Introduction
Engineering advances come as a combination of innovation and optimization. Corporations who rely on on-premises IT for their simulation workloads tend to be hampered from exploring innovative advances with emerging software and hardware technologies because of the lack of quick, simple access to novel, composable high-performance computing (HPC) resources. This is particularly true for the emerging use of NVIDIA GPU -accelerated solutions, often characterized as providing high value for many HPC workflows.
PreonLab from AVL is a meshless computation fluid dynamics (CFD) package based on smooth particle hydrodynamics (SPH) that can exploit both CPU- and GPU-based systems. The use of SPH can significantly simplify use of CFD for virtual product development, particularly when element meshing is difficult. In this post, we explore the performance of PreonLab with various CPU- and NVIDIA GPU-based Oracle Cloud Infrastructure (OCI) Compute systems.
Benchmarks
We created various clusters listed in Table 1 for our benchmarks using an HPC Terraform template available on the Oracle Cloud Marketplace.
| Table 1: OCI shapes tested |
|||
| Engine shape |
Cores/node |
GPUs/node |
Total nodes per job |
| BM.Optimized3.36 |
36 |
0 |
1–8 |
| BM.Standard.E5.192 |
192 |
0 |
1 |
| BM.HPC.E5.144 |
144 |
0 |
1–8 |
| VM.GPU.A10.2 |
30 |
NVIDIA A10 Tensor Core GPU(2x) |
1 |
| BM.GPU.A10.4 |
64 |
NVIDIA A10 Tensor Core GPU(4x) |
1 |
| VM.GPU3.4 |
24 |
NVIDIA V100 Tensor Core GPU(4x) |
1 |
| BM.GPU3.8 |
52 |
NVIDIA V100 Tensor Core GPU(8x) |
1 |
| BM.GPU4.8 |
64 |
NVIDIA A100 Tensor Core GPU(8x) |
1 |
| BM.GPU.H100.8 |
112 |
NVIDIA H100 Tensor Core GPU(8x) |
1 |
We give a brief description of these shapes, and you can find a more comprehensive description in the OCI documentation. The first three systems listed are based on CPU bare metal shapes, often preferred over virtual machine (VM) shapes for HPC. We used the established OCI HPC optimized BM.Optimized3.36, with dual 3rd generation Intel Xeon Ice Lake 18-core processors, 512-GB memory, 3.2-TB NVMe with a high-speed 100-Gbps network as reference for our benchmarks. The BM.Standard.E5.192 is based on dual AMD EPYC 9J14 96-core processors with 2,304 GB of DDR5 memory. The BM.HPC.E5.144 shape is based on the same processors with 24 cores from each processor deactivated to improve the memory bandwidth per core ratio, making it more favorable for HPC workloads with 768 GM of memory. An internal 3.84-TB NVMe drive has been added for IO intensive workloads, and the nodes are networked with an ultralow latency 100-Gbps RDMA over converged Ethernet (RoCE) v2 network, critical for large multi-node HPC workloads. The last six systems listed in the table are NVIDIA GPU – based systems, both bare metal and VM shapes with varying number and type of GPU accelerators.
All benchmarks were carried out with Oracle Linux version 8 using PreonLab version v6.1.2. We used either NVIDIA CUDA Toolkit 12.2 or 12.4 depending on the system GPUs. We carried out benchmarks using four different datasets, three gear simulations of size 330K, 2M, and 33M particles, and 19M particle dip coating simulation from the PreonLab manual. We first tested the inputs on a single node of the shapes list in Table 1.
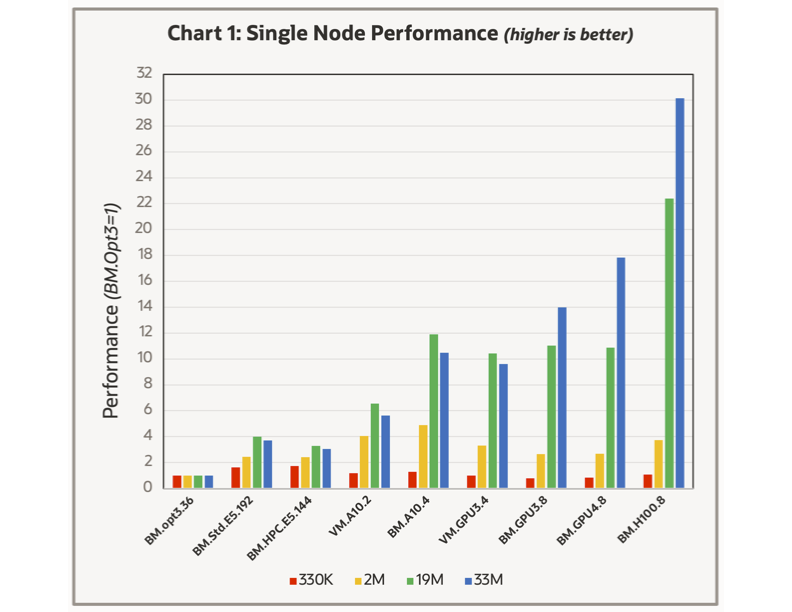
The table represents the results in terms of the system performance where the BM.Optimized3.36 was used as reference. The smallest case, 330K particles, is too small to show any appreciable difference between the various shapes. The next larger model, with 2M particles, demonstrates a greater variation but is also too small to be of high value for a performance comparison. AVL literature suggests a minimum size threshold for observing good parallel speed-up on both CPU and GPU based systems.
Our survey indicates that having 50K particles per CPU core or 5M particles per GPU for good parallel scaling. The two larger models see a substantial improvement in performance when using GPU-based systems where the number and type of GPU make a noticeable improvement. For the three 8-GPU systems, the generational improvements of the NVIDIA V100, A100, and H100 GPUs are clear.
PreonLab offers multiple levels of parallelism including MPI-based, thread-based, and GPU-based. Our testing for CPU systems indicated that within a single Compute node, having one MPI domain with a parallel thread on each core was optimal, consistent with the PreonLab manual recommendations. Multi-node MPI based benchmarks were carried on the CPU systems with RDMA networks (BM.Optimized3.36 and BM.HPC.E5.144) with results shown in Chart 2.
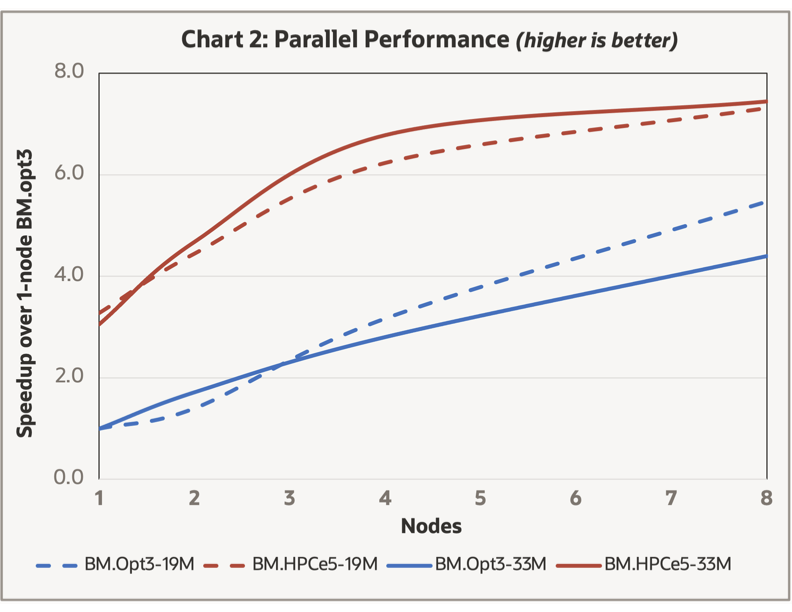
While the parallel speedup for both models on both systems increases up through eight nodes, the slope is significantly less than 1.0, and you see little benefit in speedup for the BM.HPC.E5.144 system for either model going from 4-node to 8-node, because of having 144 cores/node. The 2-node BM.HPC.E5.144 results are similar in overall performance to the 8-node BM.Optimized3.36 system (both with 288 cores). While two of the GPU based systems (BM.GPU4.8 and BM.GPU.H100.8) have high-speed RDMA networking capabilities, we carried out no multi-node benchmarks based on the 5M particle per GPU guideline.
Engineers are typically challenged to balance system performance with cost, assuming there is a cost premium running simulations faster. We explore this tradeoff for the various systems in Chart 3.
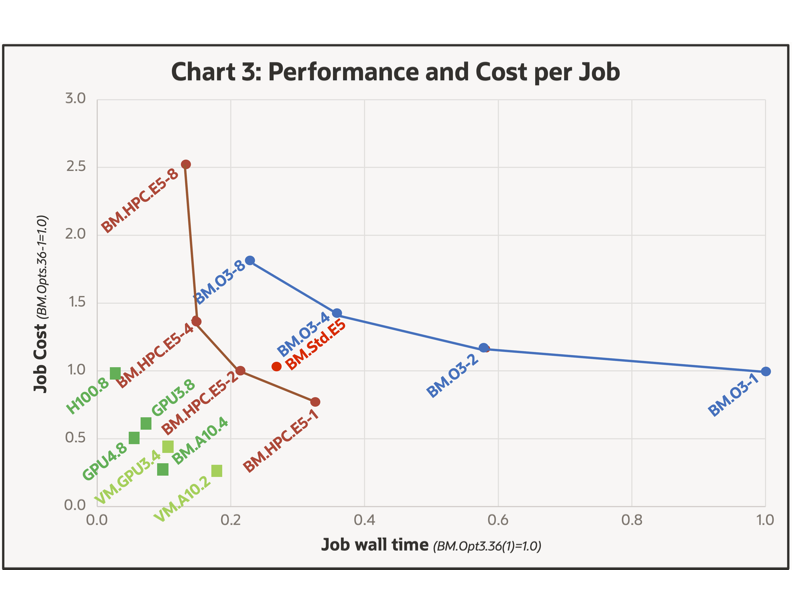
The chart represents both the job cost and the wall time to carry out the 33M job on the various systems, where the wall time is on the horizontal axis (BM.Optimized3.36 single-node=1.0). The cost per job is displayed on the vertical axis, which is based on the product of the system cost as given on the OCI website and the time to carry out the job using the single-node BM.Optimized3.36 as a reference. Here, we made no attempt to factor in other costs, such as application software and engineering time.
The trade-off between job performance and cost is likely different for different situations, making the chart difficult for categorical claims. However, results closer to the origin are superior. From the data collected, it would appear that GPU based system s are uniformly preferred over their CPU based counterparts with the BM.GPU.H100.8 (H100s) , BM.GPU4.8 (A100s) , and BM.A10.4 (A10s) shapes likely being the best solution depending on budget and simulation time constraints.
Conclusion
We found the OCI GPU shapes powered by NVIDIA to be preferable for PreonLab simulations, where the best shape is likely based on various engineering constraints. We encourage you to evaluate your PreonLab workloads at Oracle Cloud Infrastructure with a 30-day free trial. We want to thank Ryan Exell of AVL for help with this post.
For more information, see the following resources:
- Deploy high-performance computing on OCI
- Oracle Cloud Marketplace
- Low Latency Cluster Networking at OCI
- Running Applications at OCI using cluster networking
