In this blog post, we showcase how to create advanced logic in your Terraform code using Oracle Resource Manager stacks. The examples for this blog are the Quick Start stack for Data Lakehouse and the Quick Start stack for Apache Airflow on Oracle Container Engine for Kubernetes (OKE).
Resource Manager stack schema
Oracle Resource Manager is a free, fully managed Oracle Cloud Infrastructure (OCI) service that provides Terraform stack support to help you install, configure, and manage resources through the infrastructure-as-code (IaC) model. The first thing to understand about Oracle Resource Manager stacks is that they use a schema overlay for the underlying Terraform code. This schema allows for abstraction of variable selection using the Oracle Cloud Console interface. The schema also supports some extremely powerful dynamic integrations within OCI, providing a streamlined mechanism to expose lists of available values within your tenancy, including the following examples:
- Region selection
- Compartment ID
- Core image selection
- Compute shape selection
- VCN selection
- Subnet selection
- Availability domain selection
- Fault domain selection
- Database system selection
- Database system home folder
- Database system ID selection
- Autonomous database ID selection
On top of these dynamic integrations, the schema also supports Boolean logic for visibility to show and hide individual variables or variable groups. This functionality allows for advanced workflow logic to be built into the schema overlay.
Data lakehouse stack overview
The data lakehouse stack facilitates deployment of data lakehouse components, either individually or in bulk. It also has all the underlying prerequisites included to support components, such as virtual cloud network (VCN) and subnet creation and Identity and Access Management (IAM) policy.
Let’s start by looking at the architecture diagram:
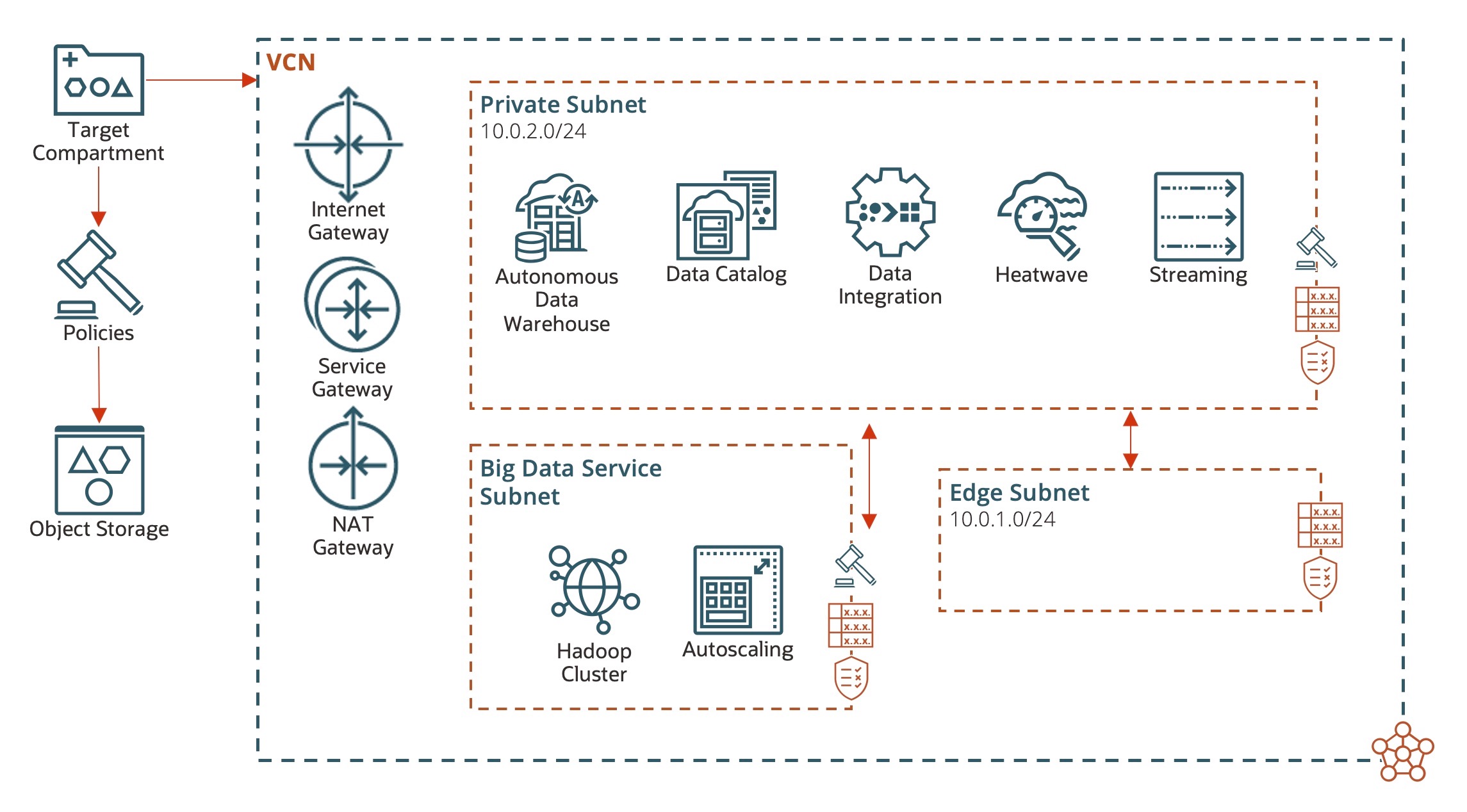
This diagram shows that the resources are created in a target compartment. You can create or select a VCN and relevant subnets for each service, and the corresponding OCI services are available as part of the deployment automation. The following figure shows a visualization of this repo:
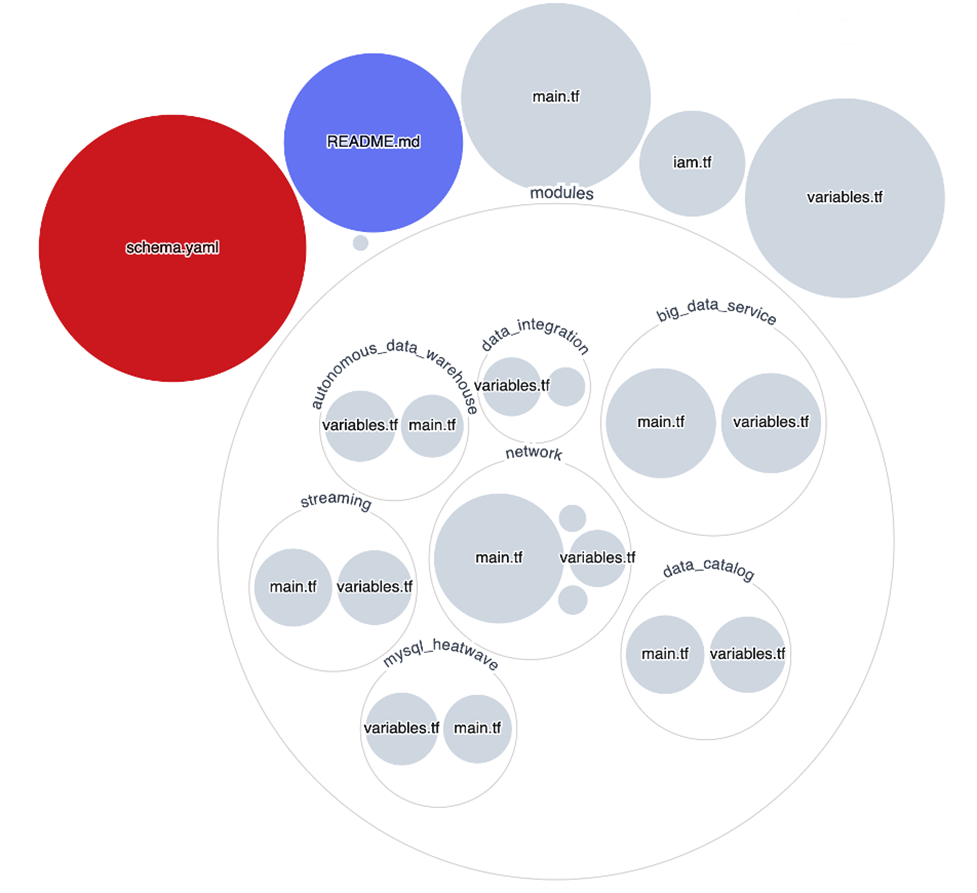
At the top level are the core Terraform components in the file, variables.tf, which contains all the variables needed for the stack, iam.tf, which contains IAM policy, and main.tf, which has the core Terraform code for deploying each module. The file, schema.yaml, is an overlay to this underlying Terraform. Any variable that must be part of the user workflow must be included there. Any variables that are static or shouldn’t be part of the workflow can be hidden in the schema. The schema should sit in the top level directory for Oracle Resource Manager to pick it up.
