In building distributed systems and tier-0 cloud services and platforms, a piece of code that’s supposed to save the day often fails spectacularly when the time comes. A classic example is the ability to recover from a data loss. You can build an elaborate system to automatically recover the data during a disaster, but it isn’t exercised until a real-life disaster happens. Critical systems or processes that are responsible for “once in a while” extreme events are often neglected or poorly tested because of lack of visibility on everyday operations. At Oracle Cloud Infrastructure (OCI), we prevent such mishaps by continuously evolving our operational best practices, release guardrails, and automation to minimize human errors.
In this blog post, we walk you through a complex change management process at OCI, the guardrails we’ve built to prevent our customers from catastrophes, and the strategies we use to keep things running smoothly. At the end, we share how these investments improved our security, availability, resiliency and developer velocity.
PKI root rotation
Like any hyperscaler, OCI is internally made up of thousands of microservices that talk to each other through a complex web of dependency chains. Every time you use one of our customer-facing products or services, you’re utilizing this immense infrastructure of connected services. To maintain our high level of security, communications between these internal services are always encrypted over the transport layer security (TLS). Our internal public key infrastructure (PKI) manages the lifecycle of TLS certificates and instance principal certificates that are available on OCI Compute instances for users to authenticate and authorize with other OCI services. PKI is responsible for renewing millions of short-lived instance principals and long-lived internal TLS certificates. We discuss a high-level overview of our digital certificate renewal process in a previous Behind the Scenes post.
These certificates are anchored to root certificates through a chain of trusted intermediate certificates. We rotate the root certificates and the chain of intermediaries in each cloud region periodically to maintain our security and compliance bar. This complicated deployment process spans across hosts, virtual machines (VMs), SmartNICs, root of trust devices and several other service targets.

Figure 1: Root rotation sequence
A small mishap in any of these steps can lead to a significant outage in that region, causing a poor customer experience. The worst part about these outages is that they can be difficult to recover from. The services required for recovery themselves might be impacted if two services can’t talk to each other because of a lack of trust. This complex process is infrequently exercised in a region but can lead to serious problems if the steps don’t work as expected.
When we started root rotations a few years ago, we intentionally spent a lot of developer cycles validating our process to minimize any risk of outages. But we’ve come a long way since then. In 2023, we rotated the root certificates in 18 cloud regions, and we have more on the roadmap for 2024 and beyond. The latest region where we rotated the roots took only 2 developer weeks to run the entire sequence without causing disruptions to our customers, compared to 12 developer months a year ago.
This transformation is a testament to how we’ve evolved our operational rigor and release automation. We’ve built software systems, guardrails, processes to exercise and rollback these steps periodically. We also continuously gather telemetry on potential customer impact to make improvements or fix regressions.
Let’s look at the details of the safety net that we’ve built to manage and sustain this ongoing process.
Framework
Building systems and processes as a stack of carefully placed invariants that support each other makes it easier to verify their effectiveness. In this case, the root rotation mechanism is built using the following release management framework:
- Practice regularly
- Minimize damage
- Target deterministically
- Expect rollback failures
- Practice rollback
- Build an operator agnostic release process
- Know your users and dependencies
- Build metrics and alarms
- Communicate with customers
Let’s highlight a few of these invariants and how we validate them consistently.
Practice regularly
Common sense suggests that periodically testing rare scenarios helps validate their effectiveness. Building and running these tests is practical if you manage a small number of services, but how do you scale that to thousands of micro services? In our example, one of the hardest steps in the root rotation process is ensuring that every service has picked up the trust bundle (root certificate authority) that contains the new root certificates. If we miss a single service, failures can cascade across the entire cloud region because the service can’t trust its dependencies that use certificates issued by the new root. Having developers build guard rails for each service in OCI isn’t practical. So, we solved this problem more generally.
