This guest blog was written in collaboration with Jason McCampbell, chief architect at Wallaroo.AI.
With a US$15.7 trillion potential contribution to the global economy by 2030 (PwC), demand for AI has never been higher. GPUs are the primary processors used to train AI models. However, when you go to deploy the inferences at scale, you want to optimize your computing resources by rightsizing your compute costs. For complex models, such as computer vision, natural language processing (NLP), deep learning recommendation model (DLRM), and large language models (LLMs) like ChatGPT, GPUs might not be the most cost-effective solution for artificial intelligence (AI) and machine learning (ML) inferencing and might be difficult to access.
For many enterprises, using lower-power and more cost-effective CPUs in conjunction with a highly optimized ML platform, such as the Oracle Cloud Infrastructure (OCI) A1 compute powered by Ampere Computing Altra Family Arm-based processors with the Wallaroo.AI Enterprise Edition ML production platform is a better alternative. This method can both lower costs and unblock projects waiting for GPUs.
The Wallaroo.AI platform runs AI and ML workloads cost-effectively using readily available, advanced CPUs. OCI A1 Compute shapes powered by Ampere Altra CPUs are the ideal hardware for AI inference optimized for performance through the set of Ampere Optimized Frameworks. Thanks to the benefits of the Wallaroo.ai platform, the extra software-derived performance gains are even larger, and the efficiently managed workloads provide more cost savings on top of already competitively priced Ampere OCI A1 instances.
Benchmarks show that using the OCI A1 compute with the optimized Wallaroo.AI and Ampere solution reduced inference time from 100 ms to 17 ms. AI teams have the flexibility of putting ML into production with multiple choices of architecture that Wallaroo.AI supports Arm-based and x86-based processors, both with and without a GPU. The Wallaroo.ai platform running on Ampere Altra cloud native processors enables shorter feedback loops and a more agile enterprise. Organizations realize faster return on investment (ROI) on their AI projects, which consume less power at a lower cost per inference.
Optimized ML Solution on Ampere CPUs
OCI A1 Compute shapes powered by Ampere Altra CPUs are the first to deliver commercially available high-compute capabilities to the cloud, thanks to their performance and density. The data shows that running the Wallaroo.AI Enterprise Edition on Ampere CPUs offers an optimized solution with fast inference and high performance, even for complex models.
OCI A1 compute makes for an ideal solution for ML deployments by maximizing performance per rack and providing unparalleled scalability. Combined with the unified Wallaroo.AI Enterprise Edition, AI teams can quickly, easily, and efficiently put ML into production.
Available for OCI clients
Engineering teams at Wallaroo.AI recently completed benchmark tests to validate a new Wallaroo.AI and Ampere optimized solution. The tests on Ampere-based A1.Flex OCI instances showed that the Wallaroo and Ampere solution delivered a six-times increase in performance over typical containerized x86 deployments on OCI. It also reduced the power required to run complex ML use cases in production.
Ampere-based A1.Flex instances available on OCI are accessible to all OCI clients, creating a high-performance, cost-effective platform. Combined with Wallaroo.AI’s purpose-built ML production platform and Rust-based inference engine, deploying production ML to OCI and Arm is now both easier and more energy efficient. This joint Wallaroo.Ai, Ampere, and OCI solution enables you to do more with less.
Benchmark test results for the solution
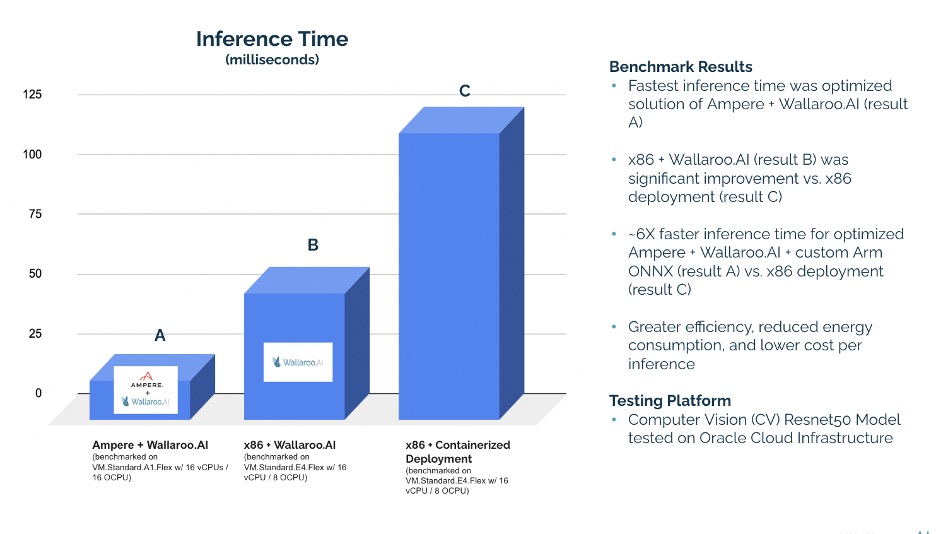
Test results on the OCI platform using the computer vision ResNet-50 model showed that the joint Wallaroo.AI and Ampere solution needed only 17 ms per inference. At large scale, this time savings mean much shorter feedback loops contributing to a more agile enterprise with the following results:
-
Running Wallaroo.AI Enterprise Edition ML production platform on Ampere Altra 64-bit A1 Flex VM on OCI + Ampere Optimized AI Framework needs only 17ms per inference (chart bar A).
-
The Wallaroo.AI ML production platform running on x86 needs 53 ms per inference (chart bar B).
-
Common ML Containerized Deployment on x86 (without Wallaroo.AI) needs >100 ms per inference (chart bar C).
The value of running ML workloads on OCI Ampere compute shapes
Because of the size and complexity AI workloads consume a lot of energy, especially on GPUs and other dedicated AI accelerators, impacting both the total cost of ownership (TCO) and the ability to achieve environmental, social, and corporate governance (ESG) goals.
One solution is to use the legacy x86-based processors. These processors seek to improve performance by scaling up the speed and sophistication of each CPU, which allows them to handle more demanding computing workloads. This complexity increases the energy requirements of the CPU and generates more heat than traditional heating, ventilating and air conditioning systems were designed to support.
In contrast, OCI Ampere A1 compute takes advantage of the principles of Arm architecture, share processing tasks on smaller more numerous cores rather than relying on a few, higher-capacity processors. This method, sometimes called scaling out, consumes less power and requires less facilities support than the scaling up characteristic of the legacy x86-based processors.
“This breakthrough Wallaroo.AI/Ampere solution running on OCI A1 allows enterprises to improve inference performance up to six times, increase energy efficiency, and balance their ML workloads across available compute resources much more effectively, all of which is critical to meeting the huge demand for AI computing resources today also while addressing the sustainability impact of the explosion in AI,” said Vid Jain, CEO at Wallaroo.AI. “At Wallaroo.AI, we’re always looking for ways to increase performance and lower costs for our customers. The next generation AmpereOne A2 instances on OCI deliver on this continued value proposition.”
“Amid today’s AI boom, customers are looking for more efficient and economical AI inferencing. With Wallaroo.AI’s migration to Ampere-based OCI A1 instances, we are providing them with a solution, bringing six times the AI inferencing performance while using significantly less money and power,” said Jeff Wittich, Chief Product Officer at Ampere. “With the next generation of AmpereOne™ A2 instances on OCI, we will continue our work with Wallaroo.AI to make high-performance AI inferencing sustainable and cost effective.”
Conclusion
Speak to an expert and see how this optimized solution can help you easily deploy and scale ML in production.
For more information on Oracle Cloud Infrastructure A1 compute, see the following resources:
