Fluent is an industry leading computational fluid dynamics (CFD) package, developed by Ansys, that’s used world-wide on various applications. As CFD simulations grow increasingly complex and demanding, GPU-accelerated computing has become essential for enabling engineers to push the boundaries of simulation and accelerate their design processes. Since 2 023, Ansys has been releasing a CFD solver fully capable of harnessing the power of GPU -accelerated computing for mainstream CFD workloads. This blog post discusses the advantages offered by the GPU solver of Fluent 2024 R2 with NVIDIA GPUs on Oracle Cloud Infrastructure (OCI).
Benchmarks
We created various compute clusters using the HPC Terraform template, available on the Oracle Cloud Marketplace. Table 1 gives an overview of the shapes we tested. For a more comprehensive description, see the OCI documentation.
| Table 1: Compute shapes tested |
|||
| Compute shape |
CPU cores /node |
GPUs/node |
GPU Memory/GPU |
| BM.Standard.E5.192 |
192 |
0 |
— |
| VM.GPU.A10.2 |
30 |
Two NVIDIA A10 Tensor Core GPUs |
24 GB |
| BM.GPU.A10.4 |
64 |
Four NVIDIA A10 Tensor Core GPUs |
24 GB |
| BM.GPU4.8 |
64 |
Eight NVIDIA A100 Tensor Core GPUs |
40 GB |
| BM.GPU.H100.8 |
112 |
Eight NVIDIA H100 Tensor Core GPUs |
80 GB |
We obtained the benchmark datasets used in this study from Ansys, as they are well known and vary in size and complexity, and carried out the benchmarks using the script, “fluent_benchmark_gpu.py,” supplied with the Fluent release. For the performance characterization, we recorded the output of million iterative updates per second (MIUPS), where a higher value demonstrated better overall performance and faster processing time.
We carried out all benchmarks on a single dedicated compute shape with Oracle Linux 8 and Fluent 2024R2. For reference, we used the CPU based BM.Standard.E5.192, a state-of-the-art CPU based system, as noted in the blog post, Ansys Fluent performance on OCI E5 Standard Compute with 4th Gen AMD EPYC. On the CPU-based BM.Standard.E5.192, we used all cores, assigning a single MPI domain to each.
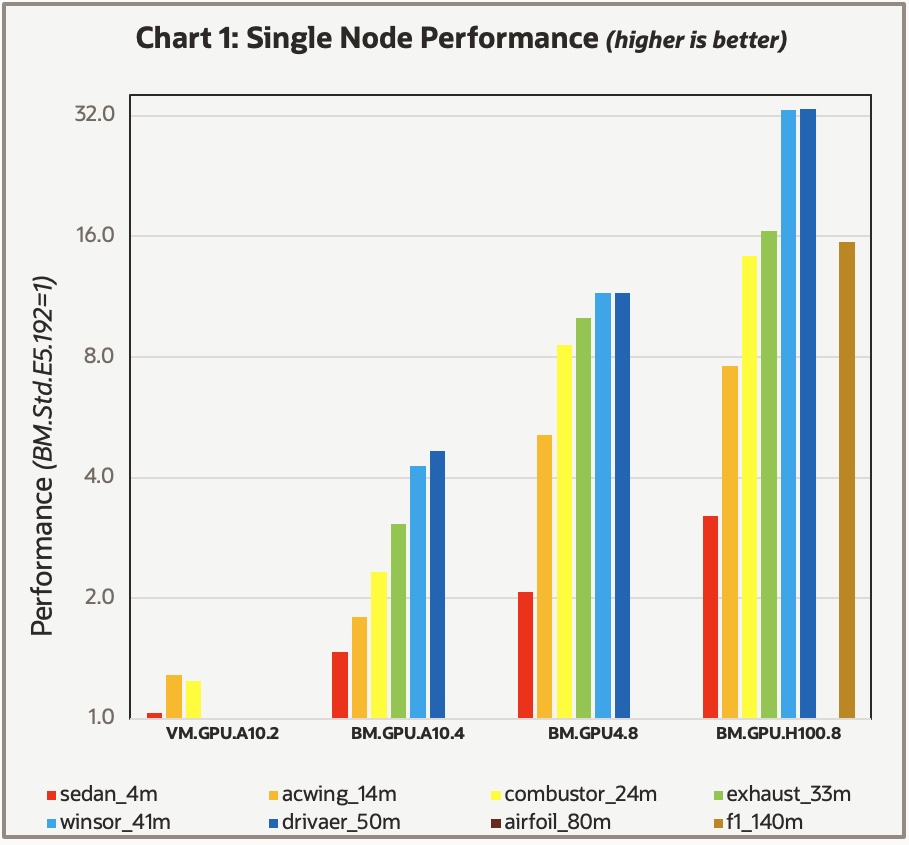
For the GPU systems, we used one MPI domain for each GPU on the system and assigned a single CPU to each domain. We tested varying the number of CPU cores per domain with the “-gpu_remap option.” However, the results weren’t consistently better using more than one core. Chart 1 shows the results, where the performance was scaled to 1.0 based on the results of the reference BM.Standard.E5.192 Compute shape. Because of the wide variation in overall performance, we used a log scale on the vertical axis.
Analysis
At first glance, several data points are missing, mainly because of the following memory size limitations on the various GPUs:
- For the VM.GPU.A10.2 shape with two NVIDIA A10 Tensor Core GPUs, each with 24 GB of memory, the largest test case that fit into the GPU memory was the combustor_24m.
- For the BM.GPU.A10.4 shape with four A10 GPUs, the largest case that fit into the GPU memory was the drivaer_50m.
- The BM.GPU4.8 shape with eight NVIDIA A100 Tensor Core GPUs, each with 40 GB of GPU memory, could accommodate models up to the airfoil_80m case. However, that case couldn’t converge with the GPU solver. We left the result in the chart to note that users might need to make some updates on their datasets to fully utilize the GPU version.
- The BM.GPU.H100.8 shape with eight NVIDIA H100 Tensor Core GPUs, each with 80 GB of GPU memory, could accommodate all the models tested.
Overall, Fluent performance on the NVIDIA GPU shapes was exceptional. While the performance of the smallest GPU shape tested, the VM.GPU.A10.2, was comparable to 20% faster than the reference BM.Standard.E5.192 shape, the published on-demand pricing for the VM.GPU.A10.2 is 40% of the CPU-based BM.Standard.E5.192 shape. With the performance factored in, that’s nearly a 3X cost savings!
The total user cost, based on both hardware and software, is likely even greater because faster run times often benefit the software license cost per job. The performance advantage and cost savings trends even better for the more powerful NVIDIA H100 GPU-based shapes. The performance achieved on a single 8- NVIDIA H100 GPU Compute shape, such as the BM.GPU.H100.8, is equivalent to a large specialized HPC cluster comprised of thousands of CPU cores.
From a useability perspective, the use of NVIDIA GPU shapes on OCI for running Fluent in production is as profound as its performance advantage. Running a large job on a single GPU shape achieves the performance equivalent to a large CPU-based HPC cluster with thousands of cores. The ability to carry out such large Fluent simulations on a single node, instead of a complex HPC cluster, vastly simplifies job scheduling and administration.
Conclusion
Our study gives Fluent users a compelling reason to investigate moving their CPU-based Fluent workloads to NVIDIA GPUs, both in terms of the potential for significant cost saving. Perhaps even more compelling is the ability to significantly improve the overall performance. We encourage Ansys users to test their Fluent workloads at Oracle Cloud Infrastructure with a 30-day free trial.
For more information, see the following resources:
