What does maximizing Oracle Cloud Infrastructure (OCI) services like Logging for ported or native OCI applications have to do with a book on how to get the most out of the CNCF’s Fluentd and Capgemini’s Agile Innovation Platform? This post shows you that the answer is more than you might think. It also demonstrates OCI free features and OCI’s ease of use.
OCI provides native services that allow you to perform logging, alerts, and a Service Connector Hub for passing log events on to non-OCI tools, such as third-party SIEM solutions. This option includes passing the log data out to another platform, including on-premises solutions supporting hybrid and multicloud situations.
If you port or develop applications to OCI, you ideally want to use the OCI native features to make things cheaper and easier. For ported solutions, that means configuring the collector agent if your application can’t log directly to OCI logging or through host OS solutions like Syslog. With everything configured, how do we prove all the configuration is ideal and working correctly? Running the application is the obvious answer, but it can take a lot of effort to create the right stimuli. Creating the failure events where the log event processing can really deliver value can be challenging.
Where it all comes together
Here, our book Logging In Action is connected. Fluentd, part of OCI Logging’s foundations, is designed to pull logs together and route them. It allows people to experiment with Fluentd simulation of logging events and generate new logs by replaying old logs and retimestamping or generating more synthetic events comes into its own. With such data, it becomes a lot easier to validate all the configurations.
The biggest gain is the ability to take an application log file and play it out as if it was the actual application. No need for the complexities of setting up the application and the tools to stimulate the application so that the wanted log events occur. Plus, no setting up and tearing down the scenario to repeat the events.
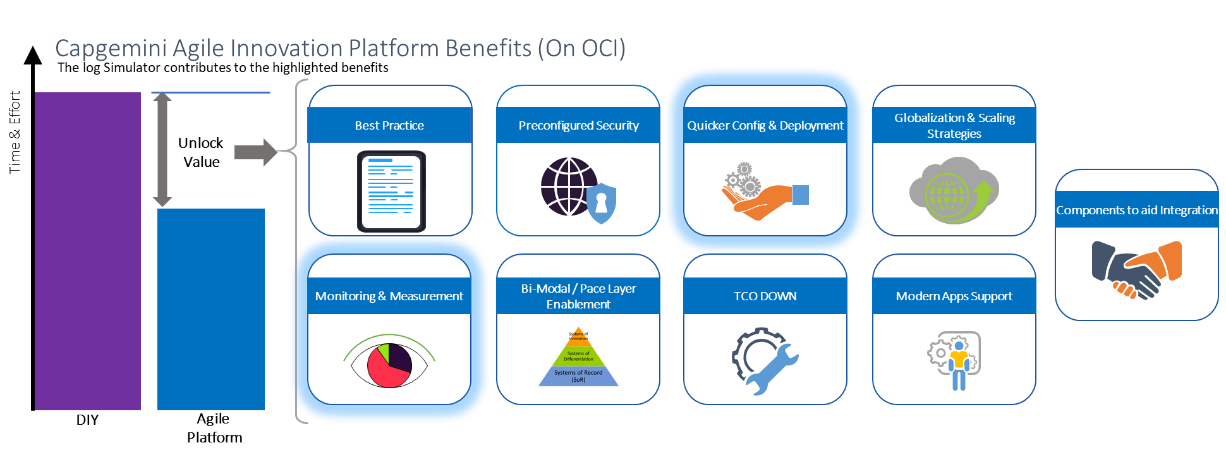 Figure 1: Benefits of Capgemini’s Agile Innovation Platform
Figure 1: Benefits of Capgemini’s Agile Innovation Platform
At Capgemini, we have been evolving a capability known as the Agile Innovation Platform (AIP). It takes the idea that, while infrastructure-as-code has made a revolutionary change in delivering environments, we can accelerate further by moving from code to parameterization, from lots of labor-intensive traditional testing to tune ops processes to feed simulation, along with a raft of design and implementation strategies
With AIP, we can generate complete environments covering WAF, API, Kubernetes clusters, Oracle Integration Cloud, and so on, with suitable VPNs, nets, and IP allocations through parameterization. AIP is a toolkit, so we can mix and match parts to address varying needs. As part of that toolkit, the log simulator’s role is to minimize or remove complex test setups to help tune the operational processes, such as alerting, log event detection, and log visualization. It ensures that logs are collected correctly and that we have configured Log Analytics to provide suitable views and alerts when we expect them. We keep replaying the previous log feeds through the environment until things meet expectations. For Capgemini, AIP allows us to deliver with greater agility on top of OCI. Ultimately, that translates to faster, better delivery, and total cost of ownership improvements for our customers.
Use case
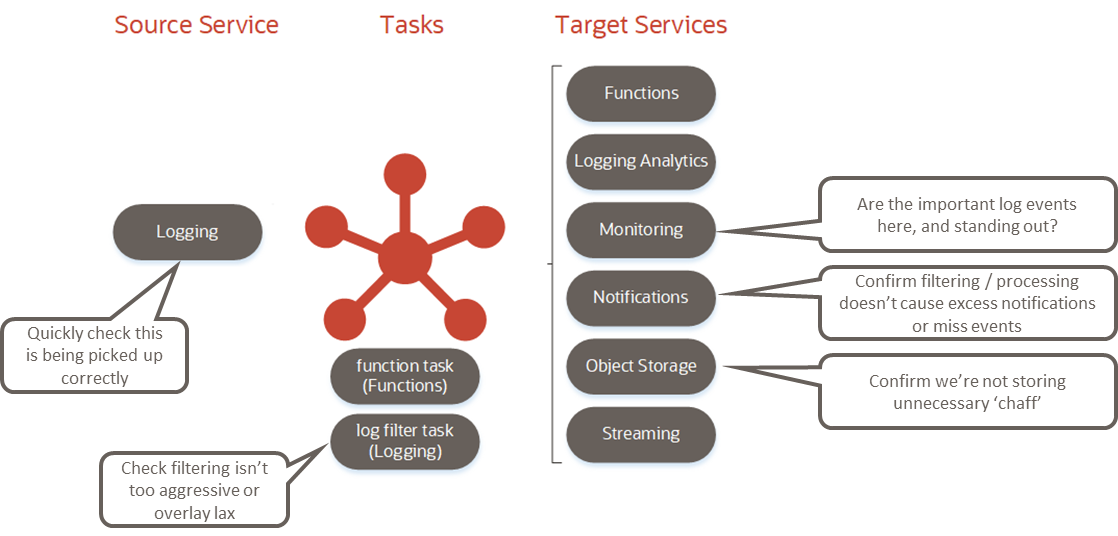 Figure 2: OCI native monitoring
Figure 2: OCI native monitoring
Hopefully, you can see the value of the utility. The tool and several basic configurations are free, and the book has more examples, but the setups that we’ve developed within Capgemini are part of the AIP offering. Let’s put the tool to work.
We can run the application in a couple of ways, either as a Docker image as a Groovy or Java application. Either way, we need to first create our always-free Linux virtual machine (VM). The most straightforward path follows the steps through the cloud UI.
After you sign in, the center panel has two tabs: Get Started and Dashboard. The Get Started tab has quick actions, which include creating a VM instance. To get a basic Linux VM running, follow this guided setup and remember to save the SSH keys.
With the VM established, sign in to the VM using SSH. Now, we can set up the environment by retrieving the binaries. You can accomplish this task by setting up Yum.
Some of these steps might require you to first change the file permissions to make the file editable (chmod a+rw <filename>) and then modify some of the commands by prefixing the command with sudo to give the relevant privileges (for example, sudo yum install docker-engine). If you want to try the Groovy implementation, install GIT and Groovy with the commands sudo yum install git -y and sudo yum install groovy -y. Alternatively, to run the Docker version, retrieve the Docker image of the log simulator tool with the command sudo docker pull mp3monster/log-simulator:v1.
The final step is to run the Docker image. Use the command sudo docker run mp3monster/log-simulator:v1, and you can see Docker following the preparation activities and then running. This command results in the configuration outputting the log events in JSON format to the console (stdout). If you’re familiar with Docker, you can start overriding and experimenting with the configuration.
With Groovy and Git installed, to run the tool natively in a suitable folder, such as home (cd ~), we need to retrieve everything with git clone. We have all the assets to perform a simple run. The assets include a few convenient shell scripts that work from within the LogGenerastor folder, which means first moving the folder with cd LogGenerator and then running ./logSourceSimulator4.sh to see a simple log generate to stdout. Inside the shell script, we’re simply invoking the Groovy code and passing details of the configuration file.
As you can see, we can create log outputs. Through the properties file, the tool can be configured to read many different types of log files, play parts or all of them, and play the logs back with revised timestamps. The replay means that logs are written to the log file at the defined intervals or running with a multiplier of real-time with the same intervals between each log entry made to loop.
This tool becomes powerful when we have a historical log that includes error events. We can keep running the log through until we’re happy with the log error detection and handling through Oracle Cloud Infrastructure Logging, dashboards, and Oracle Log Analytics.
Where to go from here
What does this all add up to? Innovation isn’t always about the big disruptive, game-changing ideas; the successful ones come along once a generation. The accumulation of smaller ideas can be significant, and building those smaller ideas is much easier. If you look at all the free resources from OCI, you can develop these smaller innovations without cost, from VMs and databases to thousands of free compute seconds of serverless capacity every month. We just illustrated one and used OCI to help with its development.
Let me draw a parallel. Ford Model T and assembly lines caused huge disruptive change to the car industry and propelled Ford to a world-class company. Perhaps the next major disruptor to succeed is Tesla. Between these two, there have been plenty of failed attempts like DeLorean.
Now, consider the adoption of the ideas of total quality management (TQM) by Japanese manufacturers, such as Toyota and Nissan. TQM focuses on everyone contributing to constant improvement. In the 60s and 70s, Japanese cars weren’t well thought of. In 1970, Toyota only had 2% of the US car market versus Ford’s 28%. Those continuous improvements progressed, and Toyota began outselling Ford in the US by 2007.
We can use the same argument for the Oracle database every year incremental development, not throwing everything out to start again with Hadoop or NoSQL. It’s the same idea as Capgemini’s AIP. It might not be the next big thing, but it is innovating by bringing lots of good, complementary ideas to deliver something far more effective for our customers. Bottom line, talk to Capgemini about AIP, buy the book, use OCI to innovate.
If you want to know more, see the following resources:
- Log generator docs
- Logging in Action book
- Phil Wilkins’ personal MP3Monster blog
- Agile Innovation Platform
