of data can easily exhaust the host network IO throughput.
To illustrate how this limitation makes a difference, consider a cluster with a single core data node, 15 GB of RAM, and 3 TB of disk storage. How long would it take to replicate this node?
In a flexible Compute shape, the network IO is about 0.8 Gbps per core. Assuming 100% copying efficiency and allocating the entire network bandwidth available on the node to the task, copying 3 TB of data takes about 8.5 hours. However, the block volume is also consuming network IO, so the effective network IO available for transmitting is probably only about half the optimal rate, making the replication time about 17 hours.
But copying isn’t an efficient process. It incurs at least 30% overhead because of the chunks sent to a remote node or TCP packets. So, you’re looking at about 25 hours to replicate. Finally, you might want to rate limit the process to avoid bringing the node down. You need to choose a reasonable limit to avoid starving queries and indexing resources. So assuming 50% more time, now we’re looking at close to 40 hours to replicate a node! Replicating a node this slowly could present a customer with serious issues.
Customers are prevented from making more changes on their cluster until the replication is complete, so they can’t react to changing capacity conditions in a timely manner. Plus, cluster stability and performance are degraded during replication. If failure occurs, rolling back the vertical scaling is time-consuming and risky.
The easy thing to do at this point is to advise customers against creating clusters with a single core and 3 TB of disk storage. However, for a customer that’s mostly interested in storage over cores and doesn’t need more compute, it seems quite excessive to ask to provision more cores to have their monthly patching or other infrequent vertical scaling operations that require the blue-green deployment process.
So, we needed to do better. It just doesn’t make any sense for our customers.
Key win using OCI block volume replication
One of the immediate solutions that came to mind was using OCI primitives such as block volume replication, to achieve faster relocation of the data. Instead of involving the operating system and the CPU in the process of reading the block volume on the expense of production network IO, we can use block volume backup to establish the initial copy of the data and then perform additional incremental backups as we catch up the new node up to speed.
This approach helps for the following reasons:
- Block volumes can create backups by using the underlying network bandwidth of the entire hypervisor they’re hosted on. This process happens behind the scenes and doesn’t come at the expense of the block volume IOPS reserved for the customer.
- The ratio of network IO to the amount of storage on the hypervisor is always fixed, so we aren’t caught in a situation where network IO can’t scale with the increase in storage.
In the new way of using the blue green deployment, we found that when the new empty cluster with different specs was created, it only took us up to six minutes to replicate the entire data from the old cluster, no matter the size of the block volume on the source!
But we still weren’t finished. We needed to address the issue of writes that occur on a cluster during replication.
Blue green deployment v2
Using block volume native replication, the blue and green nodes got out of sync during replication because reads and writes continued happening on the source cluster. With the first version of our blue-green deployment, we were able to use the native OpenSearch relocation mechanism to keep the nodes in sync. But now that we were using block volumes, the relocation mechanism wasn’t available. We needed a different approach with the following steps:
- Establish a baseline replica by completely copying the current data on the source block volume over to a new green block volume.
- Keep copying deltas of the blue block volume to the new green one until they’re no longer drifting very far apart (about 30 seconds of delay).
- Set the blue block into a read-only state temporarily and sync one last final block volume delta to the green cluster.
- Switch all traffic to the green cluster.
Figure 4: Leveraging block volume replication for faster replication
With this method, we trade a few seconds of read-only mode on the source cluster for the following advantages:
- Transactional: We have a transactional switch between new and old state of the cluster. So, we can easily roll it back at any moment easily and safely without impacting the customer.
- No performance degradation: Customers don’t experience any performance degradation of any kind during the vertical scaling.
- Deterministic speed and shape-agnostic: The entire process of relocating data with blue-green deployment becomes fast irrespective of the original data size and its relationship with the other vertical specs on the node such as its core and RAM count.
Summary
Flexible vertical scaling for OpenSearch clusters used to be an operationally challenging task, but at OCI, we’ve taken the pressure off customers using innovative techniques that use the power of block volume replication. The new blue-green deployment mechanism we’ve pioneered ensures fast, reliable, and efficient data replication without compromising performance or placing undue burdens on our customers. By integrating native OpenSearch mechanisms with Oracle Cloud Infrastructure’s powerful block volume capabilities, we’ve bridged the gap between flexibility and efficiency, making sure our customers have truly adaptable OpenSearch support.
Consider the following takeaways from this post:
- Separating storage from compute created flexible shapes and enabled customers to only pay for what they use.
- Using blue-green deployment creates performance limitations for some customers.
- We used block volume replication to reduce replication time to six minutes, no matter the size of the cluster.
- Our v2 blue-green deployment trades a brief read-only period for no other performance degradation and easy rollbacks.
Remember to look for part 2 of this blog coming soon to the Behind the Scenes series, where we discuss horizontal scaling, and how we increased the OpenSearch cluster limit from 250 nodes to 750!
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
For more information, see the following resources:
