Have you ever been in a crucial meeting, trying to focus on the discussion at hand, when suddenly, the background noise from a chatty colleague becomes overwhelmingly distracting? Their constant chatter disrupts the flow of conversation, making it difficult for everyone to concentrate. Total buzzkill, right? Well, this scenario mirrors the “noisy neighbor” problem in a multitenant cloud environment, where a single customer’s traffic spike can create a ripple effect, impacting the experience of other customers sharing the same resources.
This noisy neighbor problem can be a major headache for cloud service providers and their customers. Most cloud services are designed to operate using shared resources, providing customers with the illusion of dedicated resources, much like the way everyone in a meeting room expects to have a fair chance to speak without interruptions. However, just as background noise can disrupt a meeting, noisy neighbors in the cloud can disrupt service performance, despite efforts to optimize resource allocation.
I am one of the lead engineers on our Network Address Translation (NAT) Gateway at Oracle Cloud Infrastructure (OCI). This means that if something bad starts happening to the service, I get a page. As a result, I am acutely aware of how important it is to provide a great, smooth service to our customers. This includes helping our customers curb noisy neighbor problems. While eliminating the noisy neighbor problem might mean that the service is unnecessarily expensive or that it loses some of the elasticity and flexibility that make cloud services so valuable, we built the Network Address Translation (NAT) Gateway to retain the beneficial properties of the cloud, while hiding the noisy neighbors from other customers. It’s like having a moderator in the meeting who helps everyone get a chance to speak while maintaining order and efficiency. And the best part? Despite OCI facing years of exponential growth, NAT Gateway has stood the test of time, successfully addressing noisy neighbor problems without unnecessary throttling.
In this blog post, we discuss how OCI’s NAT gateways solved one category of noisy neighbor problems robustly, just like a skilled moderator restoring peace and order to a disrupted meeting.
Networking NAT gateways
In the cloud environment, our customers provision Compute instances connected to the network using a virtual network interface card (VNIC). Many customers don’t want to assign public IPs to their VNICs for security reasons. Having a public IP means that internet traffic can reach your VNIC, possibly making it vulnerable to attacks. You can configure the VNIC security rules to help prevent these attacks, but customers frequently prefer to assign their VNICs only private Ips, which aren’t internet-routable, and use a NAT gateway to reach the internet.
A NAT gateway is provisioned with a single public, internet-addressable IP, which is used for all internet-bound connections. No incoming connections are permitted. It acts as a form of firewall and only allows outgoing connections, providing peace of mind to our customers.
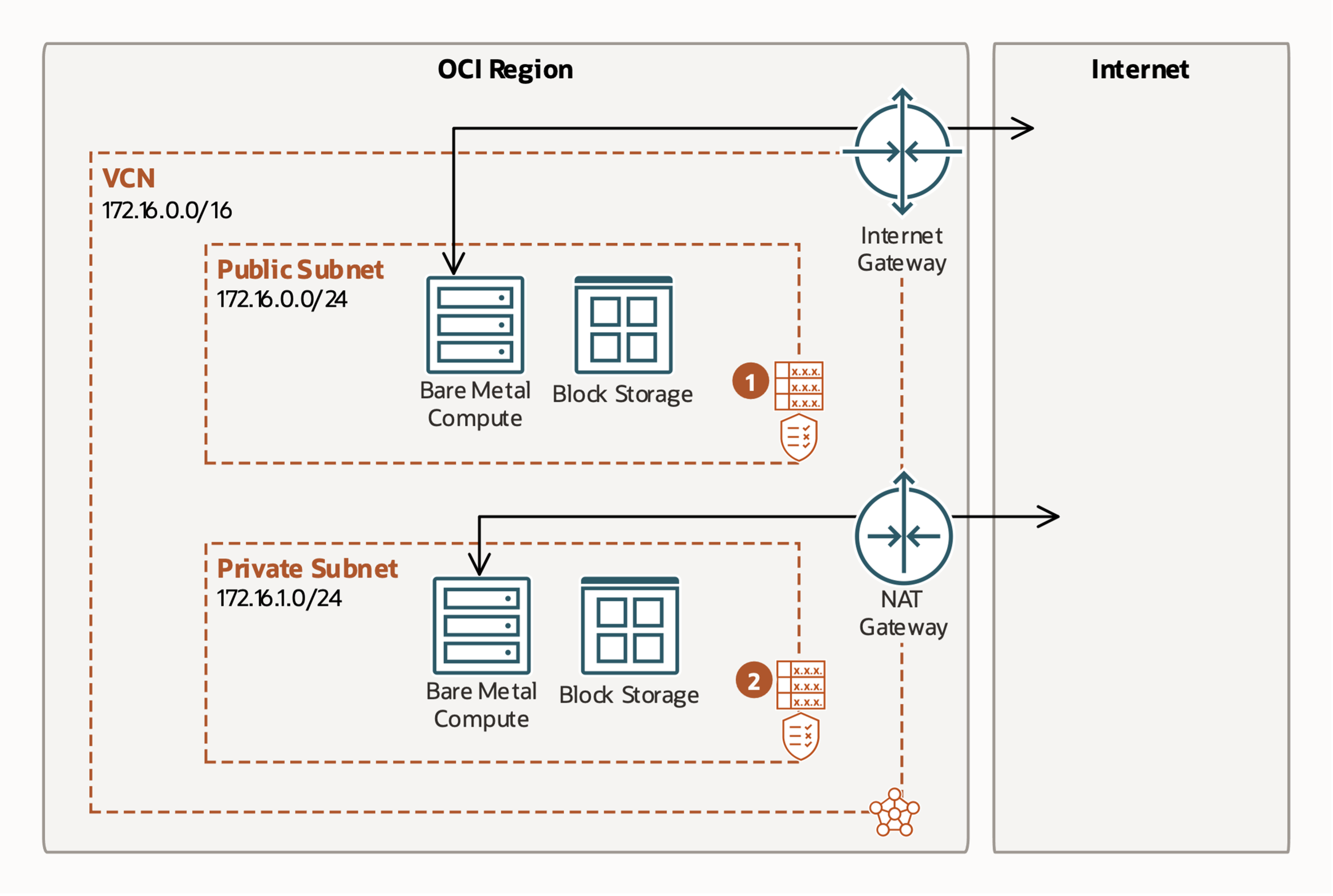
Figure 1: Customer view of internet and NAT gateways
The NAT gateway consists of several servers that all work together to accomplish two jobs: Forwarding packets and remembering connections.
Forwarding packets is the simpler part of the service. The work we do for the packet itself is local to a server, and we don’t need to have any memory of processing a packet. Our software is highly optimized, and we can route millions of packets every second.
Remembering connections is trickier because a single server isn’t sufficient. If we took that server down for maintenance, the connection would be dropped, and our customers would be unhappy. Instead, each connection is remembered by several servers. Now, if we take down one server for maintenance, the service retains a memory of the connection, and our customers are none-the-wiser. The process of telling several servers about a connection is called replication.
Replicating connections takes time and resources. As a result, we can replicate much fewer connections per second than we can process packets. A customer who’s opening lots of connections can use up all our resources dedicated to replication, becoming the noisy neighbor. The other customers might see their connections dropped, even though their load is small.
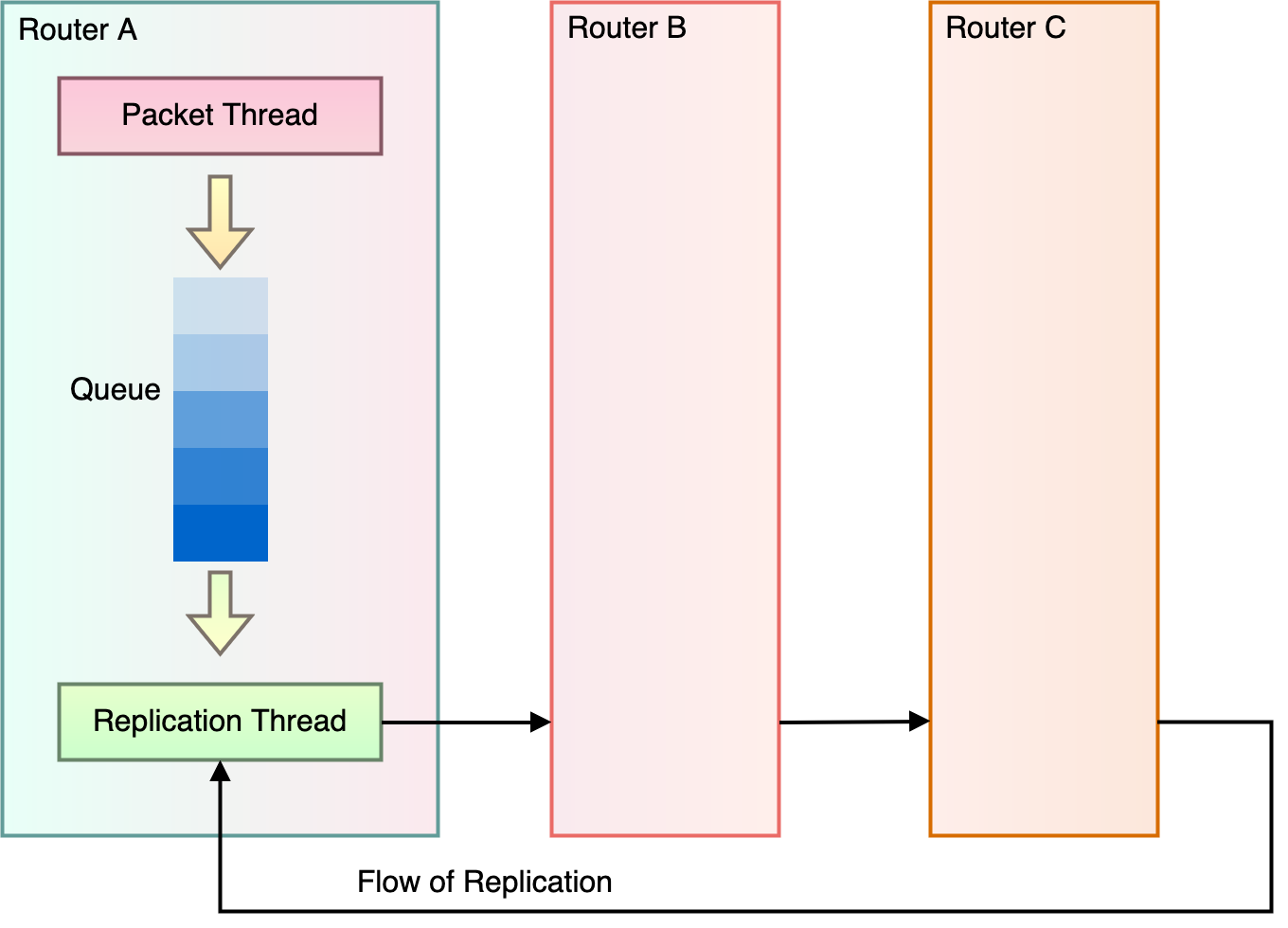
Figure 2: High-level view of NAT gateway replication
When a small subset of customers overwhelms resources of a service, the service must decide whose requests get priority and whose requests are dropped. In this scenario, even if the service architects don’t make that choice explicitly, the service chooses during the event. Without explicit throttling, customers are served on a first-come, first-served basis. Every customer might get the same percentage of their requests served, but busy customers see more throughput than mostly idle customers. As a result, the idle customers experience a noisy neighbor problem, where their experience is impacted by the busy customers, even though they’re not the ones abusing the service. This scenario is a typical failure to plan, therefore planning for failure.
OCI’s NAT gateway requirements for solving the noisy neighbor problem
When exploring solutions to noisy neighbors for NAT, we arrived at the following requirements:
- We wanted the solution to only activate when the system is busy and keep overall system load at or near 100%. This goal allows us to utilize as much of our resources as possible.
- We wanted the solution to only affect customers which are putting a large load on the system. This is the definition of avoiding noisy neighbors.
- We wanted our response time to the system becoming busy to be quick. The time between change in load and throttling response is time when customers feel the impact of their noisy neighbors. The longer the response time, the more visible the noisy neighbors become.
- We wanted the algorithm itself to be simple, local, and require very few resources. Once again, we want to utilize as much of our resources towards providing a great service. Simplicity is key to correctness and maintainability.
Traditional approaches to mitigate noisy neighbor impact
These are some of the conventional approaches typically used to reduce the impact from noisy neighbors:
- Accurate provisioning: One simple approach is assigning sufficient resources for each customer, even for their burst case. It’s like assigning seats in the meeting room, ensuring that everyone has their own space. The downside of this approach is that most customers don’t use all their resources, leading to huge amount of resource waste, much like empty seats going to waste.
