Altair Radioss is a leading structural analysis solver for highly nonlinear problems under dynamic loading used across all industries worldwide to improve the crashworthiness, safety, and manufacturability of structural designs. Oracle Cloud Infrastructure (OCI) recently released three new Compute shapes with the 4th generation AMD EPYC processor Genoa: The bare metal BM.Standard.E5.192 with 192 physical cores, the BM.HPC.E5.144 with 144 physical cores, and the virtual machine (VM) VM.Standard.E5.Flex with up to 94 physical cores. This blog post discusses the performance of Radioss on these new shapes.
Benchmarks
We created various clusters using an high-performance computing (HPC) Terraform template available on the Oracle Cloud Marketplace. Table 1 lists the Compute shapes for our benchmarks.
| Table 1: OCI shapes tested |
|||
| Engine shape |
Cores/node |
Memory/node |
Total Nodes per job |
| BM.HPC.E5.144 |
144 |
768 GB |
1–8 |
| BM.Standard.E5.192 |
192 |
2,304 GB |
1 |
| VM.Standard.E5.Flex |
92 |
384 GB |
1 |
| BM.Optimized3.36 |
36 |
512 GB |
1–8 |
The following sections give a brief description of these shapes, and you can find a comprehensive description in the documentation.
The BM.Standard.E5.192 is based on dual AMD EPYC 9J14 96-core processors with 2,304 GB of DDR5 memory. The BM.HPC.E5.144 Compute shape is based on the same processors, but 24 cores from each processor are deactivated to improve the memory bandwidth per core ratio, making it more favorable for HPC workloads, with memory sized at 768 GB for HPC workloads. Additionally, an internal 3.84-TB NVMe drive has been added for I/O intensive workloads, and the nodes are networked with an ultralow latency 100-Gbps RDMA over converged ethernet (RoCE) v2 network critical for large multinode HPC workloads. We also tested