Each module in the template is self-contained and at a minimum, consists of a main.tf (core) and supporting variables.tf. Variables are passed into the module from the top level, main.tf. Modules are turned on and off using the Terraform count parameter, which is supported by a Boolean conditional set in the schema. If the Boolean is false, then the count is 0 and the module isn’t built. Otherwise, if it’s true, the module count is set to 1 and the module is built. The schema overwrite variable parameters in variables.tf, but you can include defaults in both places. The defaults at the variables.tf level are used at the Terraform level for sanity checking, and the ones set in the schema are the defaults that appear in the UI. These default values don’t need to be consistent between schema.yaml and variables.tf, knowing that schema takes precedence.
Schema variables and visibility
The schema can toggle visibility of variables and variable groups in the console UI. When the data lakehouse stack is loaded in for the first time—by default—the only components that are turned on are the required prerequisites, including IAM policy, VCN, and subnets.
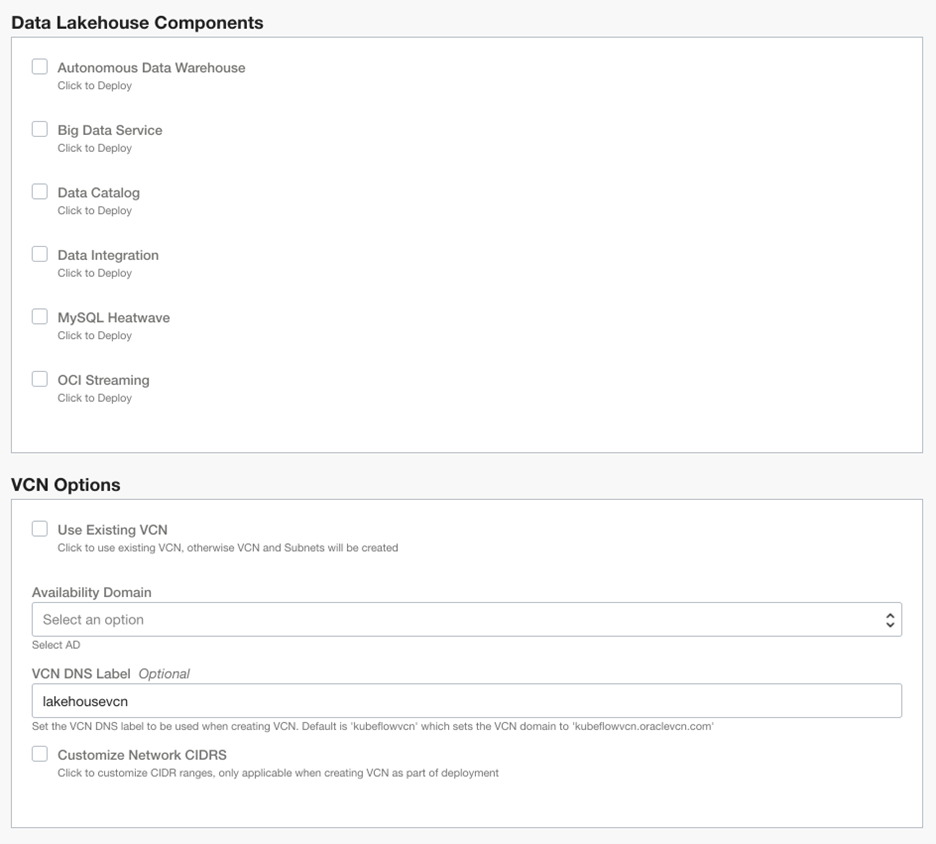
In the UI, the data lakehouse components variable group has all modules turned off by default. The VCN Options section includes a Boolean for using an existing VCN, availability domain selector, and some more customization options for the VCN. To support these sections, the schema.yaml code gives you the following output:
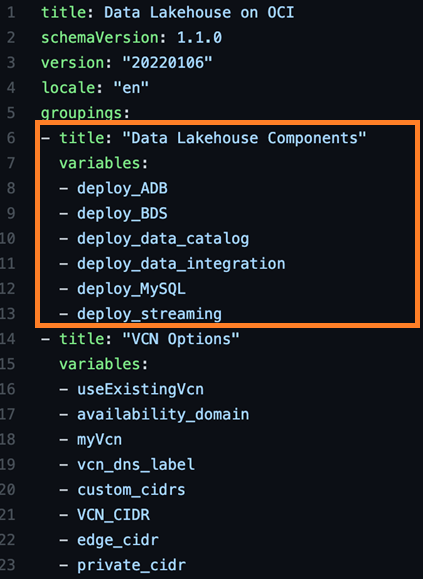
Lines 1–4 of the schema are for metadata. Line 5 is where the variable group section begins. Each variable group is prefixed with a title, and then the variables are part of the group: Lines 6–13 and 14–23 define our first two groups. You can trigger visibility either at the variable or variable group level. Let’s look at the Autonomous Data Warehouse variable group section:
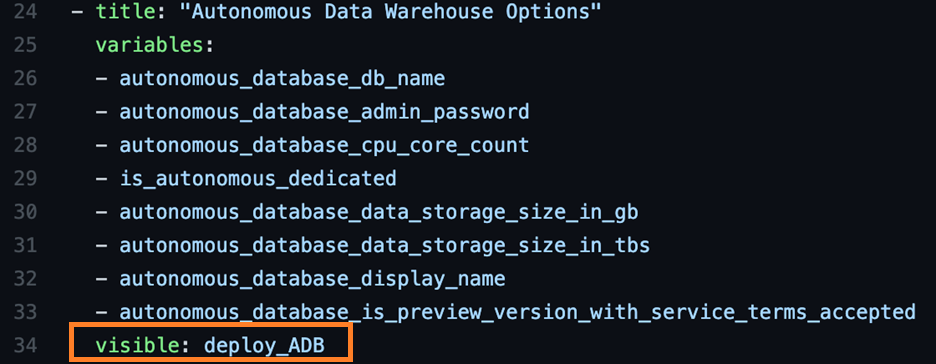
In line 34, a visibility option is set to the “deploy_ADB” variable. This variable is defined later in the schema as the first variable instantiated after the variable groups section where we set up all our variables after line 105:
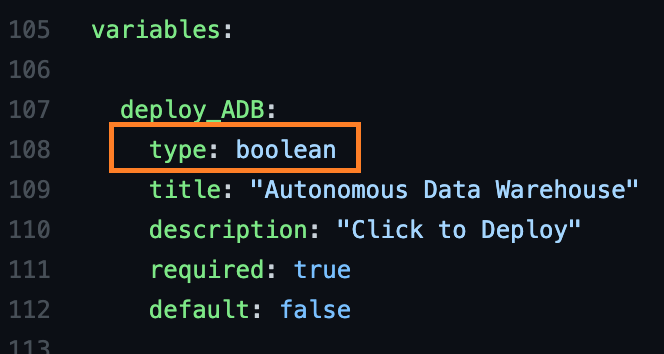
Line 108 defines this variable as a Boolean, which shows up as a check box in the UI. The default is “false,” which is unselected. When you select the box in the UI, the variable group for Autonomous Data Warehouse becomes visible because it relies on the Boolean for schema visibility.
This information also cascades into the main.tf Terraform. The Boolean “deploy_ADB” is used to turn the Autonomous Data Warehouse module on in line 24. The following screenshot shows the variables being passed into the module are mirrored from the schema overlay:
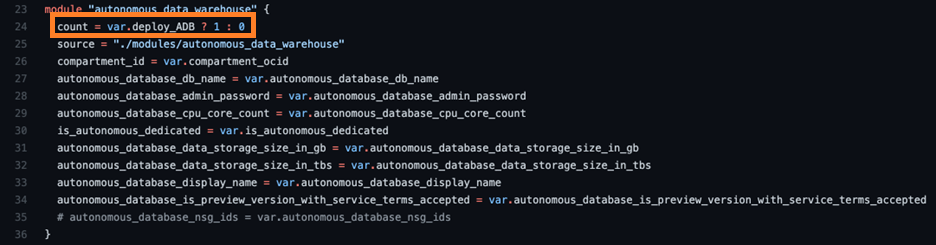
The module source is local to the repository, but the source can also refer to a remote module, such as using various OCI Cloud Bricks templates from the Oracle DevRel repository. This functions allows you to manage your modules independently of the stack.
Having more Booleans in the variable group supports even greater dynamic workflow. In this example, we have two more Booleans, one for Dedicated Exadata Infrastructure and one for using the Preview Version of the database. The module itself uses the database_autonomous_database Terraform resource, which supports several parameters. Because Data Warehouse is a workload type flag for Autonomous Database, it’s hard-coded in the module. However, Dedicated Exadata Infrastructure is a flag that sets the underlying infrastructure to be dedicated infrastructure or shared. This distinction impacts both cost and performance.
It also has a consequence in our Terraform of needing to set the license model to “null” if this option is enabled. We set up this dependency by hiding the preview license option when Dedicated Exadata Infrastructure is selected:

You can also set the `main.tf` module to sanity check these parameters passing into the module, based on the same Boolean logic with conditionals.
The variable is visible when “is_autonomous_dedicated” isn’t true, as shown in lines 287–289. The same logic is used when selecting a preexisting VCN, which hides subnet selection unless that Boolean returns true.
Setting up a predefined variable group in the schema allows variables that shouldn’t be part of the user workflow to be hidden. This section should contain all variables in the variables.tf file that aren’t defined in schema, or they show up uncategorized in the UI.
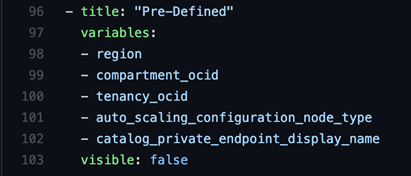
In this case, the template is hiding a handful of variables that are predefined or shouldn’t be modified.
Dynamic Terraform generation based on schema selection
Let’s look at another example of advanced customization that you can use to dynamically build Terraform code based on schema interaction. In this example, we look at how we can support flexible OCI shapes as part of an infrastructure-as-a-service (IaaS) template, where we might need to include specific parameters as part of the Terraform resource. In this example, we use this oke-airflow Oracle Quick Start for deploying Apache Airflow to OKE.
The template architecture diagram a deployed OKE cluster with a node pool and pods for Airflow containers. It also deploys an IaaS edge node as a bastion.
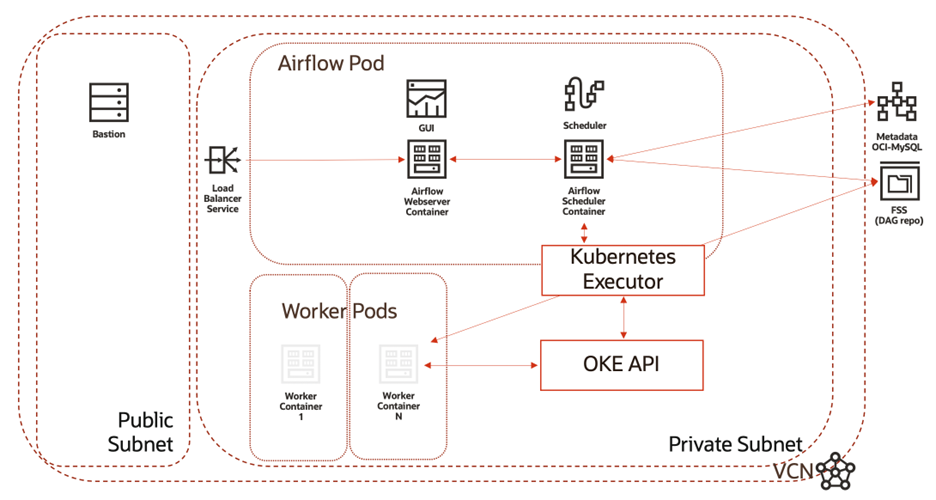
OCI has multiple options for the underlying IaaS for both the bastion and the OKE node pool workers. The second-generation infrastructure is based on Intel X7 hardware and has a static configuration for OCPU and memory. Newer infrastructure is flexible, supporting a dynamic number of OCPU and memory allocation. The Terraform provider documentation for core instances shows these parameters. The “shape_config” subsection of the resource has optional variables, ocpus and memory_in_gbs, which are required when selecting a flexible shape.
Let’s look at how we build this functionality into the schema overlay for selecting the node pool shape. First, we need to have a variable in the schema that uses the “oci:core:instanceshape:name” console integration:
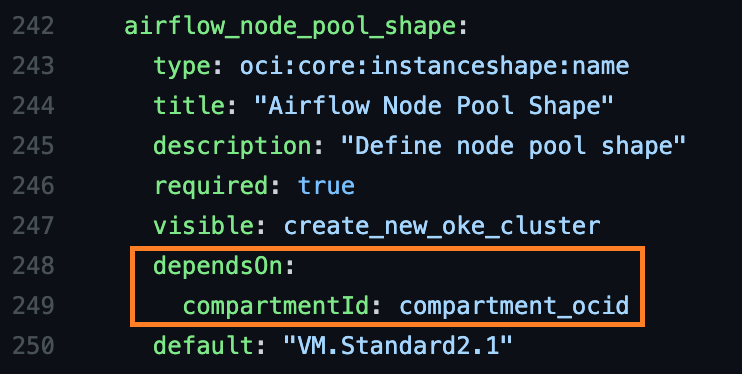
This shape has a dependency for the compartment, so that’s included on line 248-249, which is required. The default sets what shape is automatically selected in the menu, which is populated dynamically based on what shapes are available in the selected compartment, in your tenancy.
