Issac Asimov, pivotal science-fiction author 1939–1992, imagined a world intimately integrated with artificial intelligence in I, Robot. While current AI implementations have a long way to go before they reach the level of sophistication in the novel, they do influence our daily, digital lives. Out of billions of different algorithms in the world, people colloquially refer to AI recommendation engines when they talk about “the algorithm.” These AI systems are ubiquitous across social media, entertainment media streamers, and e-commerce companies. Given the seemingly endless number of choices available for media and products, it follows that consumers need some sort of automated guide to find resources relevant to their interests.
The demand for recommendation engines is growing at an incredible rate, with some market research groups estimating a compound annual growth rate (CAGR) of 40% from 2017-2022. Facebook, one of the industry leaders in this space in both research and implementation, recently incorporated deep learning techniques into their engine. The deep learning recommendation model (DLRM) is a flexible system that makes key breakthroughs in breadth and computational performance.
What DLRM does
The high-level goal of the model is to accurately predict whether a person being presented with content clicks that content. This prediction can be generalized to any situation with a binary result, such as whether a person listened to a song, viewed a video, or purchased a product. The value representing this result is referred to as the label in supervised learning. The model is trained by looking at the rest of the data provided, making a prediction for the label, and then checking itself for correctness against the actual label.
DLRM supports up to 39 data columns, comprised of 13 integer columns and 26 categorical columns. Data scientists can define the integer and categorical columns based on their dataset. Typically, the 13 integer columns are filled with various forms of counts, such as number of followers or number of days since a customer last made a purchase. The categorical columns must be some type category such as music genre or clothing product type. DRLM is flexible, so any group can apply their data to fit into these fields.
Predicting behavior with probability
The key technological advancement with DLRM, as highlighted by the name, is the incorporation of deep learning techniques. As we’re aware, human interests are influenced by a network of experiences and memories stored within our brains. Say that you’re trying to create a series of true or false questions to determine the preferences for any individual. The question chain would quickly become messy, confusing, and wrong more often than it is right. An overly simplified explanation of deep learning is that it uses probabilities to make predictions based on a landscape of potential influences rather than following a predefined path. This methodology fits better when trying to predict human preferences, which takes input from an infinite combination of factors.
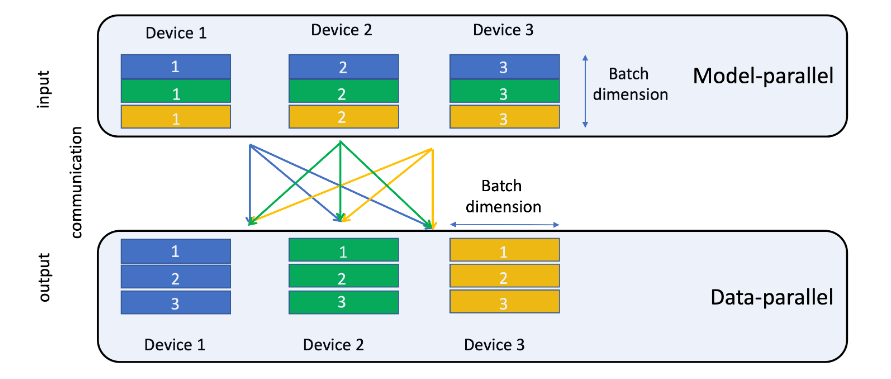
The challenge with incorporating deep learning techniques is that they exponentially expand the required system resources for training. The increase is so substantial that without modification the models are too large to fit in each GPU’s memory. The research team at Facebook needed to implement their own system for assigning memory resources to train the model.
The existing methodology was to take each individual batch of samples used in the training, run them on separate GPUs, and aggregate the result after completion. By that method, eight GPUs run eight separate batches of samples. Each batch of samples for DLRM, however, would require more resources than are available on each GPU, so the team split the work up differently. The system was designed so that the model runs across all available GPUs. With the model split across all GPUs, each one performing a different computational task, batches of samples are split and processed appropriately. Instead of eight GPUs running eight separate batches at the same time, one batch is run across eight GPUs.
Try it yourself
Fortunately, the researchers handled the complexity of this challenge and made it available to the public. You can use the open source library in multiple ways, and I recommend the NVIDIA NGC container that comes preconfigured with a quick start guide. As highlighted in the paper, it’s rare to find a public dataset of consumer data, but Criteo has made public their Terabyte dataset, which is used as an example in both the NGC container and the white paper. This algorithm is compatible with both the V100 BM.GPU3.8 and A100 BM.GPU4.8 shapes in Oracle Cloud Infrastructure. You can quickly deploy an instance and get started with the example. When you’re ready to experiment with your own datasets, use the Criteo Terabyte dataset as a template. Recommendations are a powerful tool for a wide array of businesses, and DLRM is flexible enough to serve any type of categorical consumer data.