- Load rebalancing: You can also move customer loads around the system to allow for high utilization of resources. Implementing such a system is difficult to do well. Imagine reshuffling seats mid-meeting to optimize the conversation flow. Tricky, right? Well, the same goes for redistributing customer loads in the cloud. Moving customers can be disruptive, and making quick global decisions about placement of customers is difficult.
- Shuffle sharding: With this approach, a customer’s load is split into many shards, and the service tries hard to avoid scheduling shards of the same two customers on more than one system. So, each customer can affect only a small portion of another customer’s experience. Think of it as dividing the meeting room into smaller groups, limiting the impact of one noisy member on the entire gathering. While this approach reduces the number of impacted customers, it doesn’t address the problem: the noisy neighbor is still noisy, and whoever shares resources with that customer is impacted and needs to be paired with another approach.
- Throttling: The age-old solution! When we find that some customers are overwhelming the resources on select systems, we can try throttling. We can measure the amount of load in the system and throttle all new requests when the load exceeds some threshold. But how many requests should we drop? Or should we try to identify the busy customers and throttle them only? How much should we throttle our customers? And how do we quickly identify the busy ones? It’s like turning down the volume on that chatty colleague, ensuring they don’t hog the spotlight. But striking the right balance is the real challenge!
Fundamentally, every solution to the noisy neighbor problem where there aren’t enough resources to handle the total load results in some sort of throttling. Throttling changes the behavior of our service. The throttled customers perceive worse service, as fewer of their requests are successfully processed.
None of the solutions listed quite hit the mark of our needs. So, we embarked on a journey to craft a throttling solution that’s quick, efficient and seamless.
Queue theory and negative feedback
When I was studying for my undergraduate degree, I took a course in system modelling. While the software we used to model systems was unwieldy, we did study some basics of Queue Theory. One interesting lesson I remember is that it is difficult to keep a queue constantly filled halfway. If the requests arrive faster than they’re consumed, the queue fills up. If the requests arrive slower than they’re consumed, the queue stays mostly empty. To keep the queue filled halfway requires that the requests are consumed at the same rate that they’re arriving.
In our NAT gateway, the arriving requests are customers trying to open new connections, and consumed requests are connections that we successfully replicate. Our service ran into trouble when customers were trying to open more new connections than we could replicate. So, the throttling question became how to select which new connections to drop so that we matched the rate of replication and dropped only connections for the noisy neighbors?
Even before solving the noisy neighbor problem, our service was already using queues to pass data between the packet processing threads and the connection replication threads. So, thinking of the problem in terms of queues had a chance of creating a solution that required little work.
Let’s use another analogy: In electronics, a simple circuit involves using a technique called negative feedback to control an amplifier. Negative feedback is a mechanism in which an observer decides that some output of a system is drifting away from the target and takes an action that counteracts the drift. The most common example of a negative feedback mechanism is a thermostat: In the winter when the air temperature drops below a set target, it turns on the heater. The heater brings the air temperature back up to the target, and the thermostat turns the heater off.
In real life, we all use negative feedback every day. If you notice that your car is drifting in your lane while driving, you steer it gently back towards the center. That’s negative feedback. The difficulty with negative feedback is that it isn’t perfect. A beginner driver might tend to understeer when they’re drifting in a lane until they cross over to the neighboring lane, or they oversteer and find themselves crossing into the lane on the other side. Even a thermostat can turn the heater off too late and cause the house to overheat, or it can turn on too late, letting the house get too cold.
I wanted to apply the negative feedback mechanism to keep our queues partially full when the system was busy. The difficulty was how to do it to satisfy all our requirements.
Adjustable token buckets per customer
In our algorithm, we use token buckets to track the rate at which each customer opens new connections. Token bucket throttling is a standard technique used in the industry. The basic idea is that a fixed-capacity bucket fills with tokens at a constant rate. When the bucket is full, the tokens stop accumulating. When a request arrives, it takes a token from the bucket. If the bucket is empty, the request is dropped.
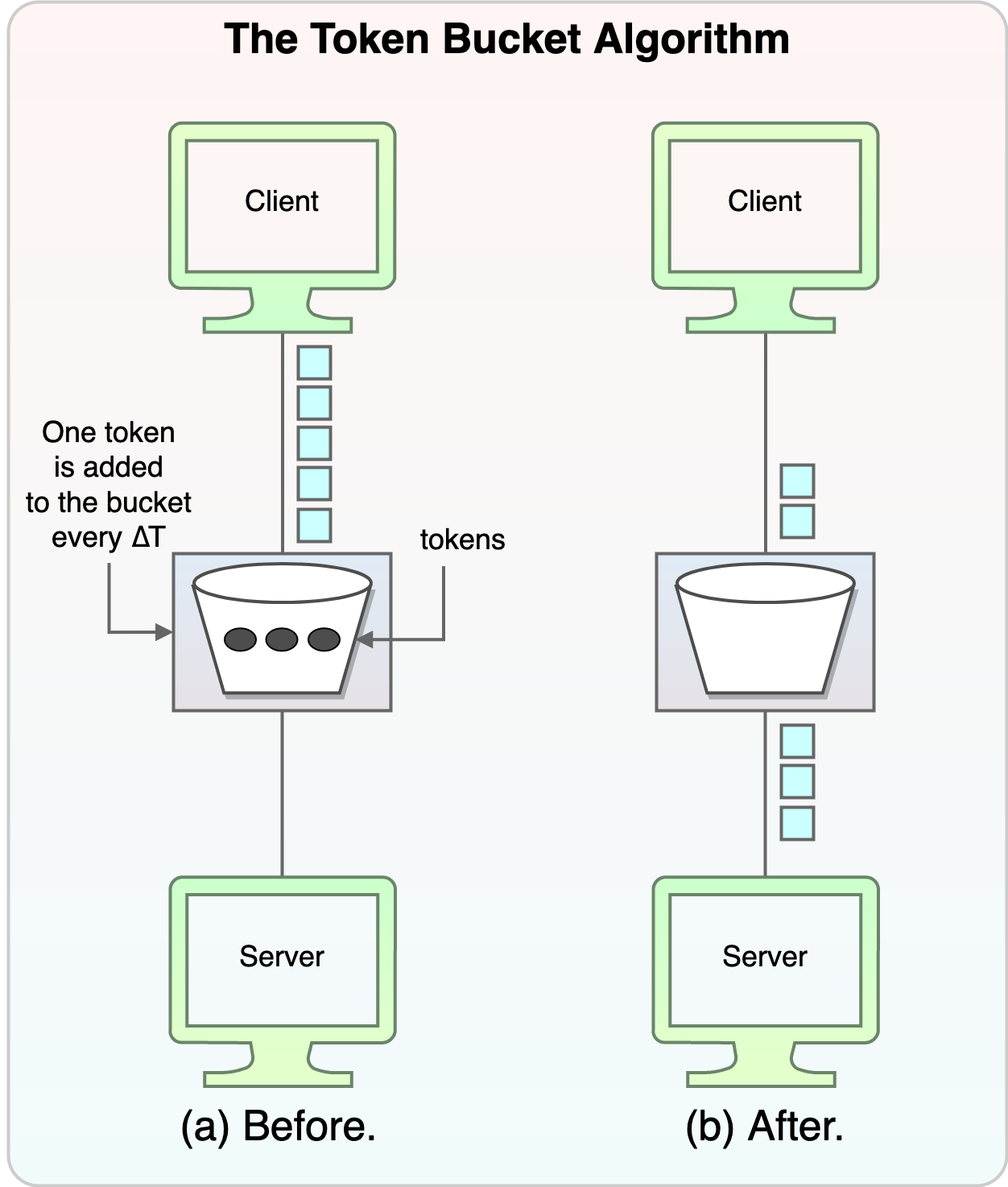
Figure 3: Token bucket algorithm
Our implementation of the token bucket is adjustable: We can change the both the capacity of the bucket and the rate at which tokens arrive. We can set these parameters—throttle rate and burst size—independently for each customer. Any customer who starts new flows faster than their throttle rate experiences some drops. In the simplest implementation, we use the same settings for all customers. So, when we need to throttle, we can throttle only the busy customers.
The second part of our algorithm requires us to pick a good rate to throttle each of our customers. If we pick a rate that’s too high, our system becomes overwhelmed. If we pick a rate that’s too low, we unnecessarily throttle customers who are opening few connections. Here, we make the decision on the throttle rate based on the depth of the queues we talked about earlier. We want to throttle each customer separately but have the combined rate of requests match exactly the rate of requests that the system can handle. Then the depth of the queue becomes constant.
In the simplest implementation, we allow the queue to fill up completely, and the queue is always full. At that point, the size of the queue mostly doesn’t matter. As long as it’s sufficiently large to accommodate short-term variations, its maximum size doesn’t contribute to the overall throughput of the system. We can set up a negative feedback loop where the fuller the queue is, the lower the throughput limit for all customers becomes. If the throttling limit is too low, the queue fill up sme more and the limit is lowered. If the throttling limit is too high, the queue empties out, and the limit is raised. The throttling level effectively controls how many entries are allowed in the queue. If the queue consistently has a few entries in it, our replication store is working at its full capacity, so the chances of oscillations or other secondary effects are low.
The remaining piece is figuring out how to convert a queue depth to a throttle. If we use a curve that monotonically decreases (moves down and to the right) and reaches 0 when the queue is full, the curve works. We recommend allowing some amount of unthrottled space in the operating region when the queue is relatively empty. This space accommodates the normal behavior of our customers with an occasional short-lived spike that doesn’t manage to fill up the queue. We also sized our queues in such a way as to allow the replication system to drain them in a fraction of a second, so we can allow them to fill up a little without our customers observing serious latency spikes.
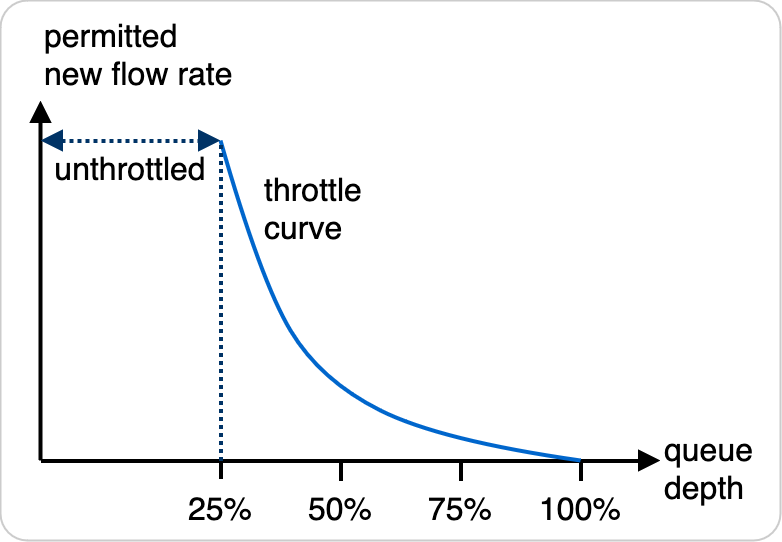
Figure 4: Example throttling response
For our final algorithm, when our routers want to replicate a new connection for NAT, they check how full their queues are. They look up the right level of per-customer throttling based on those queue levels and check whether the customer’s bucket allows the port assignment to be replicated. The throttling levels for different queue levels are precomputed at initialization time.
This algorithm works because it seeks equilibrium and uses negative feedback to find it. As long as we’re accepting new requests and putting them on the queues faster than we’re replicating them and removing them from the queues, the depth of the queues increases, and we increase our throttling. If the rates remain constant, we eventually find this equilibrium rate and the depth of the queue remains constant. If the depth of the queue decreases, we decrease throttling until we find a new equilibrium.
All the decisions in this algorithm are made locally, but it does a good job of generating throttles that keep the whole distributed system functioning well. While the decisions are local, the data used to make the decision already includes some residual information about the state of global throughput. For example, if our service loses half its throughput capacity, the queues might start filling up even though the customer behavior hasn’t changed. This behavior would continue until the system found a new equilibrium where requests are replicated at the same rate at which they are accepted. This system also demonstrates another useful property of this algorithm: its adaptability. We have deployed the same algorithm to servers with different CPU speeds and haven’t needed to make any changes to the implementation.
With this algorithm, we have been able to satisfy the following goals for throttling:
- Throttling only activates when the system is busy. If the system isn’t busy, the queues are empty, and all customers are unthrottled.
- By maintaining separate buckets for each customer and using negative feedback to set the throttle, we only throttle our busiest customers.
- Our request queues provide us with instant view into how busy the replication system is, and we check this information for every request, which means that our response to changing conditions is nearly instant.
- The algorithm is easy to understand and was easy to implement. It uses data already available locally and didn’t require adding any new dependencies or complex mechanism.
If needed, we can also assign different throttling curves for different customers with this algorithm. This way, we can categorize our customers into different levels of service and start throttling them at different points and at different rates. For example, our free tier customers might always be throttled, while our paying customers only see throttling when the queue is 75% full. This example sets up a situation where the free tier customers have noisy paying customer neighbors, but that’s a natural consequence of tiered throttling.
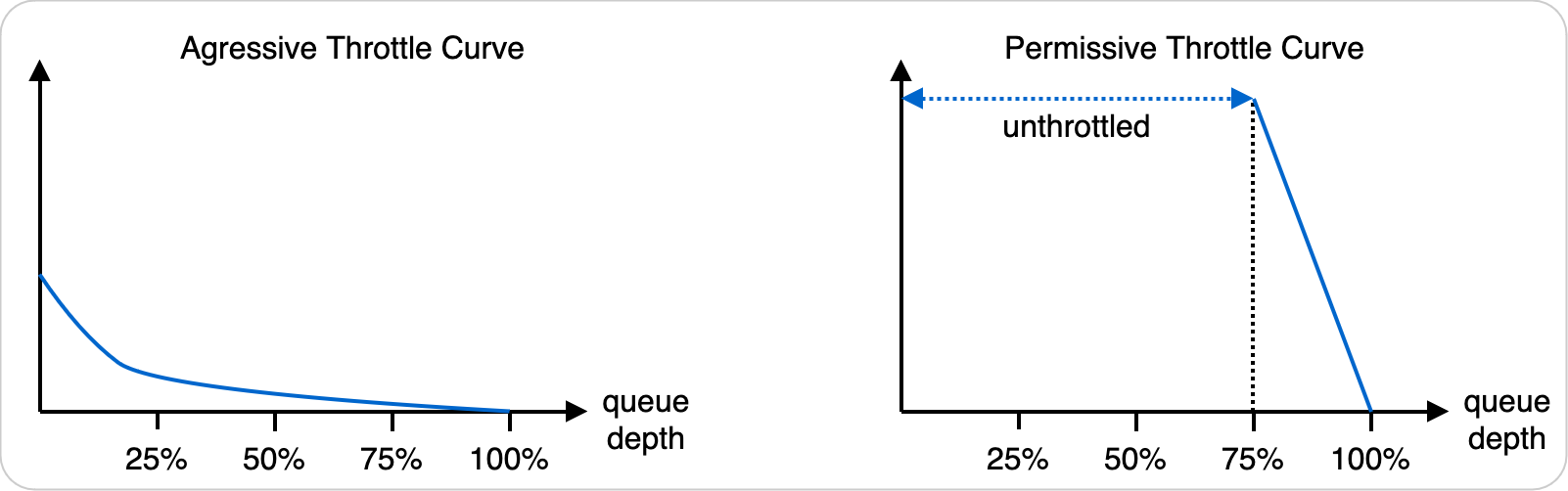
Figure 5: Examples of different throttling responses for different tiers of customers
Parallelism
Figure 5 showing our router is a little simplified. Our routers have many packet-processing threads but only a single replication thread. So, we must perform throttling not just across the fleet of our routers but also across all our threads, which isn’t much of a problem, because our algorithm is very adaptive. Each packet thread gets its own queue to the replication thread. Each packet thread does its own throttling, looking only at its own queue and measuring each customer’s throughput only for that thread. The replication thread tries to fairly replicate connections from different threads. Normally, we see queues increase evenly across the threads, meaning that each thread sets a similar level of throttling. But if a single queue starts backing up, the packet thread putting connections on it throttles down, and the replication thread is still busy, even if other queues remain mostly empty.
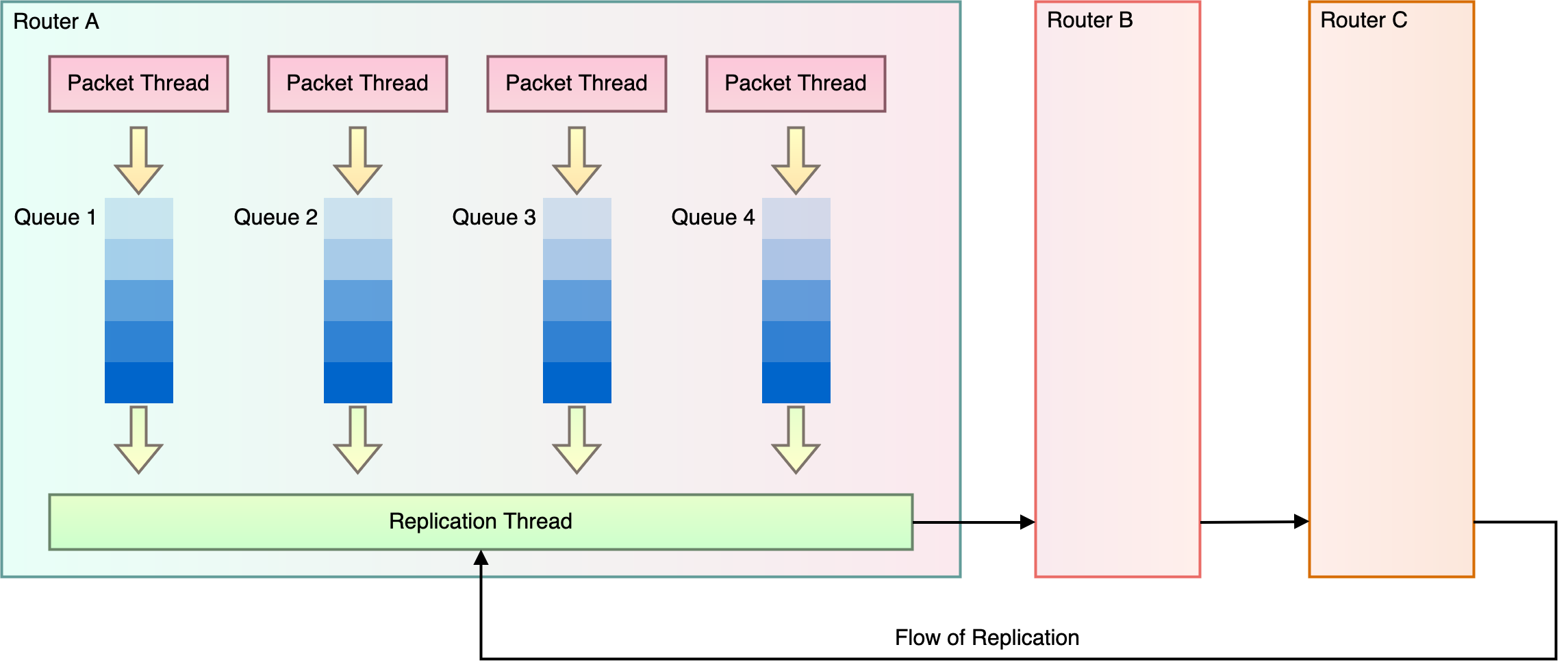
Figure 6: NAT Gateway replication with parallelism
Real-life results
A few years ago, our service experienced a huge spike in load in our busiest region. As a SME on the service I got paged. I spent a couple of minutes looking at our dashboards and realized that everything was working perfectly well and there was no cause for alarm. After some more investigation it turned out that our biggest customer had misconfigured their routing tables and instead of sending some traffic to their on-premises data center through a dynamic routing gateway (DRG), they sent it to a NAT gateway. The level of offered load was several times more than we had hardware resources to handle. While we had some alarms for unusual activity, no other customer complained about any sort of an outage.
Our throttling algorithm was the hero of the hour. While our engineers investigated the incident and our executives were figuring out who else to page to help, our algorithm instantly isolated the misconfigured customer and throttled them so they wouldn’t be a problem for the service. No widespread outage occurred, and we didn’t have to notify any other customers. Their service was never impacted.
Conclusion
In this post, we described a throttling approach that we use in one of our services to protect the customers from each other and the service from the customers by intelligently selecting customers to throttle. This approach works better than others that we have found in the industry by utilizing a negative feedback loop, which is evaluated with every request. We selected a negative feedback approach because it allows us to utilize all our resources. The cost of evaluation of our approach is very low, so we can evaluate every request against the load of the system and the throughput of the individual customer to decide if we should allow the request to proceed. This combination results in a very stable and effective throttling mechanism.
We embarked on the search for a throttling algorithm when customers in a region could experience drops because of their neighbors. Since we implemented this algorithm, we have received no legitimate complaints about drops. In fact, we survived one of our biggest customers accidentally sending a huge volume of request to our service without any our other customers noticing!
Throttling is only a solution to part of our problem. When our fleet starts to experience this throttling behavior, our operations team still needs to evaluate the traffic and decide whether we need to engage with the customer or if it’s time to add hardware resources to the service. In the meantime, the throttling prevents our service from having outages and enables all our customers to collectively utilize our resources to their fullest potential.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
For more information, see the following resources:
