We’re excited to announce a new release of Oracle Cloud Infrastructure (OCI) Data Integration. This release expands connectivity options, transformation capabilities, and the integration between it and OCI Data Flow.
Cloud native, serverless integration
As a refresher, OCI Data Integration is a recently launched, cloud native, fully managed serverless extract, transform, and load (ETL) solution. Organizations building data lakes for Data Science on Oracle Cloud and departments building data lakes and data marts using Autonomous Databases can gain great business value from our solution that simplifies, automates, and accelerates the consolidation of data for use.
Data Integration is graphical, providing a no-code designer, interactive data preparation, profiling options, and schema evolution protection. Everything is powered by Spark ETL or ELT push-down execution. If you’re not familiar with this new service, check out this blog to find out more: What is Oracle Cloud Infrastructure Data Integration?
Data Integration is available in all OCI commercial regions.
New features
We’ve expanded the depth of ETL options to help you more effectively design data flows, tasks, and overall processes through newly provided operators and transformations.
Operators come into play in the graphical user interface as you build a custom data integration flow diagram. They help you select, filter, and shape the data.
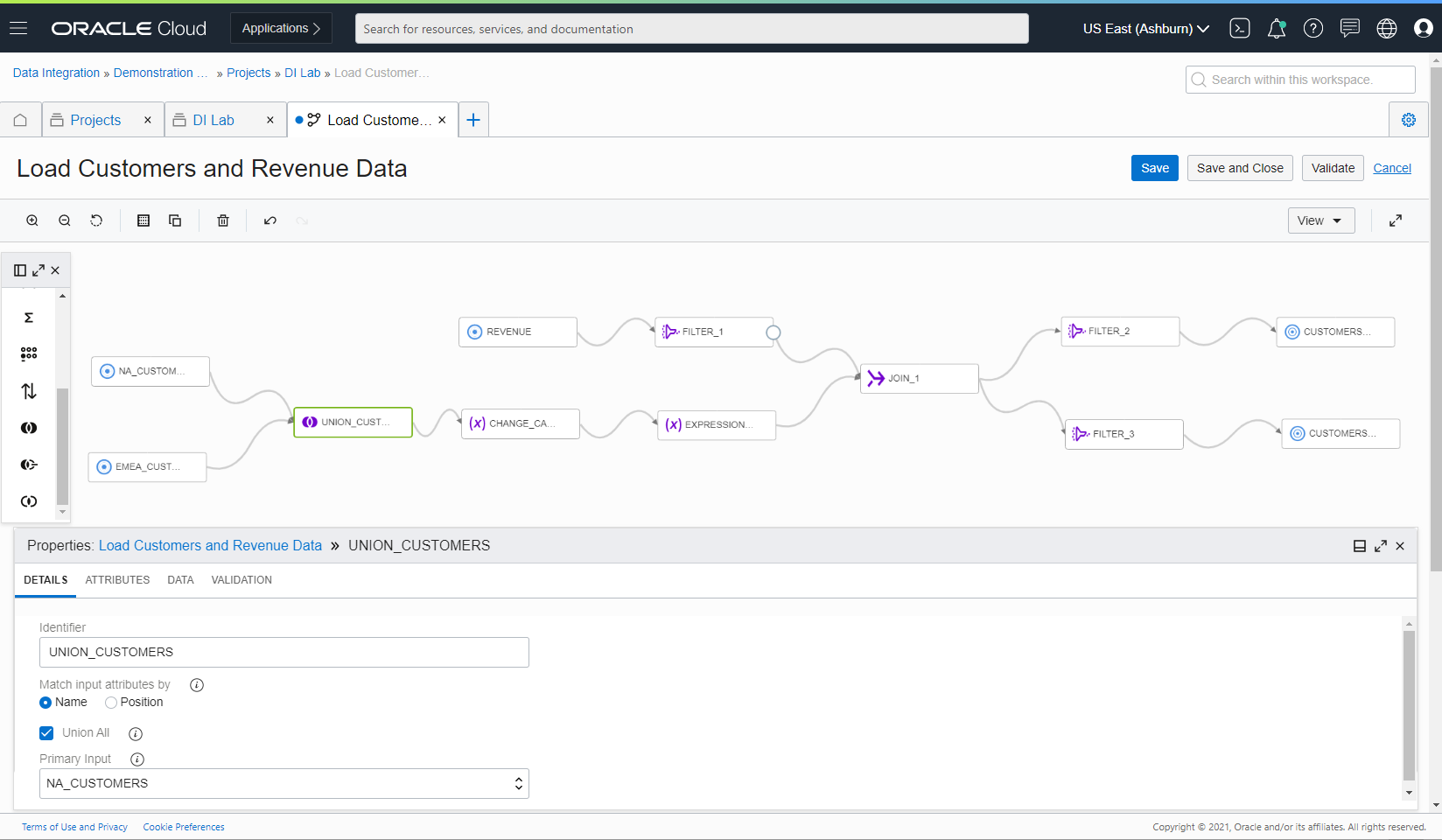
Figure 1. Data Flow editor
This release includes the following new operators:
-
Union: Combines multiple streams of data into one.
-
Minus: Compares two data entities and returns the rows present in one entity but not present in the other entity.
-
Intersect: Compares two or more data entities and returns the rows present in the connected entities.
These operators allow you to quickly and easily express complex transformations. Check out the full review of Data Integration operators.
Data Integration includes an interactive Data Xplorer that displays a sampling of data that automatically updates as you apply transformation operations. Data Xplorer helps you validate the impact of these transformations, uncover data issues, and debug or troubleshoot possible failures before a task runs.
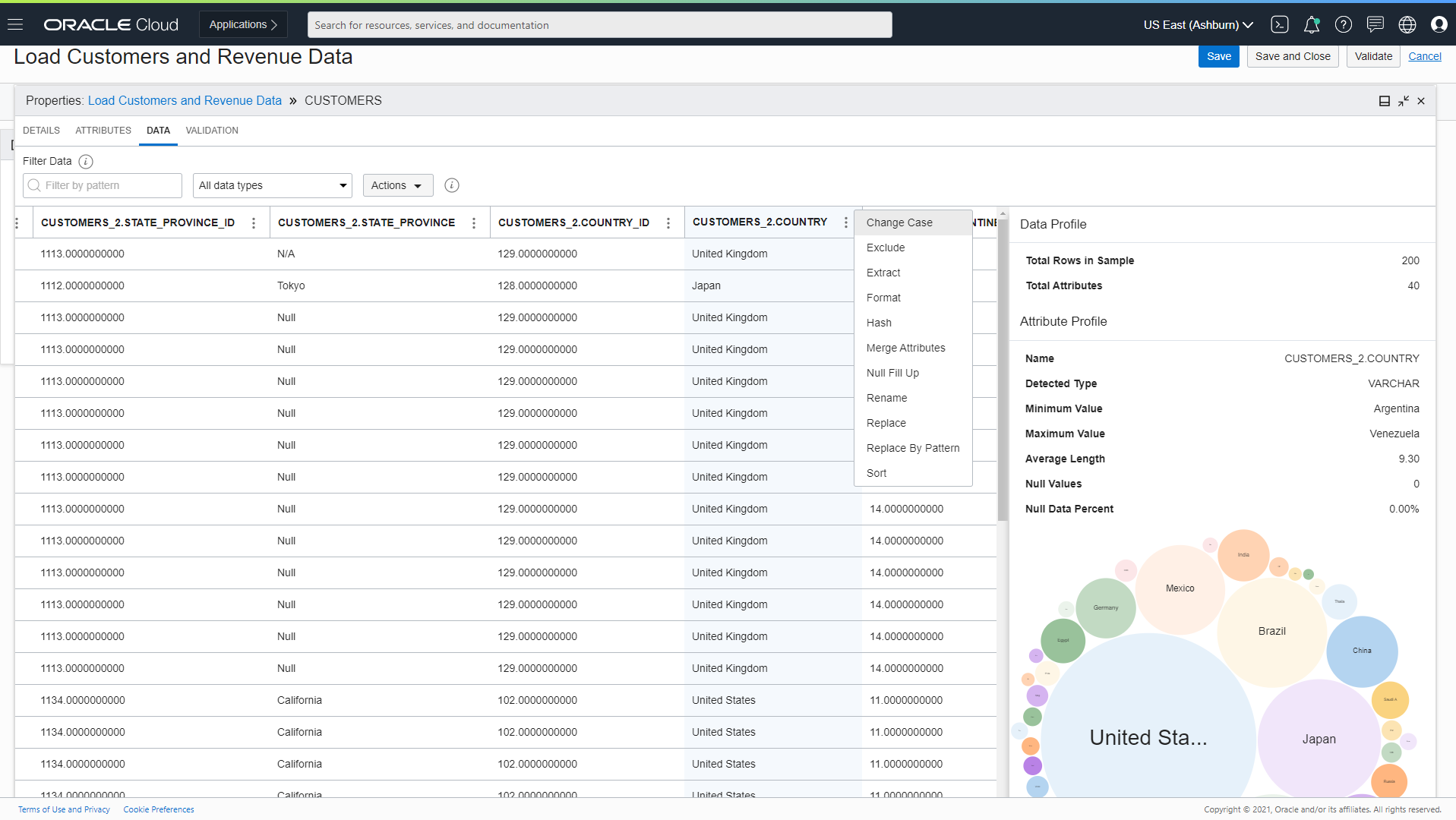
Figure 2. Data Xplorer transformations
Data Xplorer includes the following new transformations:
-
Create Unique ID: Adds an attribute to a dataset. The values for this attribute are filled with a 128-bit universally unique identifier (UUID).
-
Replace by Pattern: Lets you enter a regular expression to search and replace data values in an attribute and adds an attribute to hold the transformed data.
For more insight into transforming data with Data Integration, see the documentation page.
New connectivity is always exciting. We’re happy to have Amazon Web Services (AWS) Relational Data Store (RDS) for Oracle, MySQL and Microsoft SQL Server, Microsoft Azure SQL Database, and the support for compressed files for Object Storage on OCI. See the complete list of supported data assets.
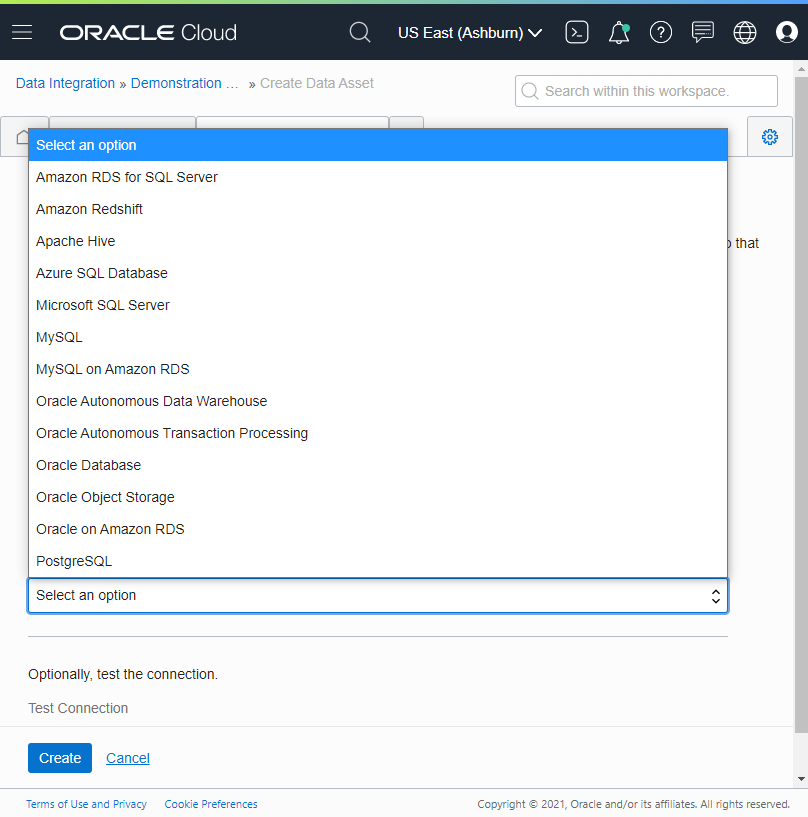
Figure 3. Data Asset types
We’ve also enhanced the user experience. You can now view recent activity in your workspace from the Home tab, providing better readability, a good view into what you’ve been doing, and the capability to go back quickly to the last items you were working on!
Integration with Data Flow
Lastly, we want to note that we’ve enhanced the integration between OCI Data Integration and OCI Data Flow. Data Flow is a fully managed Apache Spark service that performs processing tasks on massive data sets without infrastructure to deploy or manage. This rapid application delivery allows developers to focus on app development, not infrastructure management.
Check out Publish an Oracle Cloud Infrastructure Data Integration task to Oracle Cloud Infrastructure Data Flow to learn how the services complement each other.
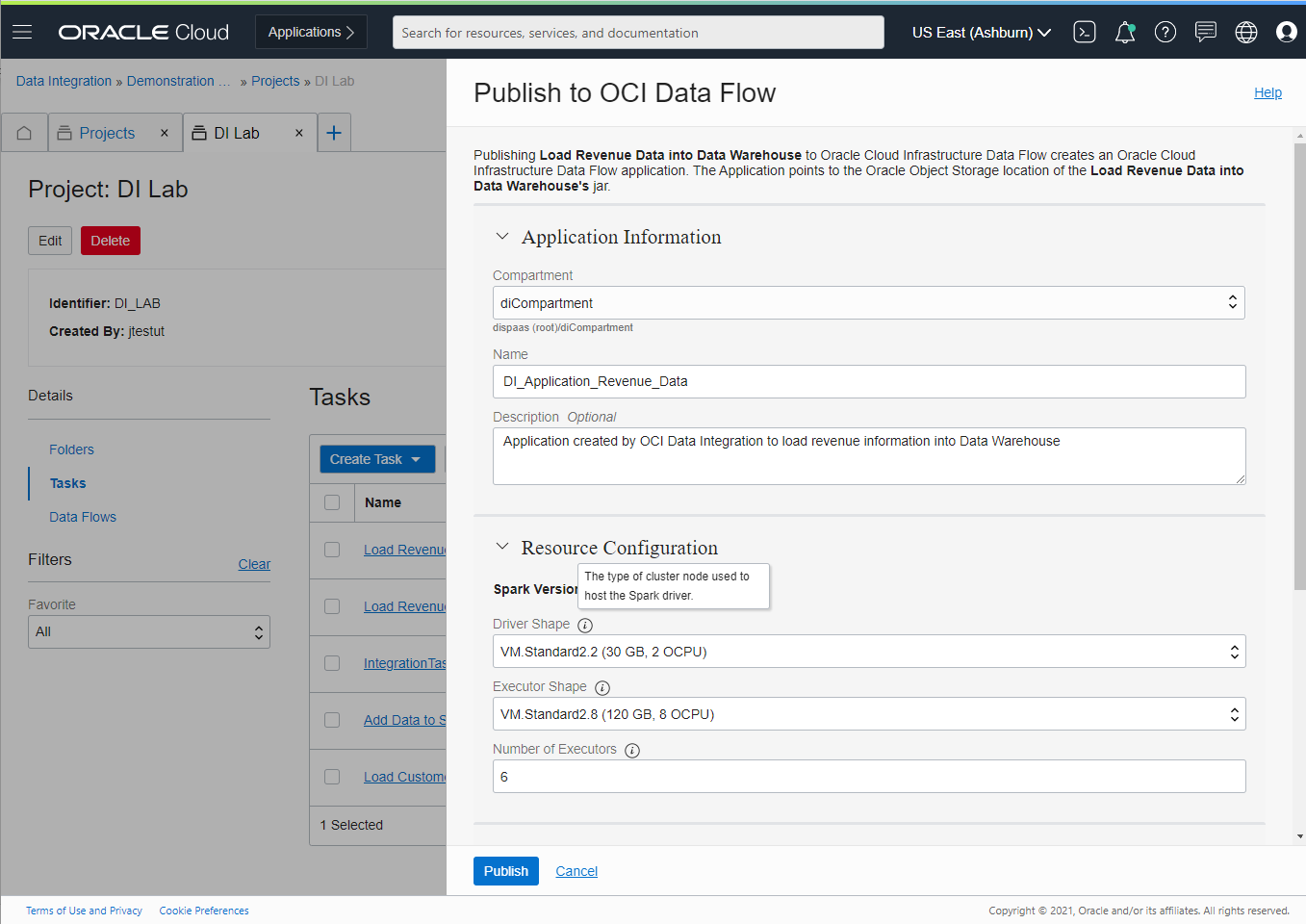
Figure 4. Publish Data Integration task into OCI Data Flow application
The integration between Data Integration and Data Flow now supports private endpoints to access the private network where your data sources are hosted. This access expands the options for including and using data sources that are only accessible privately. You now have more options for using the two services hand in hand as you work with data.
Want to know more?
Organizations are embarking on their next-generation analytics journey with data lakes, autonomous databases, and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to quickly and easily ingest, prepare, transform, and load their data into Oracle Cloud Infrastructure. Data Integration’s journey is just beginning! Try it out today!
For more information, review the Oracle Cloud Infrastructure Data Integration documentation, associated tutorials, and the Oracle Cloud Infrastructure Data Integration blogs.