the new VM.Standard.E5.Flex Compute shape, which is flexible, allowing you to specify the number of cores and memory per node. We chose 92 cores and 384 GB memory (4 GB/core), balancing price and performance. We used the established OCI HPC optimized BM.Optimized3.36, with dual 3rd generation Intel Xeon Ice Lake 18-core processors, 512-GB memory, 3.2-TB NVMe with a high-speed 100-Gbps network as reference for our benchmarks.
In this post, we used Radioss version 2023.0 for the benchmarks. We tested three frontal-crash finite-element (FE) models: A Ford Taurus model obtained from Altair, a 2010 Toyota Yaris model obtained from NHTSA, and a 2015 Toyota Camry model obtained from the Center of Collision Safety and Analysis at George Mason University. The Taurus model contained 10M elements, the Yaris model contained 1.5M elements, and the Camry model contained 2.3M elements. We adjusted simulation times on the models to reduce benchmarking run times and measured performance in the elapsed wall clock time required to run the solver Engine.
We first tested the inputs on a single node of the shapes list in Table 1. Radioss has hybrid parallelism enabled with multiple threads per MPI domain, but for this test, we used one domain with one thread for each core, with the results shown in Chart 1.
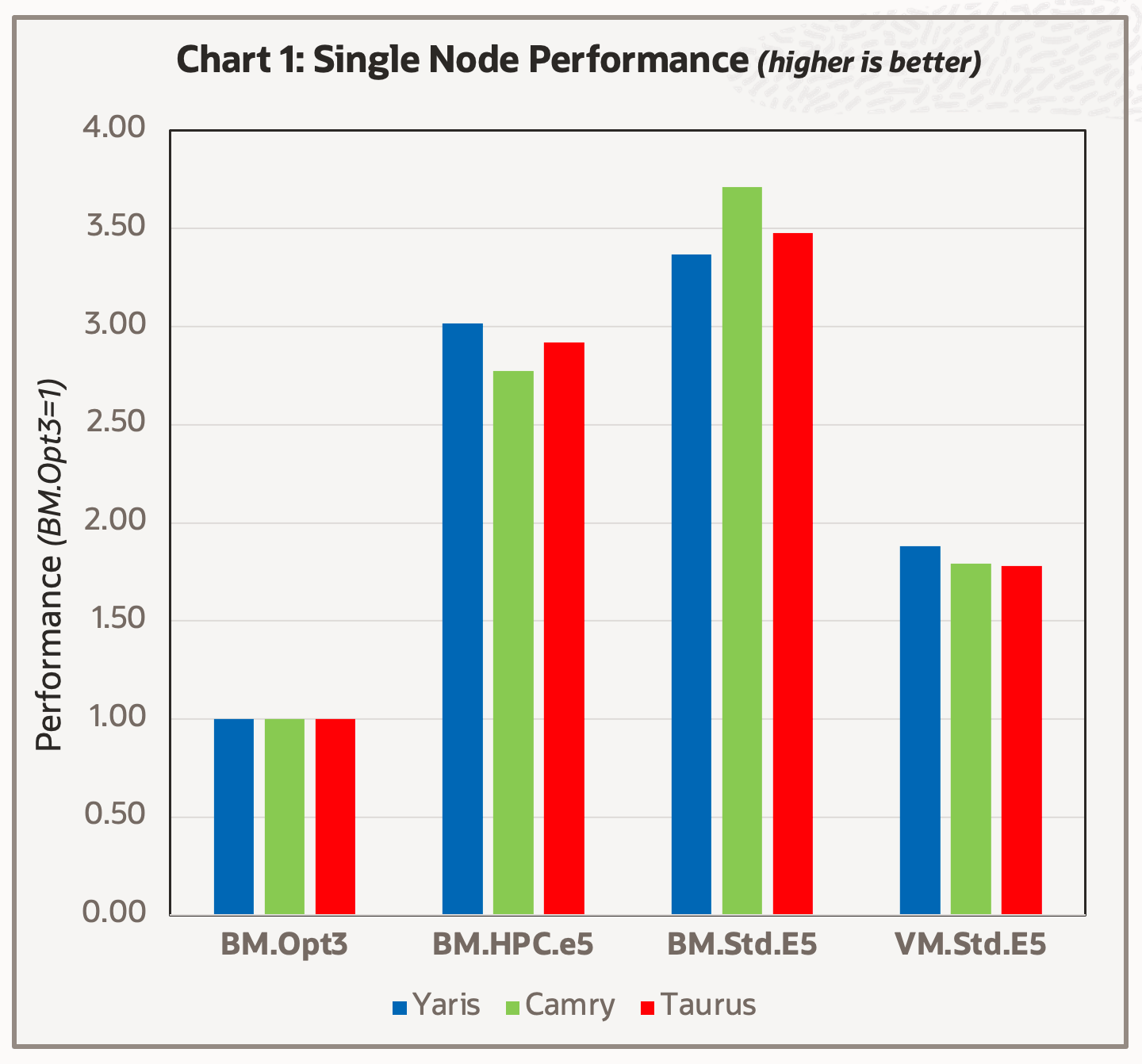
The new E5 shapes demonstrate a significant boost in single-node performance for the test cases, when compared to the reference BM.Optimized3.36. This result is expected because of the significant increase in both the total number of cores per node and the increase in the total memory bandwidth per node.
We next studied hybrid parallelism, often advantageous for larger simulations when run in parallel across multiple nodes, focusing on the largest test case, the Taurus model, using the BM.HPC.E5.144 cluster, with the results reported in Chart 2.
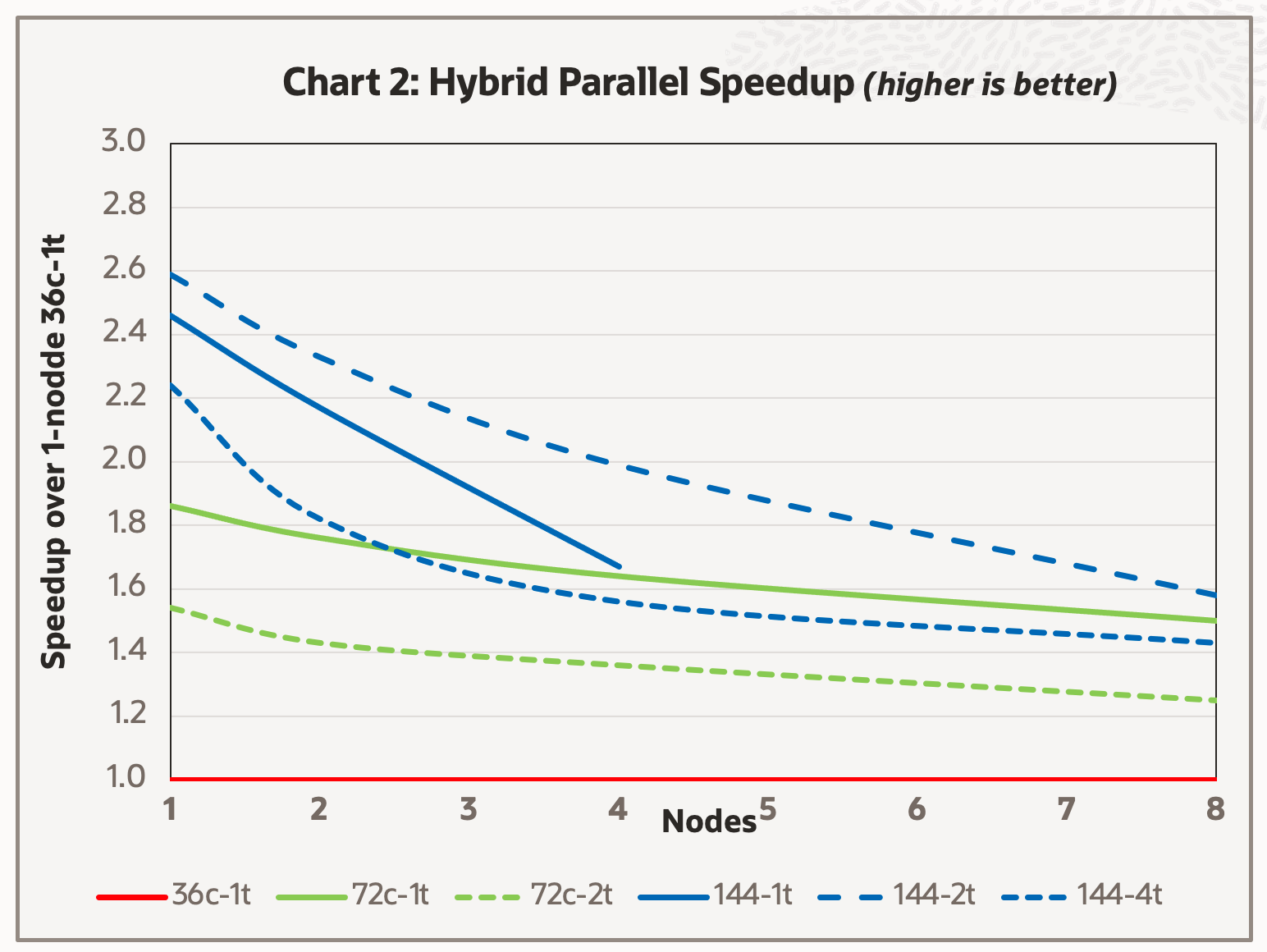
We started with a baseline of using 36 cores per node with 36 domains (each with one thread), using from 1–8 nodes (shown as a solid red line). Next, we doubled the number of cores per node, either by increasing the number of one-thread domains to 72 or doubling the number of threads in each of the 36 domains to two threads (shown as green lines). Ideally, the speedup from 36 core to 72 cores should be twice as fast, but both green lines fall below that speed. The speedup was better from doubling the domains over doubling the threads per domain. Finally, we tested using all 144 cores per node with various domains using one, two, and four threads per domain (shown as blue lines).
The test had insufficient memory to run on all eight nodes using 144 domains per node. The incremental improvement over 72 cores was significantly less than the improvement from 72-cores over 36-cores. Using two threads per domain was the best over the entire range, but the slopes indicate that at a certain node count, four thread per domain is preferred over two threads. These crossover points are expected to be model dependent. However, all the cores using two threads per domain are generally safe choices for optimal performance.
Our experience has been use of high-speed RDMA networks is required to obtain consistently good performance for parallel runs with more than 2–4 nodes. We compared the hybrid parallel performance of the input cases with the two RDMA network-based BM.Optimized3.36 and BM.Standard.E5.144 shapes. We reported the performance with the best hybrid-parallel combination obtained at each data point in Chart 3, using the single-node BM.Optimized3.36 performance as reference.
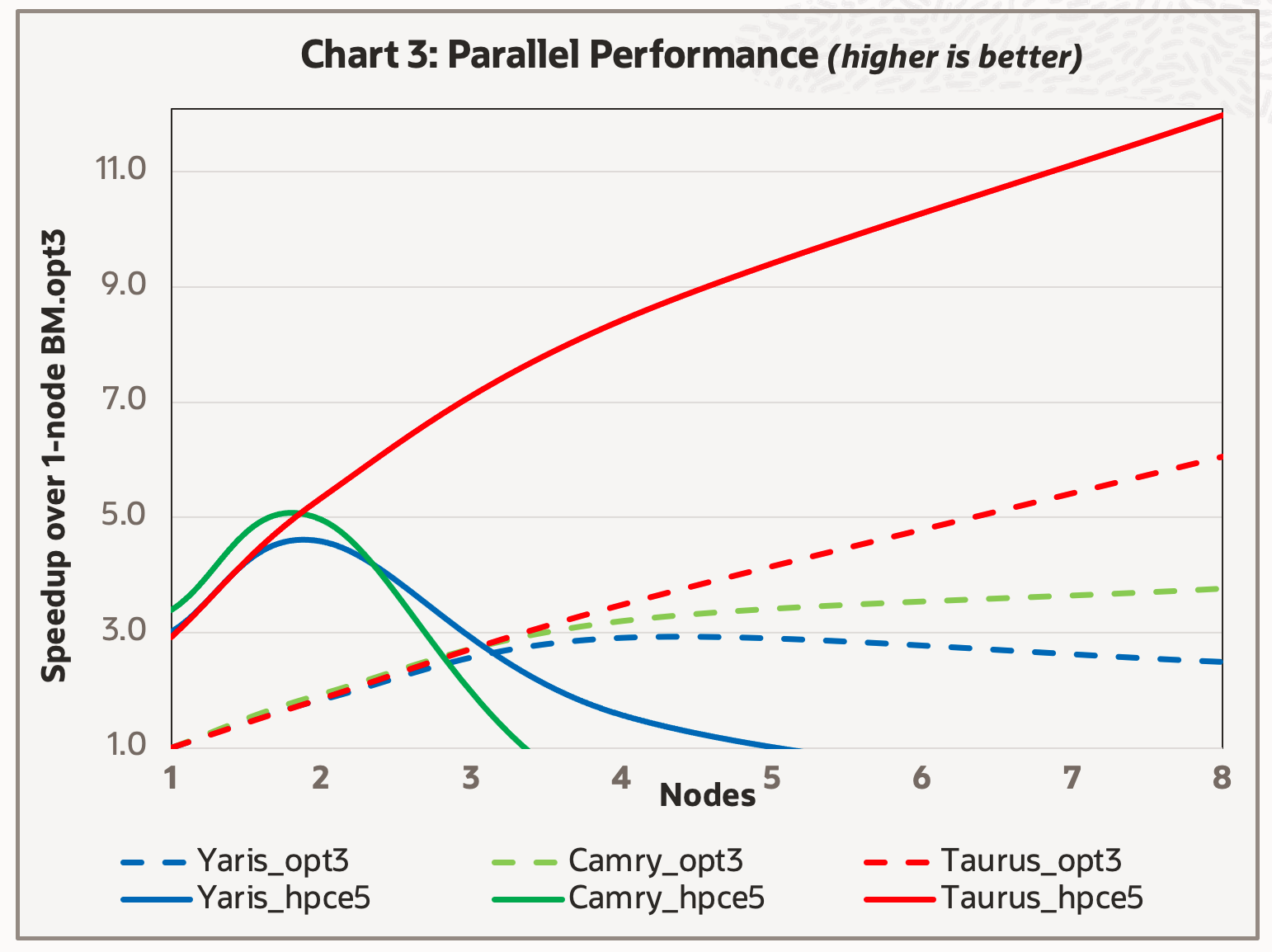
As seen in Chart 1, the single node results for the BM.HPC.E5.144 node are three times faster than the reference system. Overall, the BM.Optimized3.36 shape offers good parallel speedup up to four nodes for all three cases and good parallel speedup up eight nodes on the largest Taurus model, whereas the BM.HPC.E5.144 offers good parallel speedup to eight nodes on the Taurus model and up to two nodes on the two smaller models. However, the BM.HPC.E5.144 nodes are so powerful that the two node jobs offered excellent overall turnaround times, better than those obtained on the eight-node BM.Optimized3.36 cluster.
Conclusion
We found the new OCI AMD Genoa-based shapes well-suited for use with Altair Radioss, with the BM.HPC.E5.144 best where multinode parallel performance is crucial. While no hard and fast rules for optimal hybrid-parallel tuning exist, keeping the total number of domains below 200 for all but the largest simulations appears reasonable.
We encourage you to evaluate their Radioss workloads using either the commercial version tested in this post or OpenRadioss, the freely available open source version from openradioss.org on the new AMD Genoa-based shapes at Oracle Cloud Infrastructure with a 30-day free trial.