We built a new realm running an entire OCI stack, called the Chaos Lab, for the purpose of practicing recovery from real world failures. Then, we started building automated recipes of disruptive events. Finally, we trigger disruptions in this region. When the region is under impact, we collect telemetry on how services fail for different kinds of disasters, answering questions such as whether services recover as expected, if they have operational visibility and alarms, and if they have recovery runbooks up to date. We continuously test the following recipes:
- Hard power failures and recovery of a full region: As services come back up, we address regressions, bootstrap cyclic dependencies, thundering herd problems, and more.
- Network outages: Our distributed systems are validated for partition tolerance during this event. We monitor for any discrepancies and automatic recovery of the region when the partition heals.
- Our own example, rotating the regional PKI root: During this exercise, we introduce a new root and forcibly renew all the existing certificates. Services are expected to dynamically load the new trust bundle and cause no impact. Regressions on services are caught by the alarms and fixed as a follow up.
In these ways, we exercise systems and processes built to handle rare scenarios across OCI and are prepared to face unfavorable outcomes.
Minimize damage
In Chaos Lab, we identified that the phase during which we forcibly renew all existing certificates had no velocity control. As a result, we ran into severe throttling from several downstream services, including load balancers to which certificates must be distributed. The storm of retrying that resulted from throttling failures dropped some of our dependencies, which further slowed down the recovery.
This area is one where we made most improvements and continue to make more progress. Having to issue certificates and certificate authority (CA) bundles across thousands of targets including hosts, SmartNICs, and load balancers require controlling the sequence and speed of distribution of artifacts. We built and deployed configurable controls in our certificate distribution service and agents to manage the area of damage. For example, we introduced a mechanism to control the speed of distribution with a configurable parameter decided based on the number of certificates needed to be issued in a region. As a result, we started with 1% of targets receiving new certificates and gradually increasing it over a period of 6–8 hours. It allowed us to watch as the certificates were redistributed and react quickly to any sign of failures.
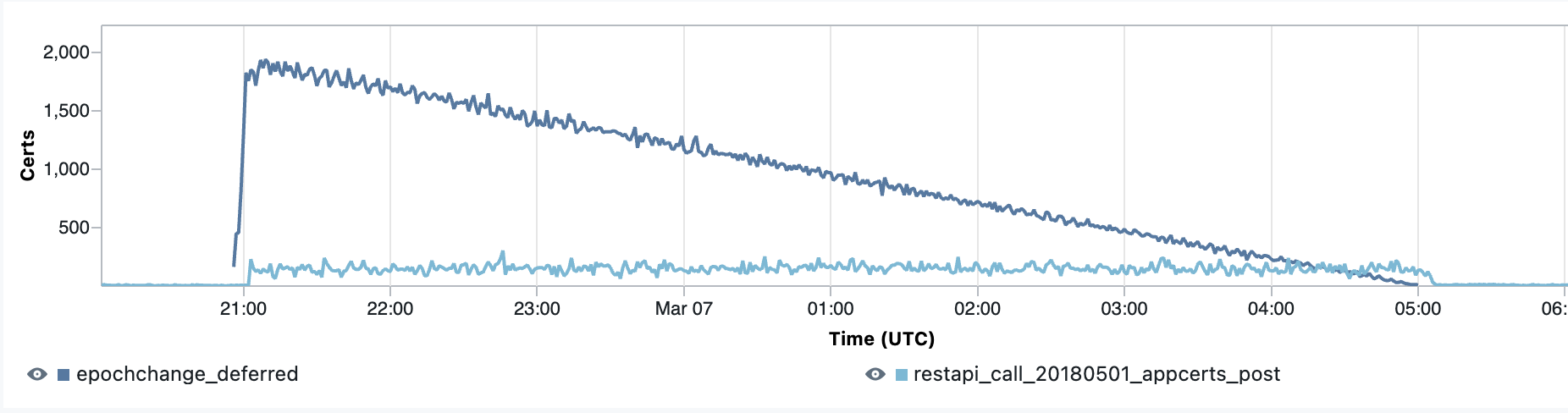
Figure 2: Certificate distribution velocity control
The higher, dark blue line shows the decline of certificate renewals, while the flatter, light blue line shows the number of certificates renewed every minute.
Target deterministically
On top of minimizing damage, we built a mechanism to introduce new roots and certificates to specific services’ targets. Because PKI is at the bottom of the OCI stack, ensuring that the platform services don’t fall apart during root rotation is critical. It can lead to cyclic dependency issues while recovering a region if a full-blown failure occurs. We emulated this scenario in Chaos Lab and discovered that specific core platform services must break the cyclic dependency during the bootstrap of a region. We then built mechanisms for the following processes:
- Release certificates to a single fleet of core services’ control and data planes, which greatly helped us answer a key question at the early stages of processing: “Which services are impacted at what time?”
- Distribute the root and dependents to one fault domain at a time across all services, which helped us narrow down the potential impact and respond to issues effectively.
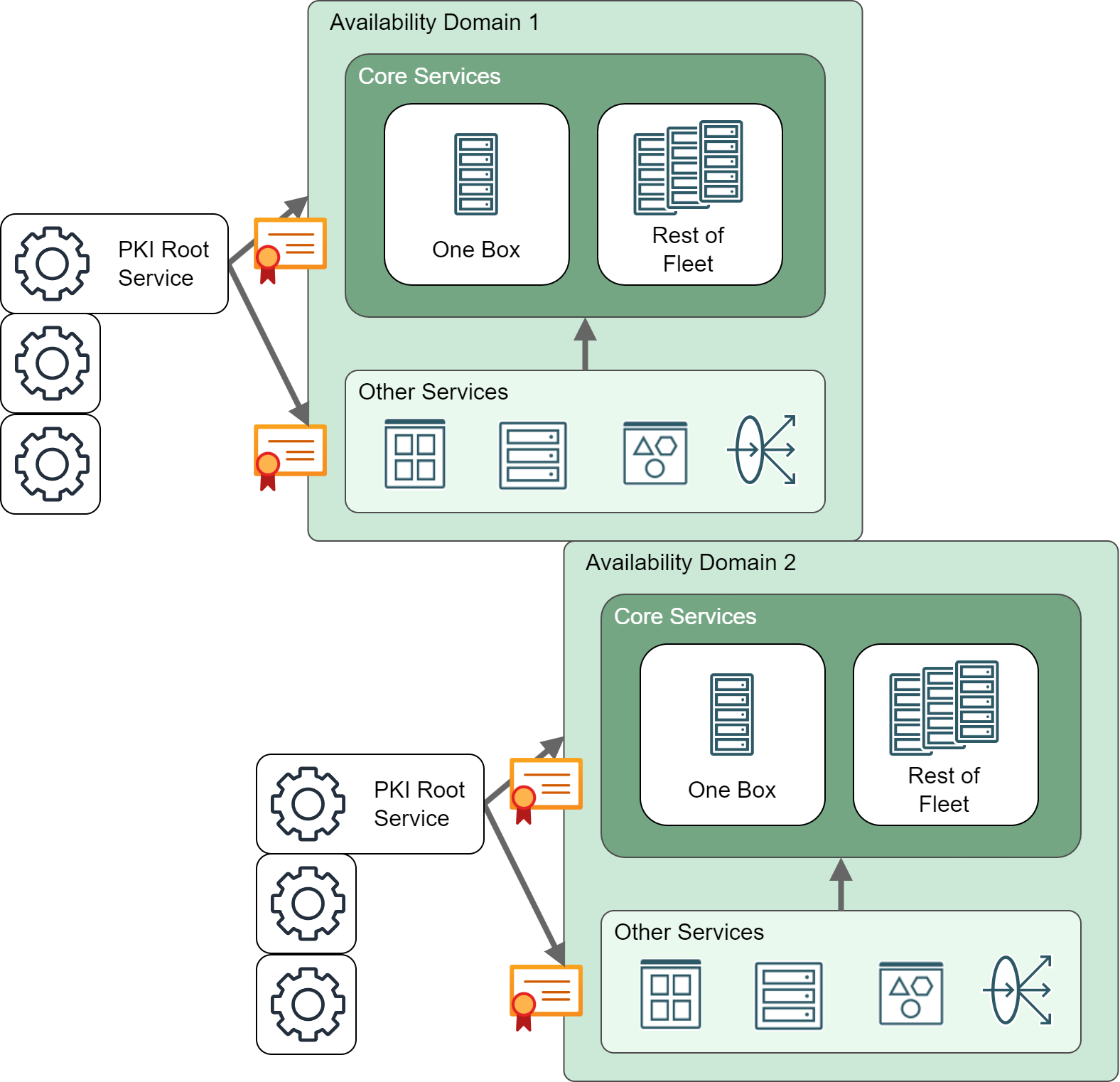
Figure 3: Deterministic distribution of certificates
Deterministically isolating impact targets helps respond to unrelated OCI-wide incidents without using a lot of developer hours on false positives. The teams can be on alert during their potential impact window.
Expect rollback failures
Change management processes often capture rollback steps with an assumption that the upstream and downstream dependencies will work as expected during rollback. For platform teams that handle PKI, assuming that everything will go wrong during root rotation and tailoring the rollback steps based on that assumption is critical. While rehearsing rollback steps in advance is easy, we took extra measures to be fully prepared to handle the most extreme failure scenarios and recover quickly, including the following examples:
- Our hardware, networking, and hypervisor teams have implemented a break glass mechanism for if the usual means to recovery are broken. This process involved taking periodic backups of configurations, host mappings, and IP addresses of hosts across the cloud region, including taking backups of runbooks, release documents, and automation scripts from code repositories.
- We operated under the assumption that our distribution mechanism for the trust bundle is broken during an outage. So, our artifact distribution platform teams implemented a mechanism to manually restore the old trust root rpm package in yum repositories. They also implemented mechanisms to bypass their core dependencies to distribute the packages across OCI, reestablishing trust between any two services if none of their dependencies are up and running.
The key point here is to untangle the complex web of dependencies, assume they aren’t available during a rollback, and come up with simple break glass mechanisms. We use the Chaos Lab to stay ahead of every change in the dependency chain and rigorously test our break glass mechanisms, helping to ensure that they’re always up to date. With OCI evolving rapidly, ongoing testing is the key to keeping our break glass processes ready to go.
Build metrics and alarms
For the root rotation process, we rely on over 100 metrics to promote the success of each step and trigger the subsequent steps in our workflow. We’ve built metrics and alarming on PKI services and client-side agents to help us understand our own failures including failures and latency on certificate delivery, certificate expirations, number of renewals, targets refreshed, host performance metrics, and so on. In Chaos Lab, we were surprised at how quickly we identified the root cause of some of the issues mentioned in previous sections. However, understanding the area of impact was extremely difficult: We had no visibility into failures across over 100 services because teams report outages in different forums. We solved this problem with an OCI-wide platform bar initiative that involved building a monitoring platform that ingests key KPI metrics from every OCI service to indicate the overall health of the cloud region at any point in time. We then integrated these live dashboards into the PKI root rotation process to actively monitor the damage and any service impact to dictate our workflows.
Conclusion
Justifying the prioritization of development efforts for something that happens so rarely is often difficult. But recognizing that some these events can make or break customer trust is important. Our investments produced the following results:
- OCI can rotate root of trust certificates safely and quickly without causing customer disruptions. This availability helps Oracle maintain the rigorous security and compliance for organizations like FedRAMP, STAR, SOC, and more in all cloud regions, especially in our government, classified and Alloy regions.
- Using the Chaos Lab, we have proactively addressed regional disaster recovery issues such as cyclic dependencies and brownouts. As a result, Oracle is able to consistently meet its service level agreements (SLAs) on service availability and durability of customer data.
- We’ve reduced the developer effort required to perform root rotations by more than 90% by implementing guard rails and automations. This control helps reduce operational overhead and improve developer velocity to deliver on customer commitments.
This blog post emphasizes the rigor with which we architect our systems and processes at OCI to help prevent outages of any size and rarity. Thousands of customers around the world rely on Oracle Cloud Infrastructure to run their businesses. We take immense pride in solving hard problems for them to uphold OCI’s strict security standards.
For more information, see the following resources:
