Anyone who has operated a service at a cloud company and been around the block a few times will know the story: You’re winding down on Friday afternoon, looking forward to a hard-earned weekend, when your phone goes off. You’re the on-call engineer, and an alarm threshold has been breached. This time, I was the Oracle Cloud Infrastructure (OCI) on-call engineer that develops a JavaScript web interface for internal operations. After some initial investigation, I determined that the problem was not with our service, but with some hard-to-pin-down issue in services downstream from us; as hackneyed as it is to say, it looked like a network issue. So, I paged the appropriate services, including the networking engineers.
Long story short, after agonizing troubleshooting, packet captures up and down the stack, and engaging vendors, we found out that the issues had been caused by a bad port on a networking device owned by a global transit provider (not OCI). So, then the question was: why is a JavaScript engineer discovering cyclic redundancy check (CRC) errors on an internet provider’s networking equipment? We get to the answer to this question in a follow-up blog post, but first, we need some history on what this internal UI is and how it works.
In this blog post, we dive into the internals of the DevOps Portal Experience: a single-page app that allows OCI employees to operate the Oracle cloud at a global scale. OCI engineers routinely manage deployments, alarms, metrics, workflows, certificates, and more in dozens (and soon in hundreds) of regions every day. If we didn’t have a world-class tool to perform this work, we’d be like an army of monkeys playing whack-a-mole. Fortunately, from the early days at OCI, we prioritized building a UI tool to make the day-to-day work of managing scores of regions with the following features:
- Secure by design
- Easy (and hopefully pleasant) to use
- Stable
We believe our decisions have paid off, and this post explains some of how that transpired behind the scenes.
The DevOps Portal Experience: Prehistory (1.0)
In the early days, one other OCI engineer and I were tasked with building a best-in-class internal operational user interface (UI) for the OCI engineering community, which was still less than 300 people at the time, but we knew we were going to be big. Both of us had previously worked at other large cloud providers, where we had used all the web tools available to internal developers there. There are so many amazing tools that the public never gets to see, but there’s also so much potential room for improvement! The two of us were fired up every day, reading about (and inventing) the most performant design, the best information architecture, and the most user-friendly tool we could imagine.
This web UI was originally used to show OCI engineers metrics about their services and resources, configure alarms on those metrics, and deploy code. Back then, we only had two regions: Our test and lab region and the first production region, us-phoenix-1. We decided to model the UI as a single-page application (SPA) that could make AJAX calls to the monitoring and deployment services, and dynamically update elements in the UI. As an old-school backend engineer-turned-web technologies advocate, I understand and respect the power of UNIX and the command-line, and I respect the common resistance to using flashy web tools to solve problems that are better solved with a handful of command line interface (CLI) tools that have stood the test of time.
But in some cases, the browser is the best choice. Viewing dozens of time-series curves all related to the same region or service? Monitoring 10 concurrent deployments of various pieces of your micro-service architecture? Interleaving logs from hundreds of hosts alongside a histogram showing log alert levels and corresponding metrics? In all these cases, a data-dense web UI is best, and in these cases, we set out to solve with the DevOps Portal Experience.
In the early days, it was only the two engineers and no designers working on the UI. Though I’d love to say we embraced the principles of atomic design, we were just trying our best to get pixels painted on the screen as quickly as possible to get the earliest iteration of OCI up and operating. Even so, performance and correctness were both very important, so we embraced unit and integration testing for the app, regular performance, and regression testing to ensure that we kept the DevOps Portal Experience performant and trustworthy.
React was also just taking off at the time, but hooks weren’t a thing yet, there was no context API, nobody had solved the global state problem properly, and there were still multiple ways (with no clear winner) to make an AJAX request. So, we did our best to follow industry-standard practice where it had been established, write shims and adapters where we knew APIs and libraries might change in the future, and generally keep our development process nimble.
OCI has been serious about security since the beginning. Services in one region can’t simply call out to services in another region, and this fact led to some interesting constraints. As the original DevOps Portal Experience engineers, we followed established security patterns. OCI was extremely stringent about region isolation in the beginning. By design, we had no way for one region to talk to another. We also weren’t allowed to make a super-UI that had the keys to everything. We needed to build this using the same principals the Oracle Cloud Console uses: Javascript makes calls to publicly available OCI services. The only difference is that the DevOps Portal Experience needs to communicate with a few OCI-internal-only services.
Within these constraints, we came up with an architecture that placed one DevOps Portal Experience UI in each region, which talked locally to the services in that region. If an OCI engineer wants to see metrics or do deployments in us-phoenix-1, they go to that web interface. If they want to check something out in our upcoming region (us-ashburn-1), they need to go to that UI, which live at a different address, and—importantly—required another user login, which involved presenting a client certificate to the browser. Secure, but tedious.
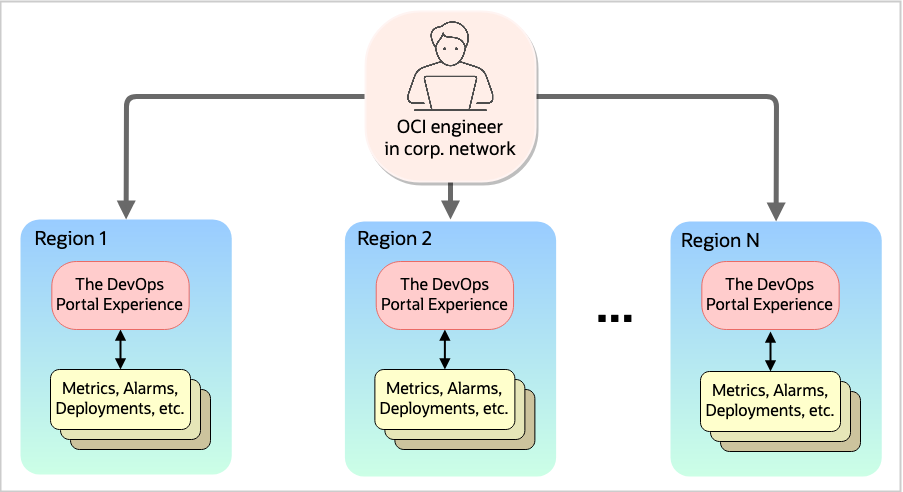
Figure 1: Original architecture of the DevOps Portal Experience when region isolation was a strong OCI tenet.
After only a few months with this architecture, we started noticing pain points. The DevOps Portal Experience logins required a username, password, and client certificate stored on a hardware two-factor device issued to all OCI employees. We heard many complaints from engineers who deployed in us-phoenix-1 and wanted to deploy in the next region without logging in again. This issue was made even worse after we launched eu-frankfurt-1, and then we expanded to hundreds of realms and regions for thousands of customers. The DevOps Portal Experience engineers could feel that change was afoot.
We can do better (2.0)
We had started to build something great, but we were falling short of our goal. Our dream was a tool that allows everyone at OCI to do their jobs as efficiently (and joyfully!) as possible, and then gets out of the way. This tool was getting in the way. We had to go back to the drawing board. To give engineers a single access point, we needed to come up with a different architecture. After a few whiteboard sessions, we decided that the right thing to do for our customers was to build a centralized web app that could connect to any internet-connected OCI region and query the services running there.
We hoped to have a single web UI that could gather diverse data (logs, alarms, metrics, deployments) from regions around the globe and display them to a customer in an easy-to-understand way. The promise was that a user could log in once and then get to work operating the global OCI cloud. The challenges were more subtle: How would the app route requests? How would we keep this service secure? Were we introducing a single point of failure to OCI operations?
We wanted to get it right, so we had discussions with major stakeholders. The security engineers helped us ensure that our design passed their high bar. By this point, OCI and some of its customers had important use cases for talking across region boundaries, and we ensured that the DevOps Portal Experience wasn’t unique. In many ways, the DevOps Portal Experience is modeled like an internal version of the Console. The code that runs in the user’s browser speaks across regional boundaries and talks to APIs.
With the new crossregional design, service engineers understood how they needed to expose their services and what we needed from them for authentication and authorization. Users expressed that they wanted everything to work as easily and seamlessly as possible. So, with those constraints, we set out to build the next iteration of the DevOps Portal Experience. The resulting tool is something we’re proud of and something that has continued to scale as OCI’s global region footprint climbs into the hundreds.
A state-of-the-art tool
From a DevOps Portal Experience user’s perspective, the new iteration of the web UI looks just like the old one. The only difference is that they only need to log in once, and then they can see what they need to see in any of the OCI regions, which, by the time we finished the overhaul, numbered a whopping four. Behind the scenes, we needed to transparently proxy the requests from the browser to the correct service in the correct region, while keeping the whole stack secure, fast, and scalable.
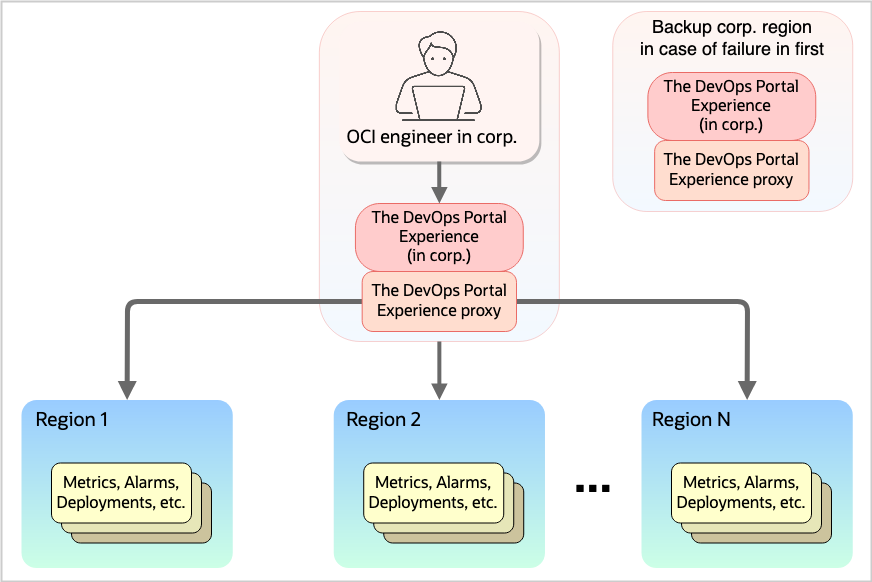
Figure 2: The DevOps Portal Experience’s architecture after we were allowed to talk across region boundaries.
One centralized UI with API call fan-out.
After we deployed the new design, the boost in productivity was immediately apparent. Operators could work on a deployment to one region while simultaneously checking metrics in the next region to ensure it was safe to continue the rollout, all in the same UI. They could easily check to ensure that alarm thresholds were similar across regions. The development experience was better. Because the DevOps Portal Experience is a single page application (SPA), the developers could store, collate, and compare data across regions to give users insights that weren’t possible before. Real-time dashboards showing region-wide key performance indicators (KPIs) with corresponding metrics were possible. Comparing log entries and showing anomalies between regions was possible. Most importantly, the more ergonomic and efficient experience allows OCI employees to do their job better, which translates into a more seamless experience for our public OCI customers.
One of the main disadvantages of this design is that all our operational eggs are now in a single DevOps Portal Experience basket. The original engineers didn’t take this trade-off lightly. We do everything we can to ensure that the tool is always available, including the following examples:
- The DevOps Portal Experience has a presence in two geographically distinct regions, each with three availability domains.
- We practice regular failover between those regions to ensure that it works.
- We roll out code in a phased way, ensuring that any regression doesn’t affect users globally.
- The DevOps Portal Experience tool itself has as few dependencies on other OCI services as possible. Any OCI service, even a fundamental one like Identity, must use the DevOps Portal Experience to troubleshoot any service problems. So, we can’t tolerate any circular dependencies.
In the years of building the DevOps Portal Experience, we have seen few incidents where it was unavailable and no incidents where both stacks were unavailable at the same time. For now, our decisions have panned out well! An informal poll of a sample of internal OCI employees who use the DevOps Portal Experience tells us that people have begun to take our high uptime for granted and always expect it to be available, even during large-scale network outages that we can’t control, such as the one in the introductory story.
What’s next?
After a few years of the DevOps Portal Experience proving its reliability and scalability, the members of the DevOps Portal Experience (for it had grown beyond just two) realized that we wanted to provide a platform for OCI employees to develop their own tools. We also realized that there are only so many hours in a day, and we couldn’t build world-class UIs for every service.
So, we took a cue from the Console engineers and federated plugin development. We still provide the solid foundation, but now OCI engineers can use their own UI expertise to iterate at their own pace and build specialty UIs for their use cases. We still maintain a component library that allows multiple services to choose off-the-shelf UI components, and we try to make that as general as possible, but sometimes you just need a special widget.
We’re building UIs that help make interservice dependency more explicit. If we want the DevOps Portal Experience to be a tool to promote true operational excellence, we need to be able to show users what’s happening immediately and why it might be happening. Service dependency graphs can help OCI operators get to the root cause of any problem faster, ultimately benefiting OCI customers.

Figure 3: An example of using the DevOps Portal Experience to show interservice dependencies and get to the root cause of an incident faster.
We’re doubling down on our canary (a monitoring system), which tracks not only our service’s ability to serve JavaScript to OCI employee’s browsers, but also indirectly monitors the DevOps Portal Experience’s connectivity to all services worldwide. A side effect of monitoring this way is that we have a high level of visibility into global networking events and are often the first ones to know when a span of fiber is cut somewhere in the world. We talk more about this concept in a future blog post. It’s one of the earliest signs that let operators know that something might be going on in OCI.
We continue to watch trends in the UI world and continue to focus on stability and usability. Some amazing CSS and JavaScript libraries are out there. But if any trend in the UI and UX world provides too much frill and not enough utility, we can hold out.
Conclusion
With OCI continuing to grow as an engineering organization and as the number of production and planned Oracle Cloud regions has grown beyond the hundred-region mark, the DevOps Portal Experience is still going strong, scaling properly, and has stood the test of time as one of the most reliable and performant OCI tools, as our thousands of daily users can confirm.
- We iterated on our design, working with limited knowledge and tools at the beginning and adjusting our expectations.
- We tried at every turn to do right by our customers.
- Reliability was our number one goal, with performance not far behind, and we continue to optimize where we can.
- We continue to be engaged with the Oracle Cloud Infrastructure engineering community, accepting their input to improve the DevOps Portal Experience even further.
As mentioned, we need to monitor this complex and ever-changing behemoth! It eventually led us to come up with our own canary, a monitoring system which continues to be a trend indicator of global internet traffic. But that’s a story for next time!
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
For more information, see the following resources:
- More on UI architecture with Behind the Scenes: Scaling UI for hundreds of services
- and Behind the Scenes: Building OCI’s next-generation UX with atomic design
