Quantum simulation of materials is a promising approach to bridge theory and experiments in disparate research areas, such as chemistry, material science, nanotechnology, or condensed matter physics. Quantum ESPRESSO (QE) is an integrated suite of open-source computer codes designed for electronic-structure calculations and materials modeling at the nanoscale.
At the heart of QE lies a suite of electronic structure methods based on density functional theory (DFT) and many-body perturbation theory (MBPT), including density functional theory (DFT), time-dependent density functional theory (TD-DFT), and GW approximation (GWA). These techniques enable scientists to predict the properties of materials with great precision, from their atomic structures and energetic landscapes to their dynamic behavior under external stimuli like temperature or pressure changes.
In the last years of development, QE has increasingly adopted GPU acceleration across the different tools to improve performance and, therefore, economics. In a recent paper, the development team describes the steps implemented and the results achieved in great detail.

In this blog post, we analyze the cost and performance benefits of running QE on the Oracle Cloud Infrastructure (OCI) shapes based on NVIDIA GPUs. OCI has a flexible set of shapes with different GPUs that are fit for different workloads, including high-performance computing (HPC), AI, and graphics. In this post, we focus on BM.GPU4.8, which includes eight NVIDIA A100 Tensor Core GPUs (40 GB SXM) . This GPU shape offers excellent double precision performance (FP64) , uses NVIDIA NVL ink for fast GPU-GPU communication , and offers fast interconnect available in OCI superclusters, which allow easy calculation scaling.
QE benchmarks
We consider two standard QE benchmarks, AUSURF112 and GRIR443. AUSURF112 is a small benchmark that simulates a gold surface while GRIG443 is a carbon-Iridium complex and is medium size. As baseline performance, we run the benchmarks on OCI E5.HPC shapes.
E5.HPC offers a 144-core bare metal server with AMD 4th Gen EPYC (codenamed Genoa) on Oracle’s ultra-low-latency remote direct memory access (RDMA) network that scales efficiently to tens of thousands of cores. To achieve the maximum performance, we used a mixed MPI + OpenMP approach: 12 MPI processes per server, each of them pinned to one of the chiplets that compose the Genoa architecture and 12 OpenMP threads for each MPI process to use all the available cores and to benefit of the memory hierarchy. For AUSURF112, we performed the calculation at 576 cores (4 nodes), and for GRIR443 at 720 cores (5 nodes).
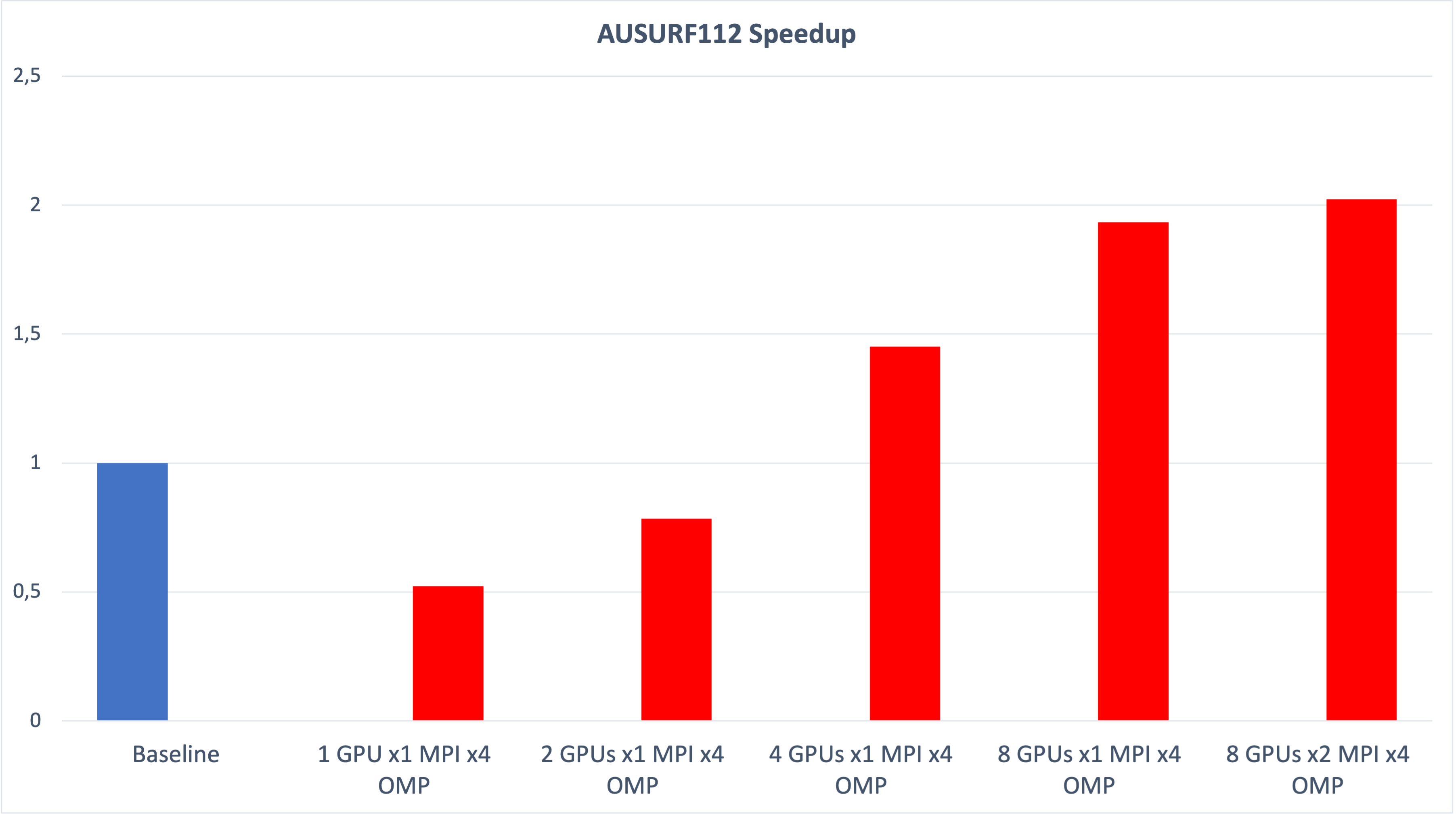

We observe good scaling as we increase the number of GPUs, even for the small benchmark AUSURF112, where we see a performance improvement of two times the baseline. The speed up for GRIR443 is more than three times, as it is a larger system and scales more easily.
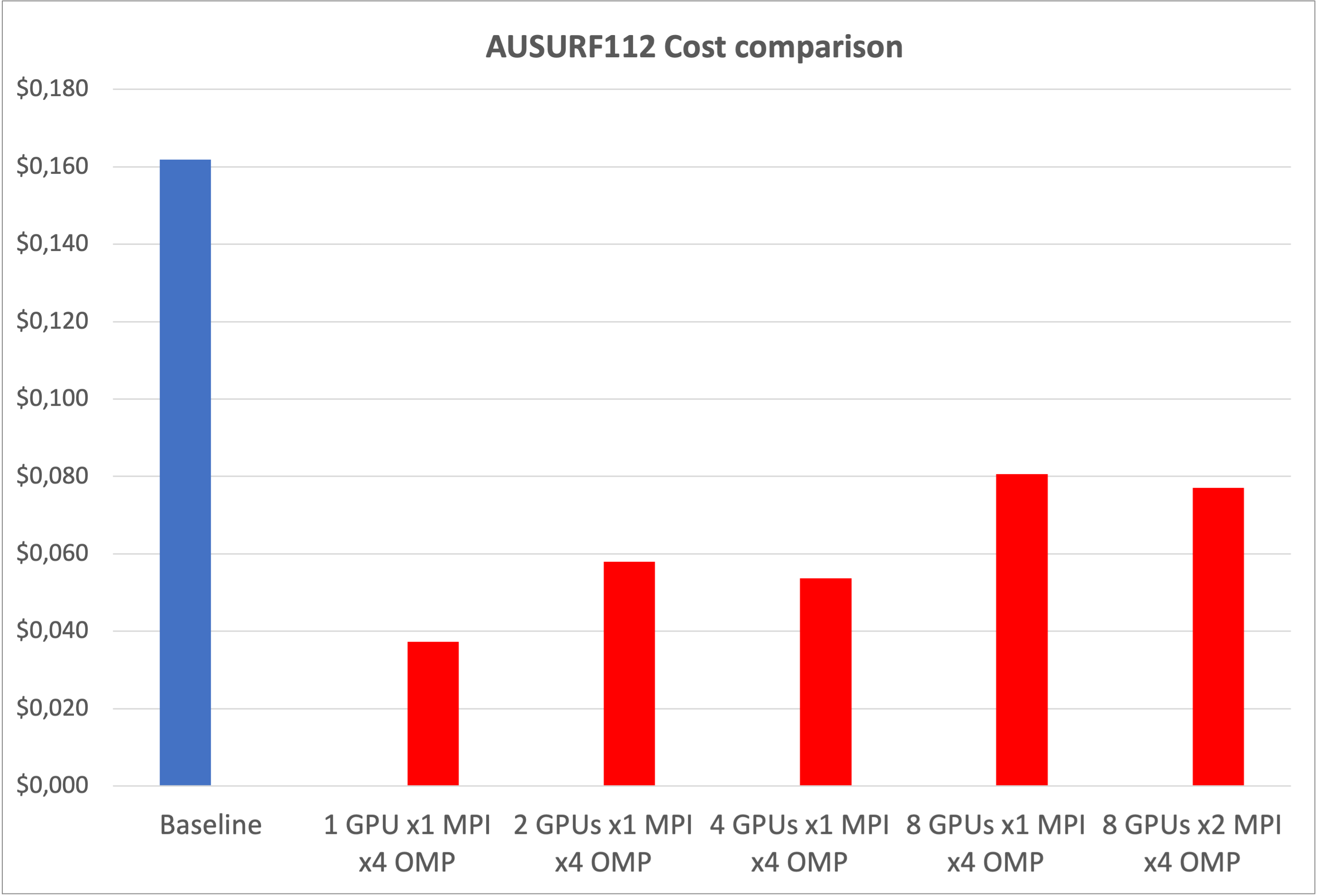

This performance improvement also shows clear cost savings, approximately 75% compared to the baseline. For AUSURF112, the cheapest calculation uses a single GPU, and shows that for small calculations the most cost-effective approach is to run several calculations in parallel on different GPUs. For the larger GRIR443, you get the best economics when you use all the GPUs in a node.
Notably, the GPU memory is a limiting factor that can prevent job execution, so it wasn’t possible to run any GRIR443 calculation with less than six GPUs. For the same reason, it wasn’t possible to run calculations with “-npool” larger than 2.
Running QE on OCI
To initiate GPU instances, you can use the Oracle Cloud Console, API, and software develop kits (SDKs), or opt for the fully managed Kubernetes service. The OCI HPC Stack, accessible through the Oracle Cloud Marketplace, facilitates the deployment of HPC resources within a cloud setting. This solution streamlines the setup of HPC clusters by integrating RoCE network and storage configurations. It also offers a master node preconfigured with essential HPC tools, such as Slurm and Environment Modules.
The simplest way to run QE optimized to run on an OCI GPU shape powered by NVIDIA is to download the container that’s available in the NVIDIA NGC catalog , a portal of enterprise services, software, management tools, and support for end-to-end AI workflows . The NVIDIA documentation explains clearly how to run QE with NVIDIA-docker or with singularity.
If you prefer to compile QE, you can install the NVIDIA HPC SDk on your cluster with the following command:
sudo dnf config-manager --add-repo https://developer.download.nvidia.com/hpc-sdk/rhel/nvhpc.repo sudo dnf install -y nvhpc-24.1 sudo yum install -y nvhpc-cuda-multi-24.1
The installation comes with some useful module files that you can import in the cluster module file directory:
cp -r /opt/nvidia/hpc_sdk/modulefiles/* /etc/modulefiles/
You can load the module file to prepare the environment.
module load nvhpc-openmpi
We can configure QE to use the GPUs with the following command:
./configure --with-cuda=/usr/local/cuda-12 --with-cuda-cc=80 --with-cuda-runtime=12.3 --enable-openmp --with-cuda-mpi=yes make
By default, QE tries to use its internal math libraries. To improve performance, we recommend using of high-performance libraries.
The BM.GPU4.8 shape contains eight A100 GPUs and 64 physical CPU cores. The best configuration identified uses two MPI processes for each GPU and four OpenMP threads for each process.
Conclusion
The usage of OCI GPU shapes powered by NVIDIA can bring great benefits to running Quantum ESPRESSO. We compare benchmarks for BM.GPU.4.8 and E5.HPC and observe up to three times the performance improvement and, in terms of price-performance, a cost reduction of 75% when performing electronic relaxations. These results indicate that OCI-based GPU shapes should be the default choice for electronic structure calculations with Quantum ESPRESSO.
In the next post of the series, we provide multinode GPU benchmarks for A100-based shapes and also for BM.GPU.H100.8, the new shape based on NVIDIA H100 Tensor Core GPU.
Free learning resources are available at the HPC workshops and training to help you get the most out of your Oracle HPC development and deployment experience. For more information on Oracle Cloud Infrastructure’s capabilities, visit us at GPU compute and HPC.
For more information, see the following links:
- OCI Supercluster and AI Infrastructure
- Oracle Cloud Infrastructure
- OCI GPU Compute Shapes
- Quantum ESPRESSO GPU adoption
- Introduction to Quantum ESPRESSO
