The authors want to thank Larry Wong for his contributions to this blog.
Over time, technology has steadily advanced in the healthcare industry, and the sector has come a long way from maintaining rooms upon rooms full of actual paper-based medical documents and patient information to storing data in digital format across multiple clouds. Cutting-edge technologies are in play to improve healthcare for patients and hospitals, and clinics can run a more streamlined, effective business. Still, we still have a long way to go to embrace technologies like artificial intelligence (AI) and machine learning (ML) to truly transform the patient experience and reduce the burden on healthcare professionals.
One of the common practices in healthcare is that physicians create audio recordings immediately after patients’ office visits to quickly capture diagnostic information and treatment plans. The recordings are collected at the end of the day by the central IT of their affiliations to transcribe into text documents and upload to patients’ electronic healthcare records (EHR). The central IT can collect thousands of these audio recordings each day if a hospital employs hundreds of physicians. Transcribing these audio recordings quickly and accurately to text is a challenge.
Oracle and NVIDIA recently teamed together to tackle this challenge with an AI-powered medical transcription implementation by utilizing NVIDIA Riva speech and translation AI software tool kit on Oracle Cloud Infrastructure (OCI) Container Engine for Kubernetes (OKE). In this blog, we discuss how to launch the implementation in a public cloud and effectively apply it to transcribe healthcare domain-specific audio recordings for EHR documentation.
What is NVIDIA Riva for EHR transcription?
Many audio-to-text transcription solutions are available today. NVIDIA Riva distinguishes itself as a GPU-accelerated speech AI software development kit (SDK) that delivers superior performance in both real-time and batch job throughput processing modes. It also enables users to build and deploy fully customizable, real-time AI pipelines that deliver higher accuracy using fine-tuning techniques such as keyword boosting, speech hints, and domain-specific vocabulary enhancement, as illustrated in Figure 1.
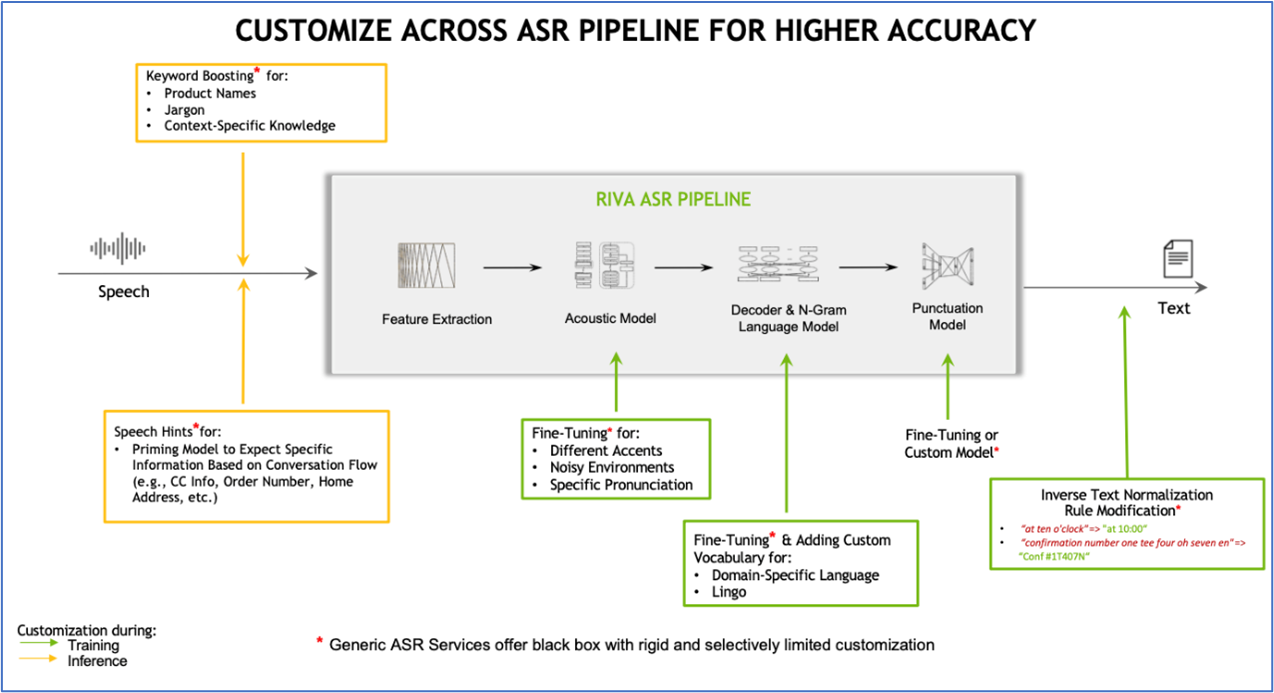
Figure 1. NVIDIA Riva Speak AI SDK architecture. Core Riva ASR pipeline is presented in the shaded box, and customizable and fine-tuning options are highlighted in green and yellow boxes.
NVIDIA Riva is designed to deliver world-class speech AI skills in automatic speech recognition (ASR), text-to-speech (TTS) conversion, and neural machine translation (NMT) applications. Riva offers out-of-the-box, state-of-the-art speech models that are trained on thousands of hours of audio data. The ASR and TTS pipelines are optimized for real-time performance with inference running far better than the natural conversation interactive response threshold of 300 milliseconds. Riva’s GPU acceleration provides seven-times higher throughput than CPU-based applications, and it can easily scale to hundreds and thousands of streams in both real-time and offline batch modes.
Provision OKE as the platform for NVIDIA Riva
NVIDIA Riva is available to members of the NVIDIA Developer Program as containers and pretrained models in a free 90-day trial on the NVIDIA NGC catalog. We utilized OCI-managed OKE to build our cloud-based EHR medical transcription solution. OKE is OCI’s managed Kubernetes service and an excellent choice because it efficiently manages enterprise-grade Kubernetes on a large scale, resulting in significant reductions in time, cost, and resource requirements for managing the Kubernetes infrastructure.
OKE offers flexible configuration options for the worker nodes, enabling us to fine-tune the allocation of CPUs and memory for our worker nodes. It also allows various shapes for worker nodes with different hardware to meet different workload requirements, allowing us to equip our worker nodes with NVIDIA GPUs, which is a requirement for the Riva application.
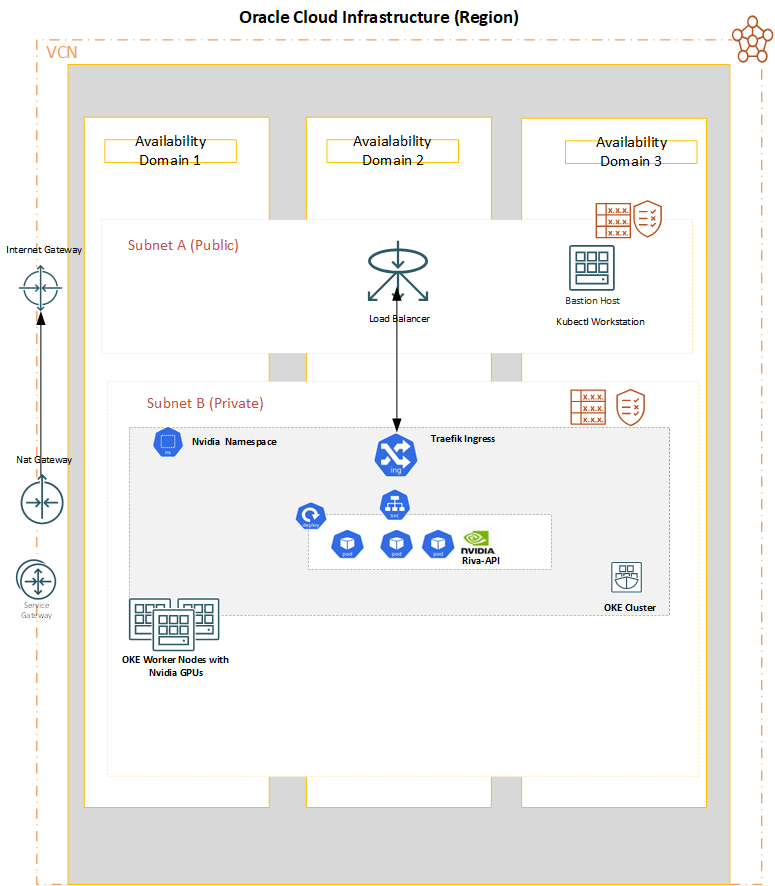
Figure 2. The OKE Kubernetes solution deployed for the EHR medical transcription solution
The solution uses the following OCI components:
-
Bastion host (kubectl workstation)
-
An OKE cluster with three worker nodes configured with NVIDIA GPU cards
-
OCI load balancer
-
OCI Object Storage
The solution uses the following Kubernetes resources:
-
Traefik ingress
-
Riva-API deployment
-
Riva-API service
The Kubernetes cluster comprises three worker nodes utilizing the VM.GPU.A10.2 shape. Each worker node is furnished with dual NVIDIA A10 GPU processors, accompanied by 30 2.6 GHz Intel Xeon Platinum 8358 (Ice Lake) processors and 480 GB of memory. The deployment also includes a bastion host with Kubectl installed for accessing the OKE cluster.
In the OKE cluster, the NVIDIA Riva SDK is in a deployment consisting of three pods. A service for the NVIDIA Riva SDK deployment is configured to provide access to the pods with a Traefik ingress that maps to an OCI load balancer to facilitate external access to the Riva SDK.
To emulate real-world usage scenarios, the OKE Kubernetes solution incorporates object storage to store the audio files to be converted and the resulting EHR text files. Moreover, the solution encompasses the OCI Streaming service, which transfers these files between OCI Object Storage and the OKE cluster.
Let’s test our solution
To evaluate the outcome and performance of our solution, we selected several Youtube videos and extracted the auto portions as our test audio files. These files are recorded discussions between physicians on heart surgeries for patients with Aortic Valve disease. Such healthcare-specific contents are beyond the coverage of the built-in generic voice-to-text transcription model in the pretrained Riva package, but they’re perfect in testing and demonstrating the customization features offered by NVIDIA Riva.
We evaluated the following customizable accuracy improvement options supported by NVIDIA Riva: Keyword boosting, speech hint, and custom vocabulary. We created a keyword-boosting file in which physicians’ first and last names were spelled out, and we also created a custom vocabulary file in which the specific medical words for heart surgeries were spelled out. These files were fed to the pretrained Riva models through runtime option flags—a painless effort.
In Riva output files, we observed the correct appearances of these physician names and medical words. This output represented a significant improvement compared to the text transcriptions generated without these customization options. To our surprise, we observed almost no increase in job processing time when we turned on these customization options.
To evaluate a large batch workload processing capability, we replicated these audio files multiple times to create up to 60 data streams, and we processed these streams on each worker node. This evaluation test demonstrated the strong throughput performance of our solution, as reported in Figure 3. We can use the results of this evaluation to guide the speech AI cluster sizing exercise for future customers.
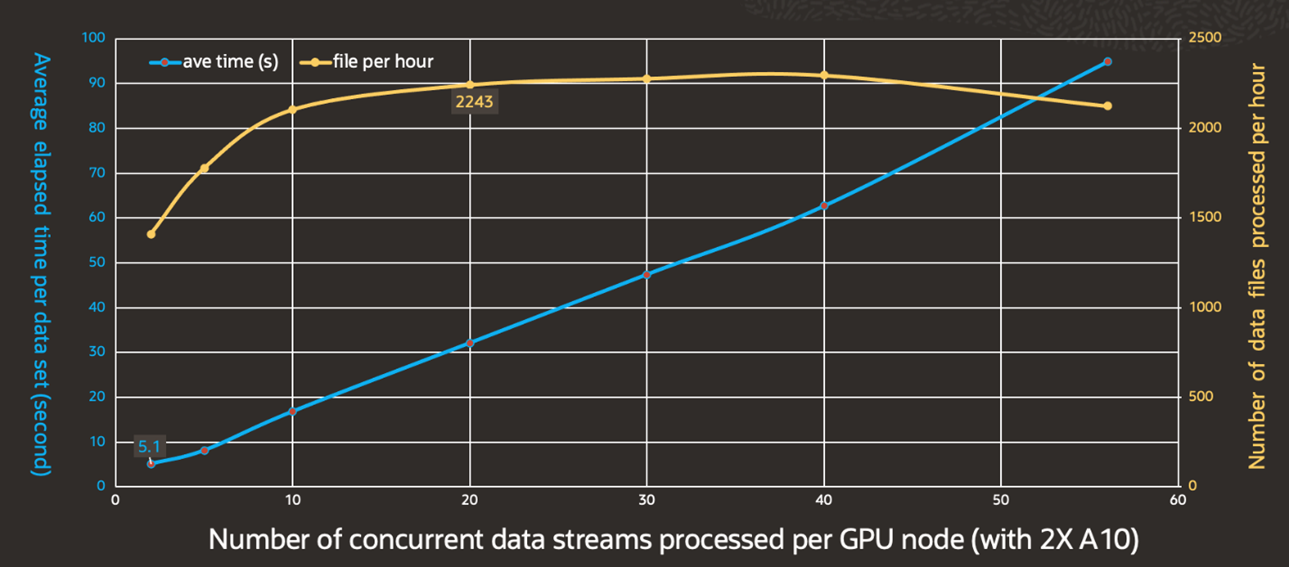
Figure 3. Throughput capability measurement
Up to 60 audio data streams were created and submitted to each worker node for batch processing with 30 steams per GPU card in the node. While the average elapsed time per data set increased with the increase of data streams per node, the throughput capability stabilized at about 2250 data sets per hour when data stream numbered greater than or equal to 20.
Summary
OCI recently collaborated with NVIDIA to tackle a common healthcare challenge of transcribing physician’s audio recordings to EHR document. Our solution was an integration of NVIDIA Riva, a GPU-accelerated speech AI SDK, and OKE, an OCI-managed Kubernetes engine. It enabled users to quickly and accurately handle healthcare specific voice-to-text transcription workload in both real time and batch processing modes, benefiting from both the latest GPU shapes offered by Oracle Cloud Infrastructure and the built-in customizable accuracy enhancement features offered by NVIDIA Riva.
For more information, see the following resources:
Join us at CloudWorld! Talk to Oracle experts who can help solve your challenges and experience a sample of Oracle’s comprehensive portfolio of AI capabilities at the AI Pavilion in the CloudWorld Hub. Through OCI, Oracle applications, and Oracle’s partner ecosystem, you will find solutions and services that can help with your AI journey, regardless of your starting point and what your objectives are.


