When using Oracle Container Engine for Kubernetes (OKE), high availability is essential for ensuring system uptime even when a failure occurs. In a Kubernetes cluster, worker nodes can run across multiple availability domains in a multi-availability domain Oracle Cloud Infrastructure (OCI) region or across multiple fault domains in an OCI region with a single availability domain and multiple fault domain. To service high loads and achieve high availability, distributing the replicas of a deployment across different availability domains is important.
The primary goal of this blog is to explain different Kubernetes mechanisms that you can use to distribute pods of a deployment across nodes within an OKE cluster to achieve high availability. The concepts discussed in the blog, such as the use of node labels, anti-affinity, and TopologySpreadConstraints to distribute pods, are generally applicable to many Kubernetes scenarios. This blog can be useful in the following example situations:
-
Multiregion deployments: If you have a deployment that spans multiple regions, distributing the replicas across different availability domains within each region to achieve high availability is important.
-
Stateful applications: When running stateful applications on Kubernetes, ensure that replicas are distributed across different availability domains to avoid a single point of failure.
-
Continuous integration and deployment (CI/CD) pipeline: When deploying a new version of an application in a Kubernetes cluster, ensure that the new version of the app is distributed across different availability domains to ensure high availability and reduce the risk of failure.
Key terms
-
Availability domain: An availability domain is a logical grouping of data centers within a region. In a typical cloud provider’s infrastructure, an availability domain is a physically separate location with redundant power, cooling, and networking resources. They’re geographically separate locations within a region.
When you create a cluster with multiple availability domains, the nodes are spread across the availability domains. So, if one availability domain goes down, the nodes are still available in the remaining availability domains. This way, your cluster is still running and providing services
-
Node labels: In OKE, a worker node can be a virtual or physical machine that runs pods within a cluster. Labels are key-value pairs that you can add to Kubernetes objects, such as nodes, to specify identifying attributes that are meaningful and relevant to users. You can use node labels to identify different characteristics of a node, such as the availability domain it belongs to, the type of machine it is, or the operating system it runs. Kubernetes automatically assigns a set of standard labels to all nodes, and these labels can include information about the availability domain the node belongs to.
Identifying availability domains using node labels
Knowing about availability domains and node labels is helpful when you want to distribute your workload across different availability domains and ensure high availability for your services. On inspecting the labels on a node in an OKE cluster, reference the following code block:
oci@oci-mac % kubectl describe node 10.0.10.127
Name: 10.0.10.127
Roles: node
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=VM.Standard.E3.Flex
beta.kubernetes.io/os=linux
displayName=oke-cxeqigstkia-ndhpxqaqgsa-srp6z4k7mva-0
failure-domain.beta.kubernetes.io/region=phx
failure-domain.beta.kubernetes.io/zone=PHX-AD-1
hostname=oke-cxeqigstkia-ndhpxqaqgsa-srp6z4k7mva-0
internal_addr=10.0.10.127
kubernetes.io/arch=amd64
kubernetes.io/hostname=10.0.10.127
kubernetes.io/os=linux
last-migration-failure=get_kubesvc_failure
name=dis_oke_drcc2.0_cluster
node-role.kubernetes.io/node=
node.info.ds_proxymux_client=true
node.info/kubeletVersion=v1.24
node.kubernetes.io/instance-type=VM.Standard.E3.Flex
oci.oraclecloud.com/fault-domain=FAULT-DOMAIN-1
oke.oraclecloud.com/node.info.private_subnet=false
oke.oraclecloud.com/node.info.private_worker=true
oke.oraclecloud.com/tenant_agent.version=1.47.5-ed7c19ae8e-916
topology.kubernetes.io/region=phx
topology.kubernetes.io/zone=PHX-AD-1We can use several labels to identify an availability domain uniquely, including the following examples:
-
topology.kubernetes.io/zone=PHX-AD-1
-
failure-domain.beta.kubernetes.io/zone=PHX-AD-1
For our use case, we can use the topology.kubernetes.io/zone label.
Mechanisms For distributing pods across availability domains
Affinity and anti-affinity
The affinity feature has two types. Node affinity functions like the nodeSelector field but is more expressive and allows us to specify soft rules. Like nodeSelector, this simple method constrains pods to specific nodes with a set of labels.
Interpod affinity and anti-affinity allow us to constrain which nodes we can schedule our pods on based on the labels of pods already running on that node, instead of the node labels. These rules take the form “this Pod should (or, in the case of anti-affinity, should not) run in an X if that X is already running one or more Pods that meet rule Y,” where X is a cloud provider availability domain and Y is the rule that Kubernetes tries to satisfy.
For our use case, we focus on the latter functionality. We can set up pod anti-affinity rules in the following ways:
-
Hard rules that are mandatory: The scheduler can’t schedule the pod unless the rule is met. This rule is identified by the requiredDuringSchedulingIgnoredDuringExecution keyword.
- Soft rules, more like a suggestion: The scheduler tries to find a node that meets the rule. If it finds no matching node, the pod gets scheduled on any available node. This rule is identified by the preferredDuringSchedulingIgnoredDuringExecution keyword.
Hard affinity rule
We can define a hard affinity rule according to the following code block to distribute the pods across nodes in different availability domains:
apiVersion: apps/v1
kind: Deployment
metadata:
name: adtest-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 4
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: topology.kubernetes.io/zone
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
memory: "500Mi"In this configuration, topologyKey is the key of the node label to be used. Pods that match the labelSelector are counted and recognized as a group when spreading to satisfy the constraint. Specify a label selector, or no pods can be matched.
If we try scheduling four replicas of a pod with this configuration, three of them get scheduled on nodes belonging to different availability domains while the fourth remains in pending state. The hard rule mandated by requiredDuringSchedulingIgnoredDuringExecution doesn’t schedule the replica unless constraints are met, and only three availability domains are open and each availability domain already has a pod from this deployment scheduled.
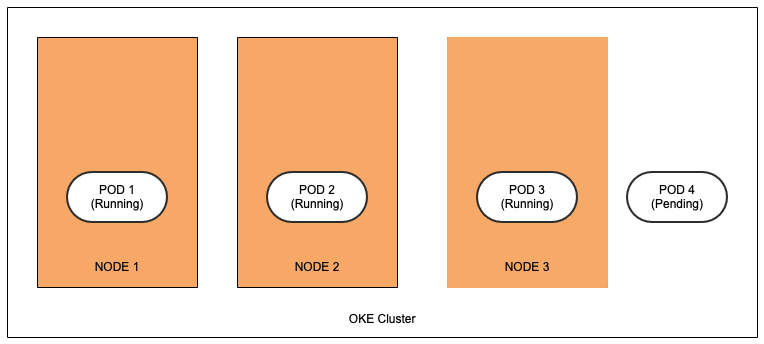
This approach works best while working with deployments that can have a maximum of three replicas that we want to spread across three availability domains.
Soft affinity rule
To schedule more than three pods across availability domains, we go with the following soft rule:
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: topology.kubernetes.io/zone
weight: 100The weight can have a value between 1–100 for each instance of the preferredDuringSchedulingIgnoredDuringExecution affinity type. When the scheduler finds nodes that meet all the other scheduling requirements of the pod, the scheduler iterates through every preferred rule that the node satisfies and adds the value of the weight for that expression to a sum.
We can schedule more than three pods with this configuration. The pods spread across the availability domains. If it can’t meet the constraint, the pod is scheduled on any available node, which can potentially lead to a skewed distribution of pods across the nodes.
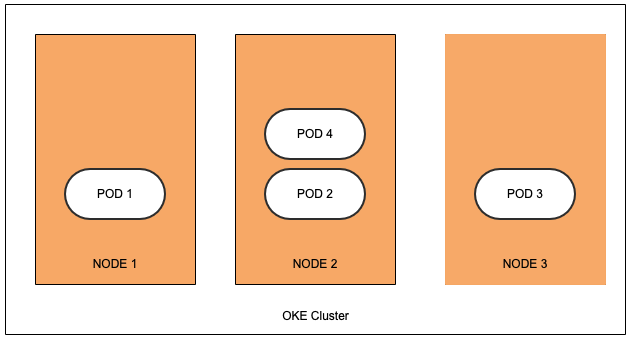
TopologySpreadConstraints
If our cluster spans multiple availability domains or regions, we can use node labels in conjunction with pod topology spread constraints to control how pods are spread across our cluster among fault domains, regions, availability domains, and even specific nodes. These hints enable the scheduler to place pods for better availability, reducing the risk that a correlated failure affects our whole workload. We specify which pods to group together, which topology domains they are spread among, and the acceptable skew. Only pods within the same namespace are matched and grouped together when spreading due to a constraint.
We can specify multiple topology spread constraints, but ensure that they don’t conflict with each other.
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx The term maxSkew describes the degree to which pods can be unevenly distributed. Specify this field with a number greater than 0. Its semantics differ according to the value of whenUnsatisfiable.whenUnsatisfiable dictates how to handle a pod if it doesn’t satisfy the spread constraint.
The state of DoNotSchedule is the default. When set, the maxSkew defines the maximum permitted difference between the number of matching pods in the target topology and the global minimum (the minimum number of matching pods in an eligible domain or zero if the number of eligible domains is less than MinDomains). For example, if we have three availability domains with two, two, and one matching pods, MaxSkew is set to 1 and the global minimum is 1.
ScheduleAnyway instructs the scheduler gives higher precedence to topologies that would help reduce the skew.
Conclusion
Achieving high availability in an OKE cluster is crucial for ensuring system uptime and servicing high loads. By understanding the concepts of availability domains, node labels, Anti-Affinity and TopologySpreadConstraints, you can distribute pods of a deployment across different availability domains or faults domains within an OKE cluster. This capability is particularly useful for multiregion deployments, stateful applications, and CI/CD pipelines. With this knowledge, you can minimize the risk of a single point of failure and improve the overall reliability of your OKE cluster.