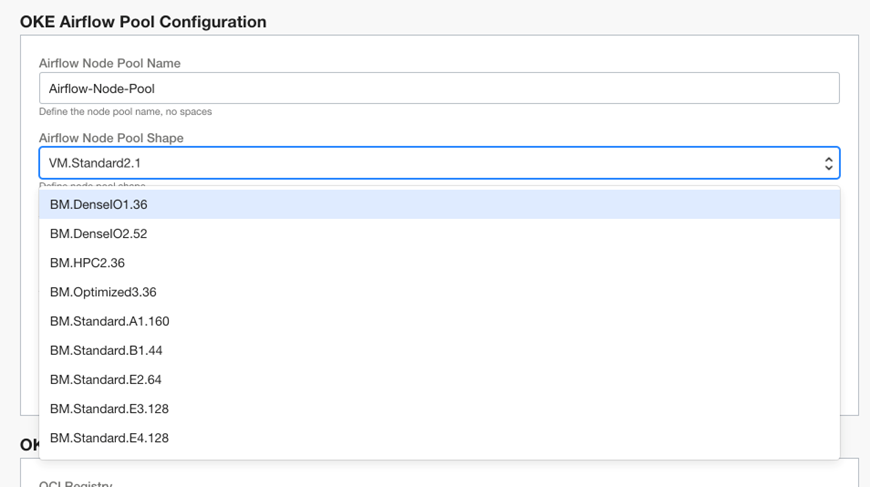
When a flexible shape is selected, we want the following things to happen:
- Toggle visibility for the OCPU variable.
- Toggle visibility for the memory_in_gbs variable.
- Build the shape_config block for the node pool shape selection.
The first two are fairly straightforward. We set a visibility flag on each of these parameters using some extra schema logic:
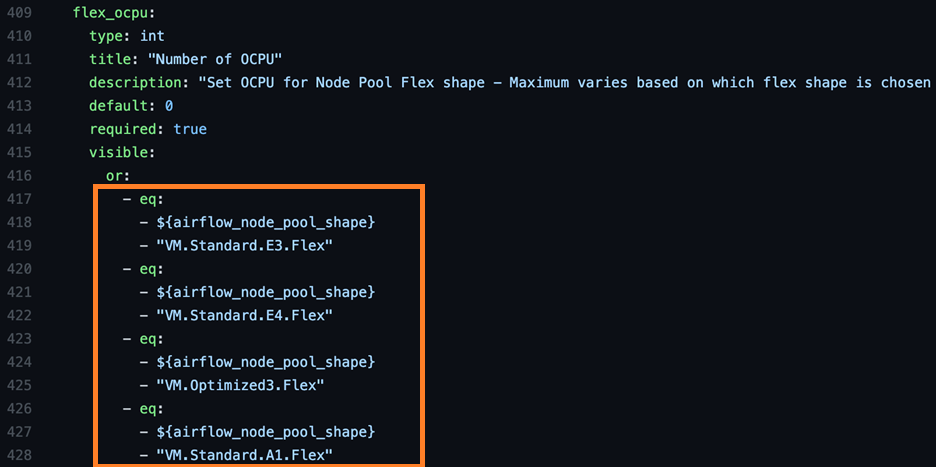
Visibility is turned on using “or” and “-eq”. These additions return true (visible) if any (or) of the comparators (-eq) return true. If any of the four flex shapes are selected in the menu, this command returns true and displays the OCPU variable in the UI. The same is true for the memory_in_gbs. These parameters are set in the schema as “flex_ocpu” and “flex_gbs” and passed into the OKE cluster module:
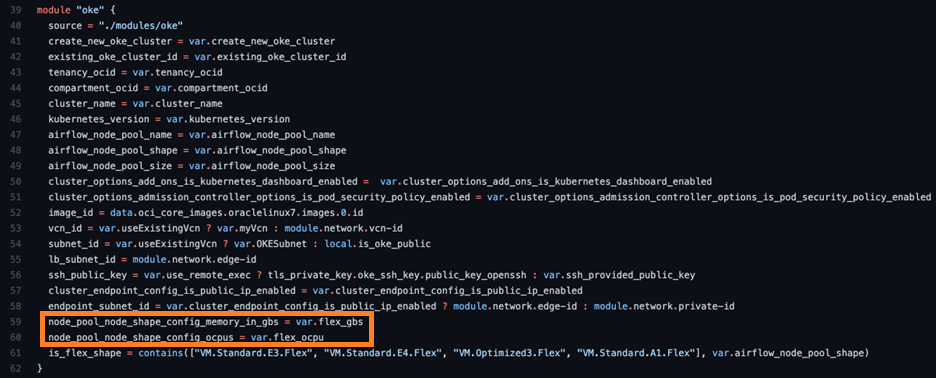
In lines 59-60, these parameters are passed into the module, set as slightly different variable names, which mirror the provider documentation for OKE node pools. We’re also doing passing in a Boolean for “is_flex_shape,” which uses the Terraform contains function to return “true” if the node pool shape matches in this array. This Boolean is then used in a local value in the OKE module. When true, that local value returns the passed parameters for OCPU and memory. Otherwise, it returns null.
