Growing model sizes and expanding computing needs require more than a single node of NVIDIA GPUs and shared data. IBM software-defined storage across multiple GPU compute nodes creates a data platform with the benefits of NVIDIA Magnum IO-accelerated communications. A hyper-converged cluster is rapidly deployed, delivers high performance, and is remarkably efficient.
In collaboration with NVIDIA and IBM, Oracle Cloud Infrastructure (OCI) validated NVIDIA Magnum IO Storage on OCI using a hyperconverged cluster of bare metal NVIDIA A100 Tensor Core GPU compute nodes interconnected with remote direct memory access (RDMA). Each node comes with eight NVIDIA A100 40GB SXM GPUs, 16 100-Gbps RDMA network interface cards (NICs), and four 6.8-TB (27.2 TB) local non-ephemeral NVMe solid state drives (SSDs). Using IBM Storage Scale’s parallel file system, we built a single global namespace using SSDs from all GPU nodes.
OCI is the first major cloud service provider that offers NVIDIA A100 GPUs as a bare metal offering and a prerequisite for NVIDIA Magnum IO GPUDirect Storage (GDS). On OCI, you can use GDS to get considerably higher storage I/O performance and maximize GPU performance by decreasing latency and increasing bandwidth. GPU applications and GDS significantly reduce the CPU and host-memory usage, allowing for running storage and compute nodes in a converged architecture. This solution scales better and can provide lower total cost of ownership (TCO).
We observed the following benefits of GDS:
- DeepCam inference benchmark: Shows the performance of an application used to identify hurricanes and atmospheric rivers in climate simulation data, saw nearly 1.5x higher bandwidth in GB-per-second and throughput in samples-per-sec with GDS enabled
- RAPIDS cuDF Parquet reader benchmark: Uses an open source suite of GPU-accelerated Python libraries to improve data science and analytics pipelines, saw up to 7x improvement with GDS
- gdsio storage benchmark: Uses a storage IO load generating tool to analyze storage performance, saw up to 3.5x higher bandwidth, up to 3.5x lower latencies, and low CPU utilization
What is NVIDIA Magnum IO GPUDirect Storage?
As datasets increase in size, the time spent loading data can impact application performance. NVIDIA GPUDirect Storage creates a direct data path for RDMA between GPU memory and local or remote storage, such as NVMe or NVMe over Fabrics (NVMe-oF). By enabling a direct-memory access (DMA) engine near the network adapter or storage, it moves data into or out of GPU memory, which avoids a bounce buffer through the CPU. This direct path increases system bandwidth and decreases the latency and utilization load on the CPU.
What is IBM Storage Scale?
IBM Storage Scale is an industry leader in high-performance file systems. The underlying parallel filesystem (GPFS) provides scalable throughput and low-latency data access, as well as superior metadata performance.
IBM Storage Scale is optimized for modern AI workloads, with optimizations for common data patterns, NVIDIA GPUDirect Storage, and runtime controls to align data performance with application needs, including optimizations for small files, multiple protocols, and metadata operations. Fast directory and file management are required for the many workloads that distribute data across multiple directories or many files.
IBM Storage Scale creates a single namespace or data plane across systems. This single data plane allows the data administrator, analyst, or data scientist to access all the data in one place. You can complete the entire data pipeline, from ingest to inference, without having to make more copies or move data between systems.
Reference architecture
The following graphic depicts a hyperconverged cluster, where GPU compute applications and storage servers run on the same nodes. Depending on your requirements for usable storage capacity, data resiliency with no replication on a shared-nothing architecture or with replication and erasure coding, and the number of GPUs nodes (N) available in your cluster, you have the flexibility to decide whether you want to use all or only few nodes (M) to run Storage Scale file servers. The value of M can be a minimum of three nodes and maximum of N nodes. If using the shared-nothing architecture, M must be a minimum of three nodes. If using Storage Scale Erasure Coded edition, M must be greater than or equal to six nodes (4+2P). Storage Scale clients run on all GPU nodes.
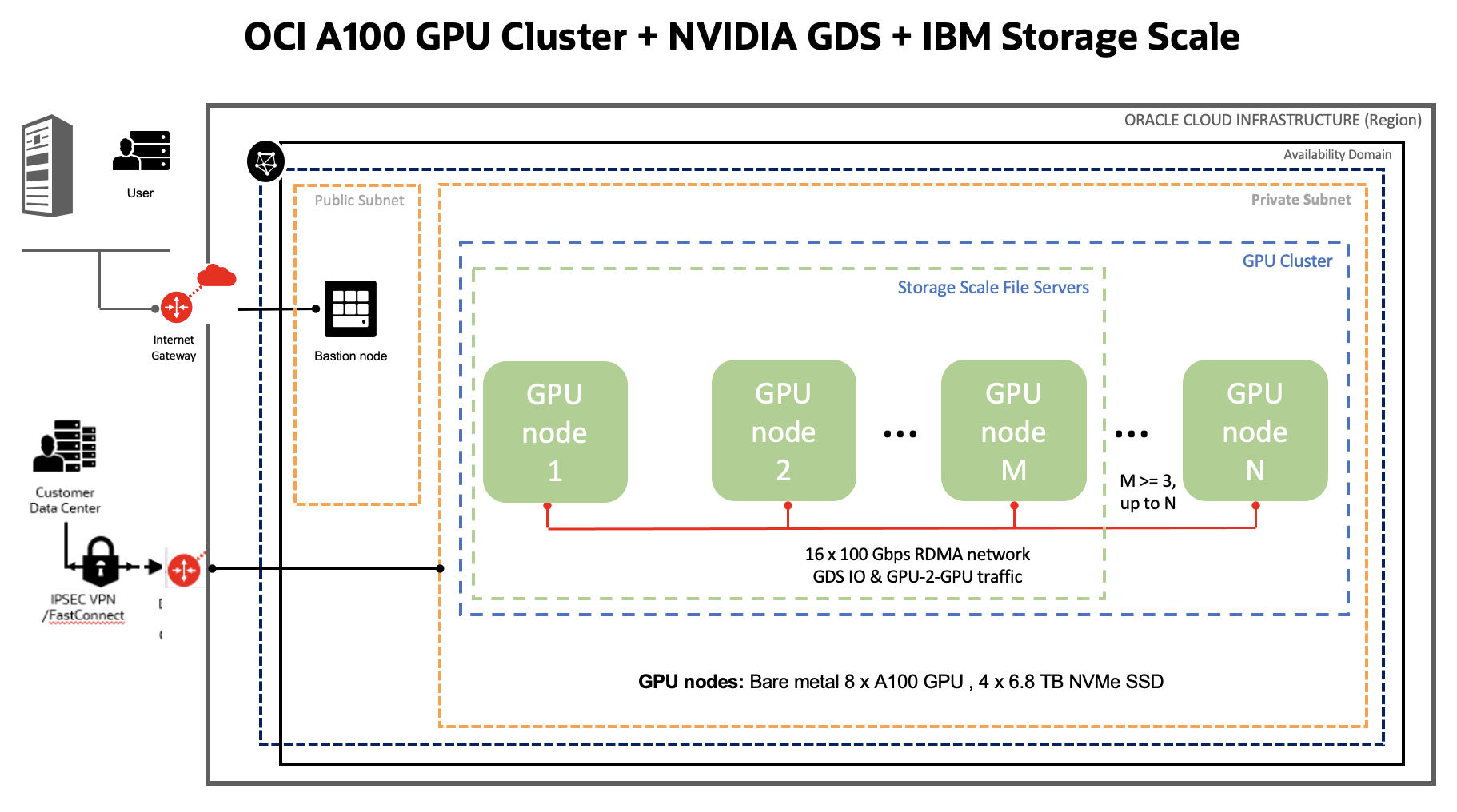
Figure 1. Reference architecture for a hyperconverged cluster running GPU application and storage on same nodes.
Testbed
We created a hyperconverged cluster of three GPU nodes (eight NVIDIA A100 40GB SXM, 16 100-Gbps RDMA, and four 6.8-TB NVMe SSDs) interconnected with RoCEv2 RDMA. We created a single global storage namespace by running IBM Storage Scale using SSDs from all nodes. DeepCam Inference, RAPIDS cuDF Parquet reader and storage benchmarks like gdsio and elbencho were run. We configured the testbed to use eight RDMA NICs in cufile.json. However, you can configure it to use fewer or more RDMA NICs. We configured Storage Scale in shared-nothing architecture mode (with no replication and no erasure coding) to create a single namespace of 75-TB usable storage capacity across 12 NVMe drives configured as 12 NSD drives.
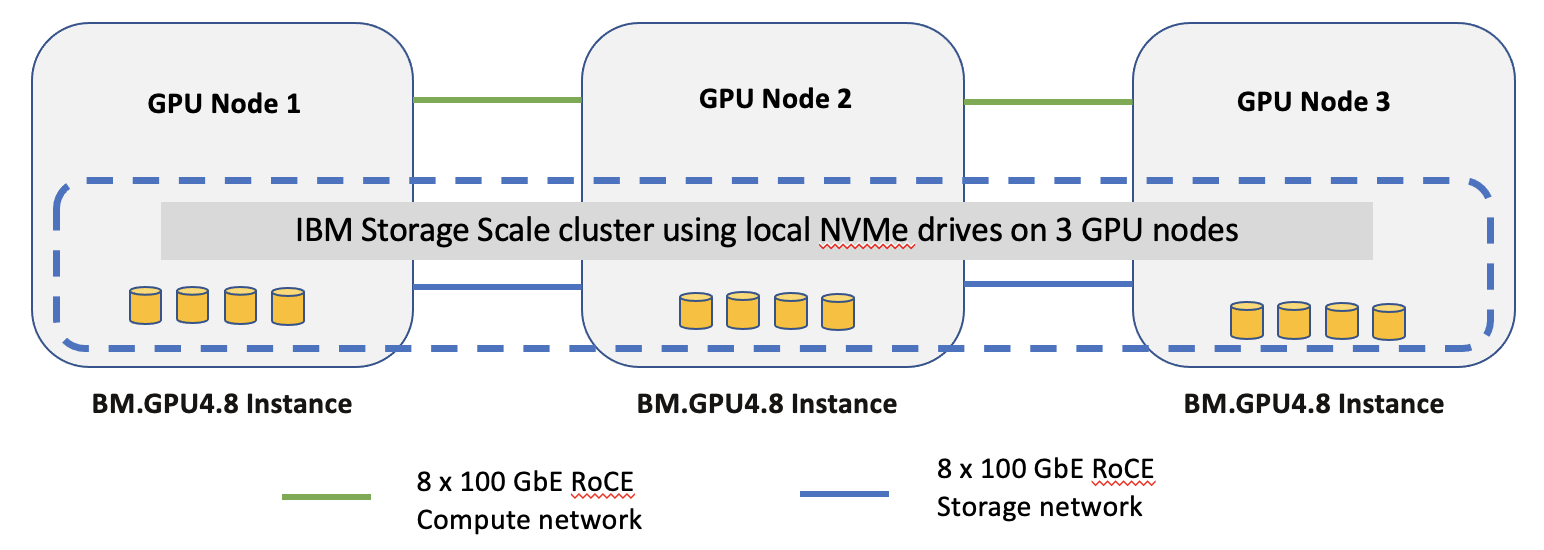
Figure 2. Testbed cluster of hyperconverged cluster with three nodes
The nodes ran the following software packages:
- Ubuntu 20.04 (5.15.0-1030-oracle)
- NVIDIA MOFED 5.4-3.6.8.1
- Storage Scale 5.1.6.1
- NVIDIA Drivers 525.85.12-1
- NVIDIA CUDA-11.8
Benchmarks
DeepCam inference benchmark
We used the DeepCam inference benchmark to show the performance of an application used to identify hurricanes and atmospheric rivers in climate simulation data. We saw nearly 1.5x higher bandwidth in GB-per-second and throughput in samples-per-second with GDS enabled for single node (8 GPUs) and three-node (24 GPUs) inference runs.
| Number of nodes | IO Type | GDS enabled | GDS disabled | GDS gain |
|---|---|---|---|---|
| 1 Node (8 GPUs) | Max bandwidth GB/s | 35.59 | 23.94 | 1.48 times |
| Max throughput samples/sec | 674.88 | 459.76 | 1.47 times | |
| 3 Nodes (24 GPUs) | Max bandwidth GB/s | 81.53 | 57.31 | 1.42 times |
| Max throughput samples/sec | 1546.12 | 1086.64 | 1.42 times |
Single-Node (8-GPU) inference
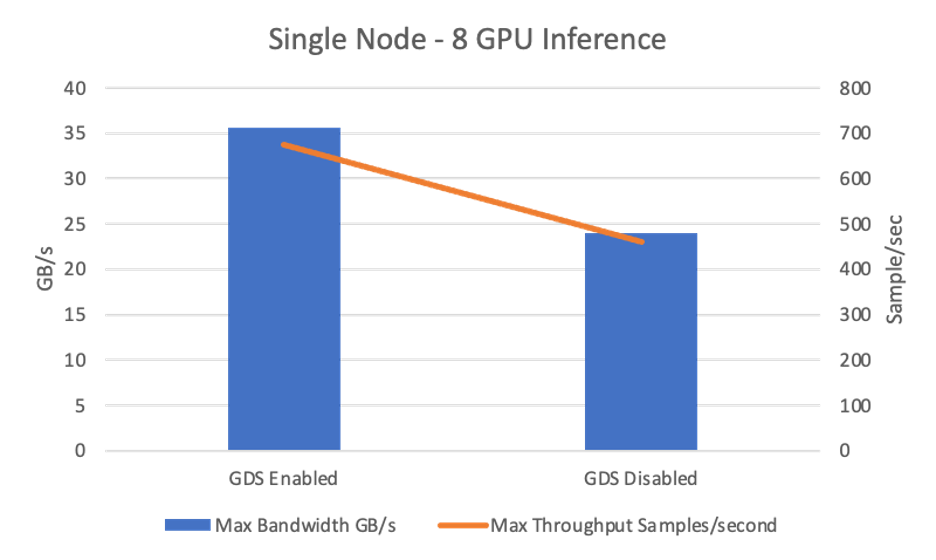
Figure 3. Shows maximum bandwidth and throughput for a single-node, 8-GPU DeepCam inference test with GDS enabled and disabled
Three-node 24-GPU inference
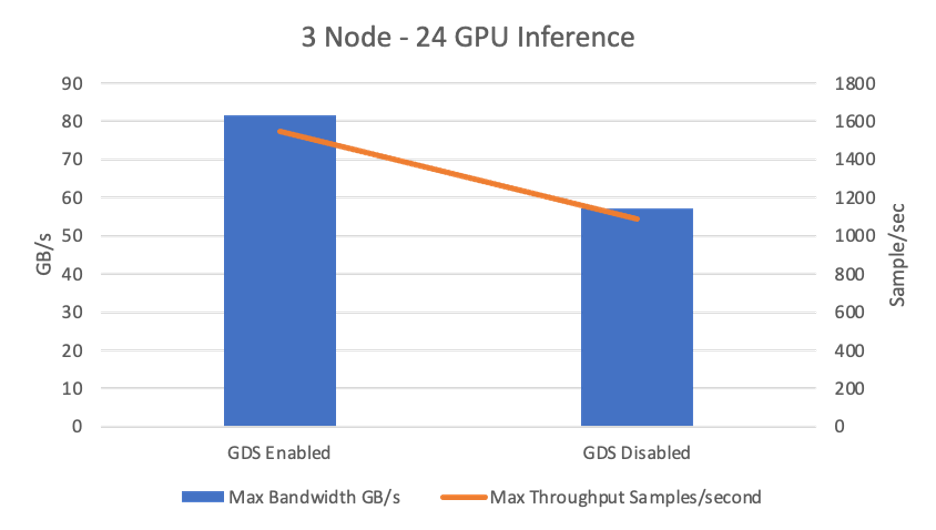
Figure 4. Shows maximum bandwidth and throughput for three-node, 24-GPUs DeepCam inference test with GDS enabled and disabled
GDSIO benchmark
NVIDIA offers the gdsio tool to measure GDS performance. The following table summarizes GDS’s performance against regular IO performance on OCI with the various IO transfer sizes simulated against the IBM Storage Scale system.
We saw up to a 2.7x gain in READ performance with GDS enabled for the highest IO transfer size we tested.

Table 2. Shows improvement (GDS Gain) in READ performance when GDS is enabled for different IO transfer sizes
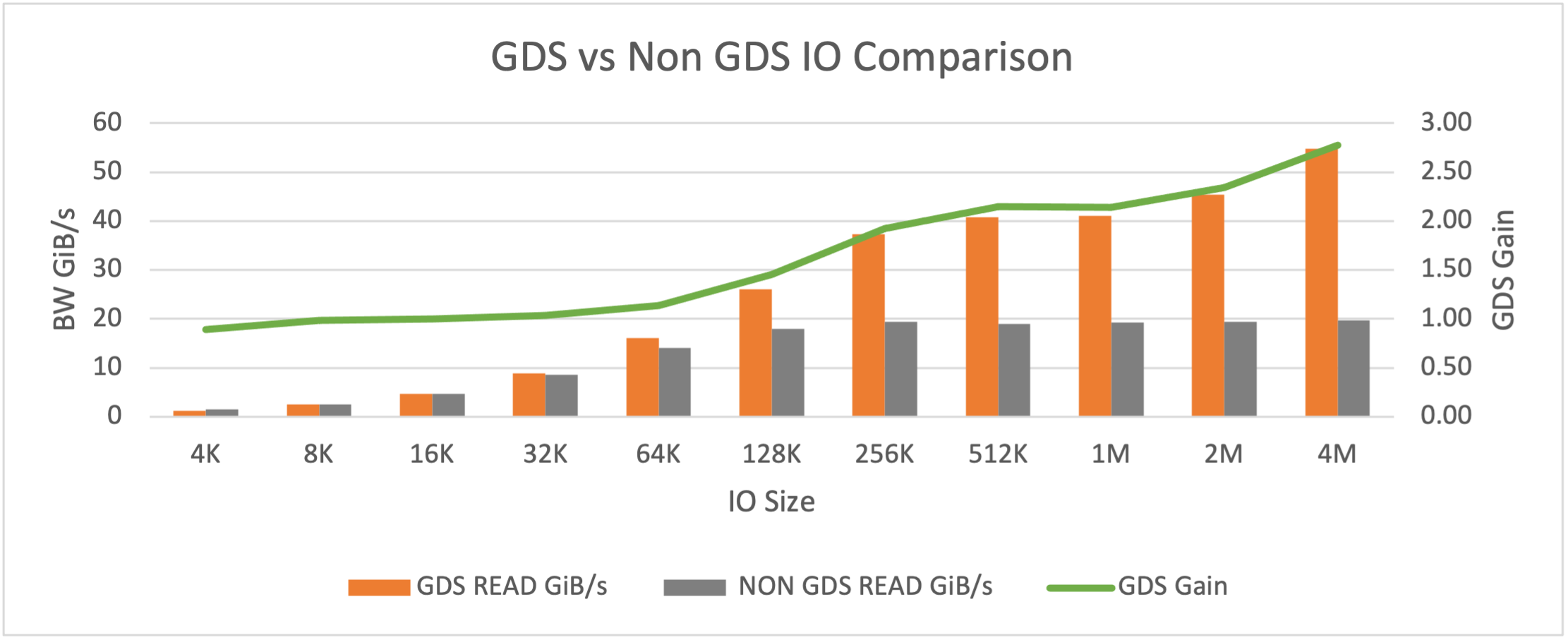
Figure 5. Read Bandwidth (GB/s) and GDS Gain for different IO transfer sizes with GDS enabled and disabled
Figure 6 shows that GDS delivers up to 3.5x higher bandwidth and up to 3.5x lower latencies.
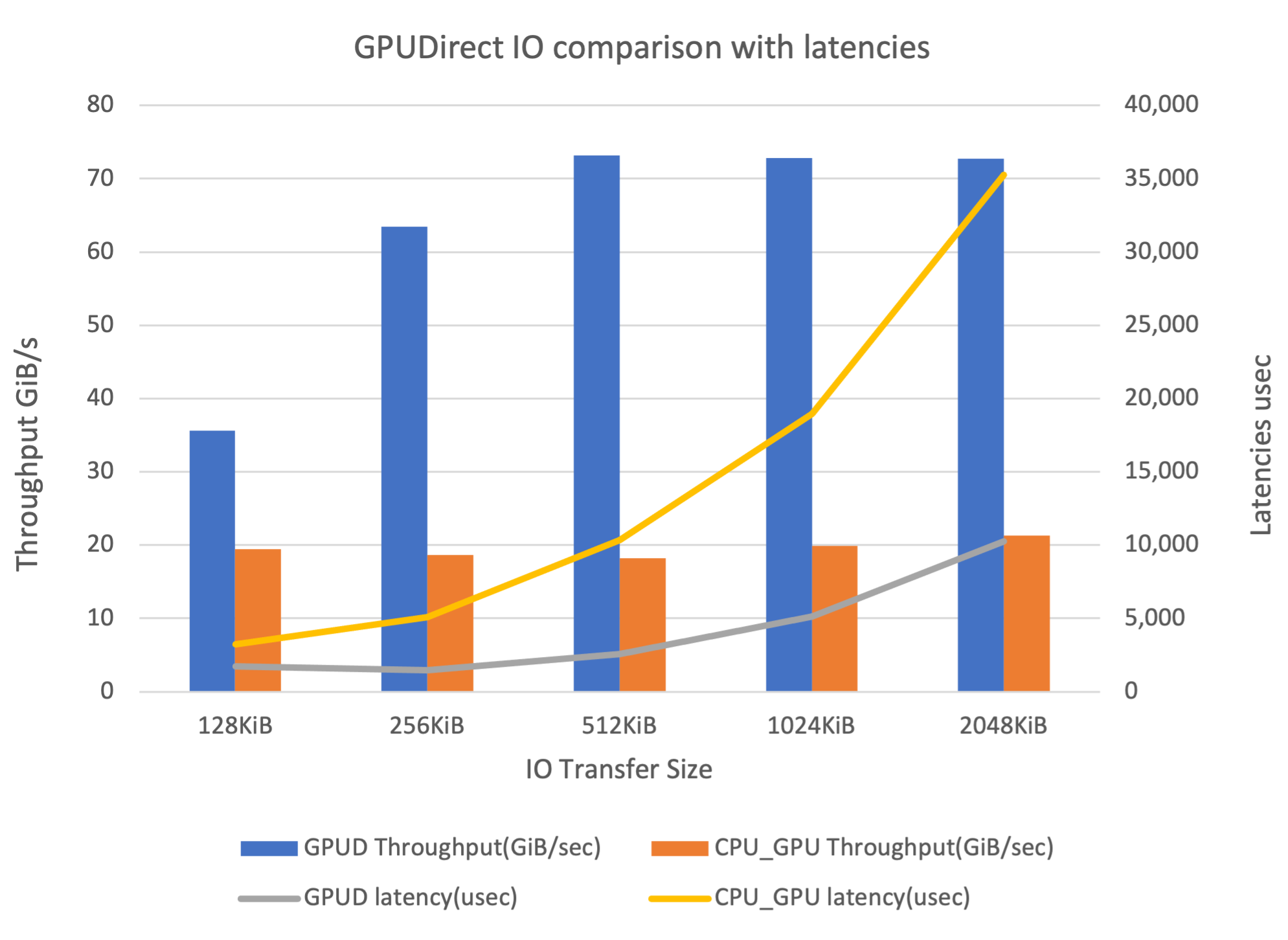
Figure 6. GDS IO tests show up to 3.5x greater throughput and up to 3.5x lower latencies for different IO transfer sizes with and without GDS
Figure 7 shows lower CPU utilization when GDS is enabled.
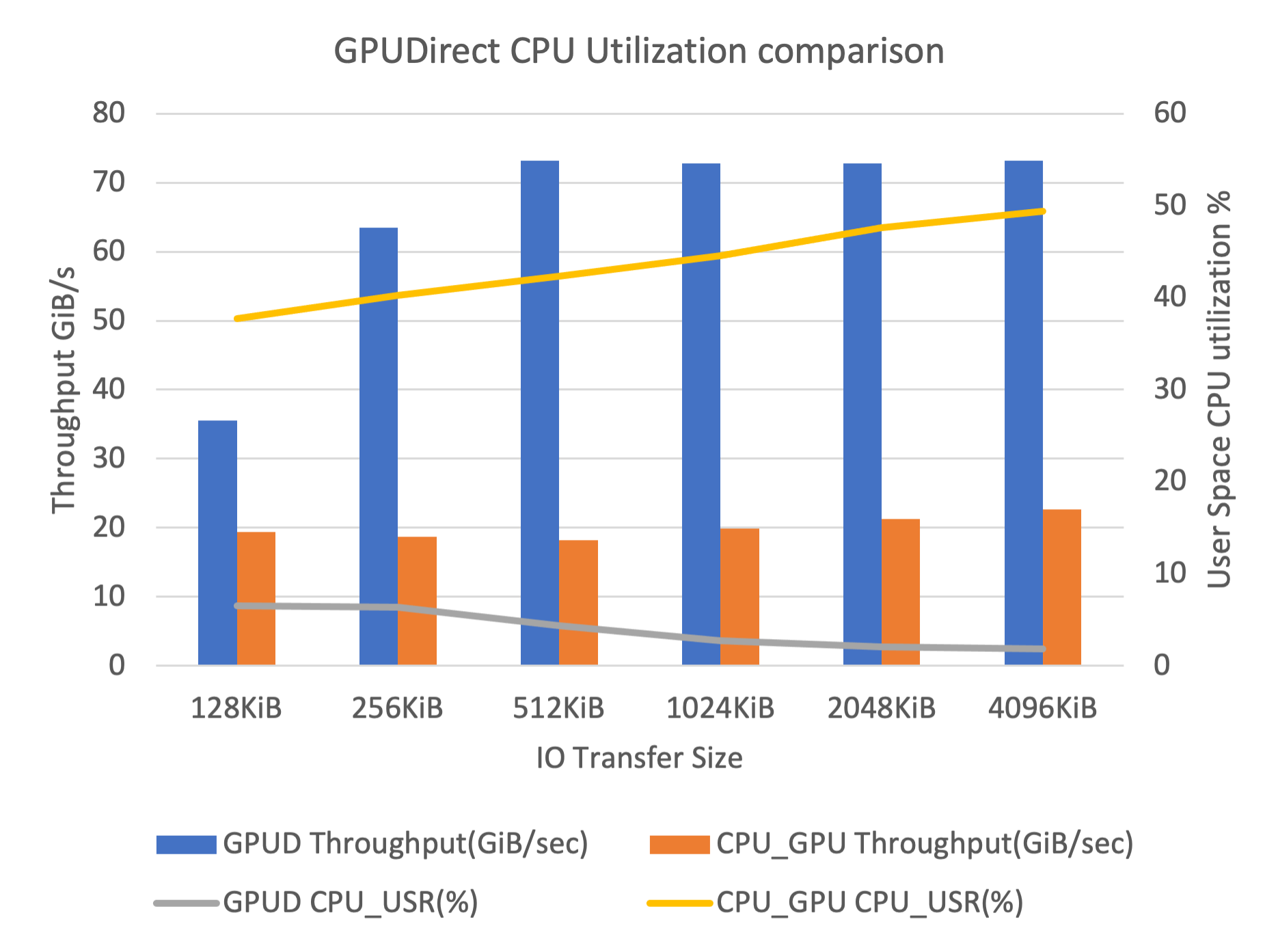
Figure 7. Shows CPU utilization and throughput for different IO transfer sizes with and without GDS
Figure 8 shows bandwidth and latency against the number of GPU threads.
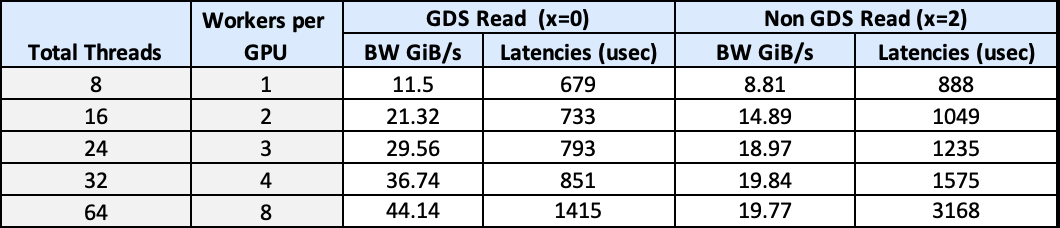
Table 3. Shows bandwidth and latency performance against the number of worker threads per GPU for GDS enabled or disabled
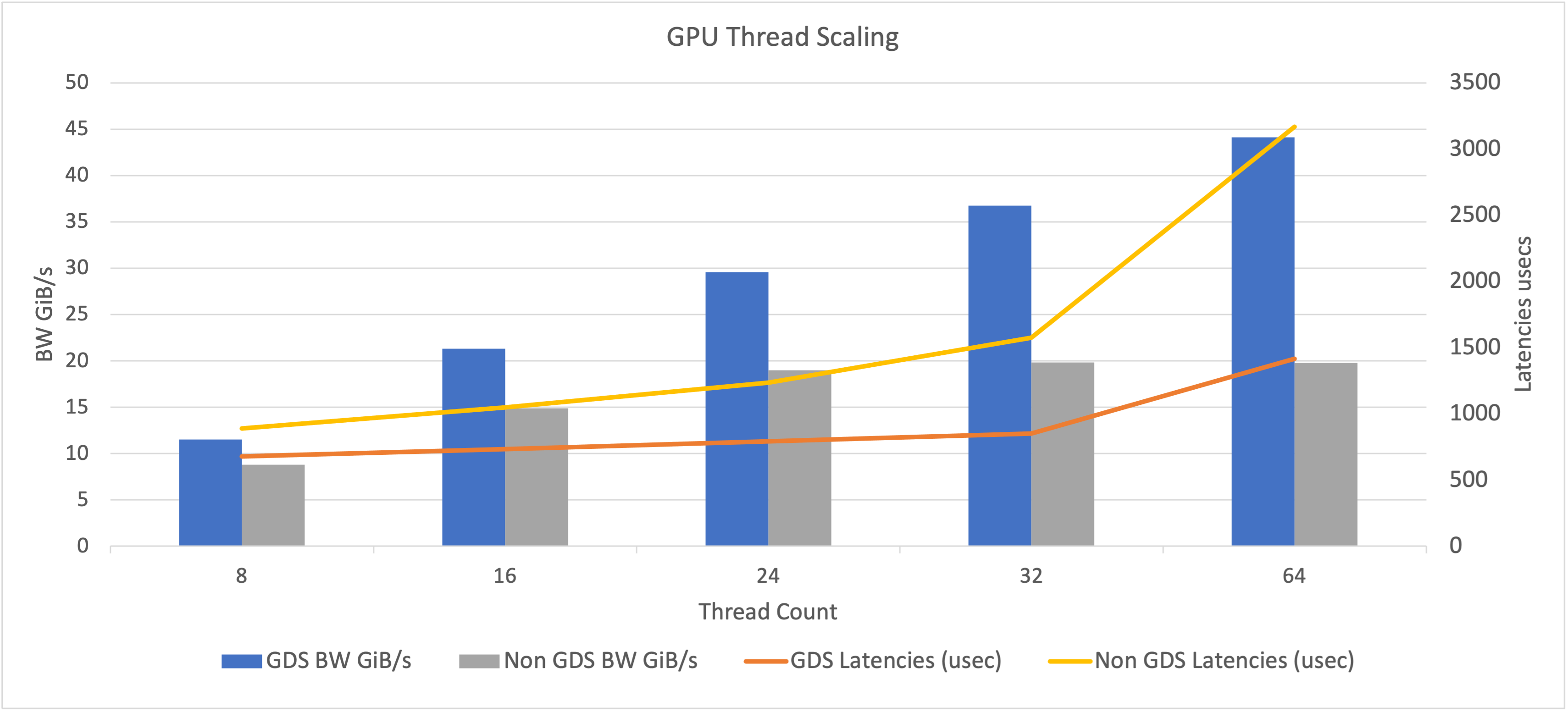
Figure 8. Shows bandwidth and latency performance against number of worker threads per GPU for GDS enabled or disabled
The results indicate that with GDS enabled, we see a gain in READ throughput performance, reduction in latency, and a reduction in CPU utilization.
RAPIDS cuDF Parquet Reader benchmark
RAPIDS cuDF Parquet Reader benchmark evaluates the read IO performance of common datatypes like Parquet and ORC when used with RAPIDS cuDF with GDS enabled and disabled to measure performance improvement.
During our benchmark, we saw a 7.2x improvement in read for Parquet files with GDS.
| Data type | Cardinality | Run length | GPU time GDS enabled | GPU time GDS disabled | GDS gain |
|---|---|---|---|---|---|
| INTEGRAL | 0 | 1 | 64.400 ms | 464.772 ms | 7.21 times |
Elbencho benchmark
Elbencho is an open source tool used for measuring file, object, and block storage performance across both CPUs and GPUs. The Elbencho tool is used for simulating the direct IO read operations with CPU, GPU, and GDS flags to demonstrate the Storage Scale performance.
In single-host testing with GDS, we achieved 37.5 GB/s, and in the three-node test, we saw only 50 GB/s because performance was storage-bound with NVMe SSDs. By increasing the number of SSDs per node, we believe we can overcome this limitation. The NVIDIA H100 GPU nodes include 16 NVMe SSDs for a four-time improvement over the tested A100 GPU nodes.
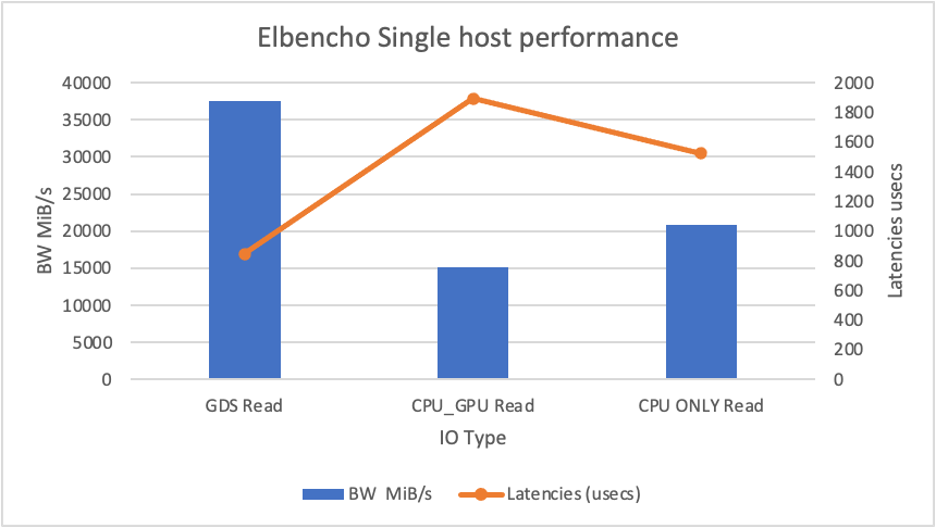
Figure 9. Elbencho benchmark for single host performance
The following graphic shows the Elbencho multihost distributed benchmark results. In this case, we used all three GPU nodes for simulating the distributed IO across the cluster.
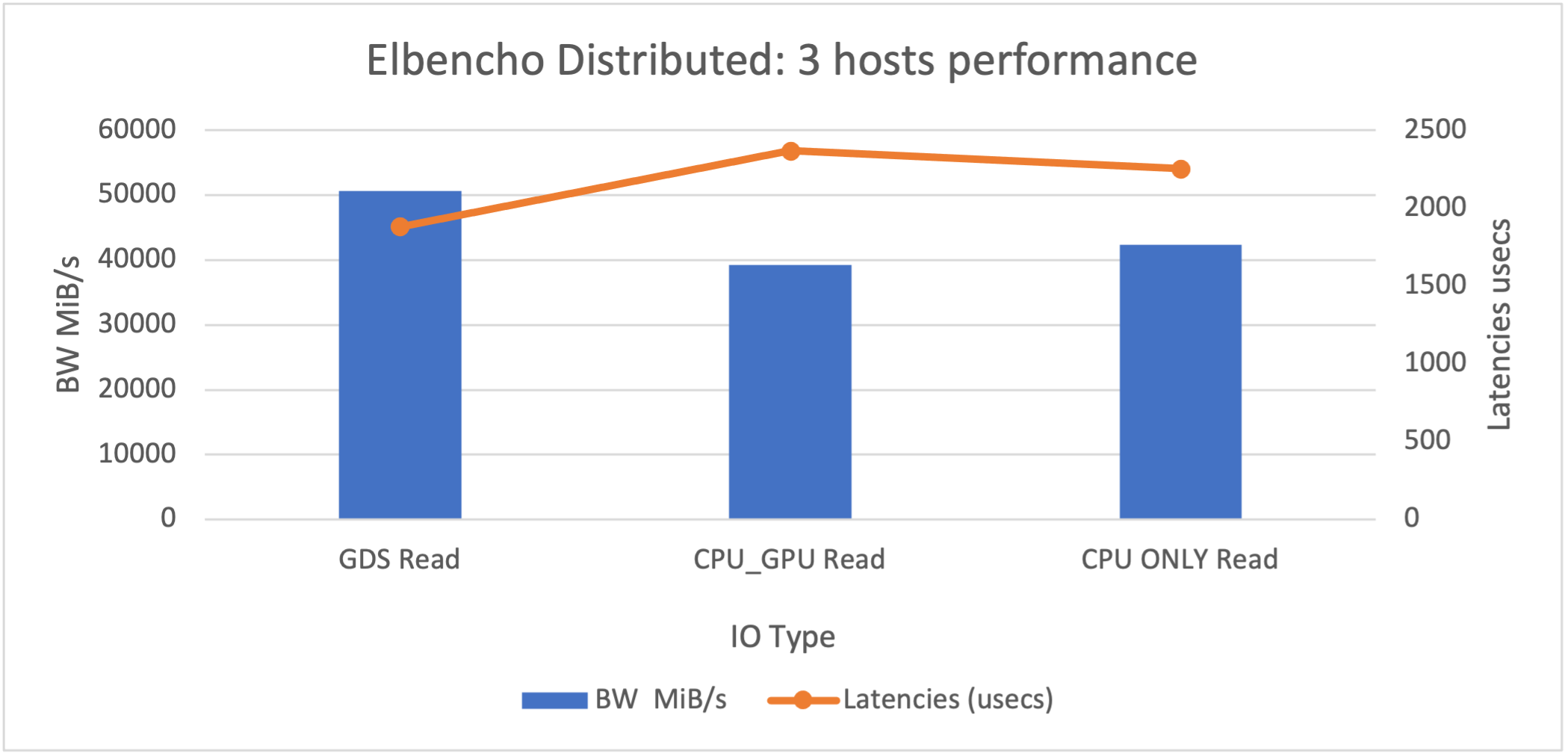
Figure 10. Elbencho benchmark for three-host performance Conclusion
Conclusion
By utilizing GDS, artificial intelligence and machine learning applications can run more efficiently because they maximize GPU performance without being limited by storage performance and run with lower TCO while running on hyperconverged clusters.
We’d like to acknowledge and thank the following team members from NVIDIA, IBM, and OCI for their contributions:
- Sanjay K Sudam (IBM)
- Douglas O’Flaherty (IBM)
- Sandeep Joshi (NVIDIA)
- Kiran Kumar Modukuri (NVIDIA)
- Harry Petty (NVIDIA)
- CJ Newburn (NVIDIA)
- Pinkesh Valdria (OCI)
To learn more about the GDS solution on OCI, reach out to your Oracle Sales representative to engage the Oracle Cloud Infrastructure Storage Specialist team.
For more information, see the following resources:
- Oracle Cloud Infrastructure GPU Instances
- NVIDIA Magnum IO GPUDirect Storage
- GPUDirect Storage support for IBM Storage Scale
- DeepCam Inference benchmark
- RAPIDS cuDF Parquet reader benchmark
- gdsio storage benchmark