![]()
In turn, the node pool configuration uses this output by using a dynamic Terraform code block, triggered by the local value.
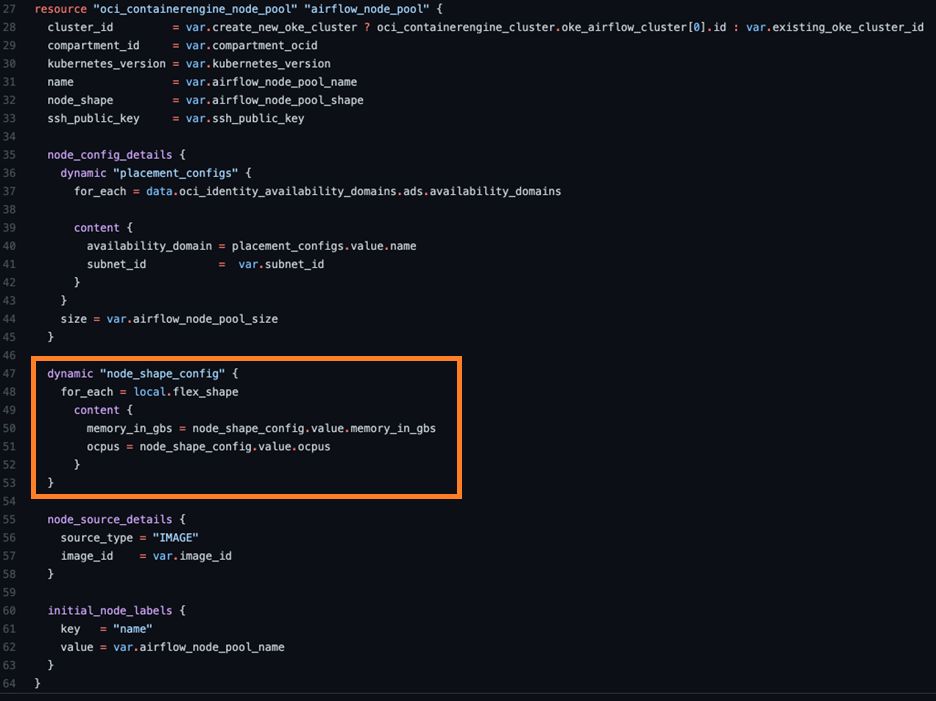
Lines 47-53 define that dynamic block. If the local returns values, then line 48 detects it and subsequently builds the content in lines 50-51 as part of the Terraform. If the local returns a null value, line 48 also triggers as null and doesn’t render the config. This function allows dynamic selection of the shape in our schema overlay to trigger inclusion or exclusion of variables in the module code!
Conclusion
Hopefully, this blog series has inspired you to go try out Oracle Resource Manager on OCI to create dynamic stacks driving your cloud deployment workflow. Using these tools provides a powerful way to automate complex stack deployments for your end users through a simple point-and-click interface.
If you’re interested in enhancing your knowledge of advanced Terraform, we recommend the Terraform 101 series on the Oracle Developer community site and reading Terraform: Up & Running, 2nd Edition by Yevgeniy Brikman.
Sign up for an Oracle Cloud Infrastructure account today and try out some of the awesome Terraform deployments available on Oracle Quick Start GitHub!
