
Many cloud providers have centered their engineering and product focus on cloud native applications. While this focus can provide fantastic elasticity and flexibility for new applications, it leaves the onus on customers to adapt their existing applications for the cloud environment. We’ve heard from many customers who have set out to make the transition to cloud, only to be dismayed by the extent of rearchitecting and reengineering required.
At Oracle, we’ve taken a fundamentally different approach. We understand the cloud, and we understand the enterprise, and we know that it is possible to provide a seamless transition for existing applications without compromising a world-class experience for cloud native applications.
Oracle Cloud Infrastructure (OCI) launched with support for bare metal servers, addressing the needs of customers who require non-virtualized, dedicated compute for their critical applications. We provide Dense-IO shapes for applications that require dedicated, local NVMe storage, and we’ve brought the best Oracle database system in the world, Exadata, to the cloud without compromising performance or functionality.
Now that we’ve addressed compute, storage, and database, it’s time to tackle the network. OCI is the first major cloud vendor to support Layer 2 (L2) network virtualization, allowing applications written for physical networks to run without alteration on Oracle Cloud.1
Frankly, this is a big deal. Applications written for on-premises often depend on features of the physical network for monitoring, availability, and scale. Without reengineering (and often substantial rearchitecting), they’re incompatible with most clouds. By virtualizing the network at a lower level, we can offer compatibility for databases, network appliances, and virtualization environments.
Our first major offering that takes advantage of this technology is our Oracle Cloud VMware Solution. It demonstrates how our innovation in cloud infrastructure allows us to offer uniquely compelling products to our customers.
We’re proud to ship L2 network virtualization on OCI and we’d like to show you how it’s done. First, we discuss typical network virtualization to provide background. Second, we discuss how this can create compatibility and availability issues for applications written for physical networks, such as VMware. Finally, we go into detail about how we evolved our virtual networking to support L2 and used it to provide an exceptional VMware experience for our customers.
Typical cloud virtual networks: L3 virtualization
To understand the limits of most cloud virtual networks, let’s briefly discuss how L3 network virtualization works on OCI. Because this blog is intended as a high-level overview, this simplification omits details about routing, security policy, and network peering.
Every compute host in our data centers is connected to an off-box virtualization device where our network virtualization stack runs. This virtualization device has an IP address on the physical network, sometimes referred to as the substrate or underlay network. When customers launch Compute instances and attach virtual interfaces to them, the compute and networking control planes track their placement in the data center and assign each virtual interface on the same host a unique interface identifier. When a customer wants to use an IP address from their virtual network on a virtual network interface card (vNIC), they call an API so that the virtual networking control plane can assign the IP to the vNIC.
The control plane pushes this information to the virtualization devices, and the data-path uses it to send and receive traffic on the virtual network. When a packet is sent from a virtual interface, the data-path looks up the virtual cloud network (VCN) associated with the sending interface. Then it retrieves a map between IP addresses in the VCN and the interface to which they’re assigned. Finally, it uses the destination virtual interface to determine how to encapsulate and send the packet.
When we encapsulate the packet, we wrap the original packet in a new packet header for sending on our substrate network. This packet header includes the physical network IP addresses and OCI-specific metadata, including the sending and receiving virtual interface IDs.
// Determine the virtual cloud network based on the sending vNIC vcn = src_vnic_to_vcn_map[src_vNIC]; // Lookup the interface based on the VCN and destination IP dst_vNIC = vcn_and_dst_ip_to_vnic_map[<vcn, dst_IP>]; // Encapsulate the packet and send to the physical destination: encapsulate_and_send(pkt, dst_vNIC.physical_ip, dst_vNIC.interface_id);
Figure 1. Pseudocode for sending overlay traffic.
Let’s go over an example to see how this works. In Figure 1, we have two hosts and their associated virtualization devices. The physical network is a 10/8 network, and our physical networking devices have IPs 10.0.0.0 and 10.0.0.1. The compute and virtual networking control planes have placed vNICs on these devices: vNICA (on H0) and vNICC (on H1) are part of the same VCN, V0. Other vNICs for other VCNs have also been placed on these devices. We can now trace the life of a packet through our L3 virtual network in the following steps:

Figure 2. Sending traffic in the L3 overlay.
-
A packet is sent from vNICA. The packet has vNICA’s IP address as its source IP (192.168.10.10). Its destination IP is 192.168.20.20.
-
The packet is processed and sent on. When the packet arrives at the off-box-virtualization for H0, it knows it was received from the host and uses the interface_id to look up which VCN it’s being sent on. The destination vNIC is looked up based on the destination IP in the original header (192.168.20.20). This mapping includes the physical device where the vNIC has been placed (in this case, 10.0.0.1). So, we can encapsulate the packet with a tunnel header and send it on without altering the original packet.
-
The packet is received at 10.0.0.1. When the packet is received, metadata in the tunnel header about the sender, and the target vNIC is used to validate the sender and ensure delivery to the proper vNIC, even if two vNICs on the same host are from different customers and happen to have the same overlay IP.
-
The packet is delivered to H1. The tunnel header is removed, leaving the original packet to be delivered to the host.
We can observe two things about this process. First, the destination of the packet in the physical network is based entirely on the destination IP; the MAC is effectively immaterial. Second, the sender has to know what vNIC the destination IP is mapped to and where it exists in the physical network.
Now, you may be wondering – “What about ARP?”. As a quick refresher, ARP is the Address Resolution Protocol, and it is used with IPv4 to map an IP address to its MAC address when sending IPv4 traffic between interfaces in the same broadcast domain. When a sender notices that a destination IPv4 address is on the same broadcast domain, it needs to know the MAC address to write into the Ethernet header. If it doesn’t already have an entry in its ARP cache, it broadcasts an ARP request of the form “who-has dest IP tell source IP”. Critically, an ARP message is not an IP packet – it is a broadcast L2 packet.
So, how does it work in our virtual network? If there is no IP header, and customer instances need ARP to learn the MAC for sending packets, how do the ARP requests get broadcast and responded to? The answer is that they don’t. Since we know ahead of time what interface is associated with every IP address in the virtual network, the virtualization stack at the sender can immediately respond to the ARP request as though it was the appropriate host, without it ever leaving the box. We also use this trick to flatten the virtual network so we don’t need any routing between subnets; when the guest intends to send traffic outside the subnet it will ARP for the address of its default gateway and the virtualization stack can respond with a pre-canned ARP reply. When the actual packet is received, the data-path sends it directly to the destination vNIC. The default gateway is an illusion – it doesn’t exist. This allows all vNICs in the overlay to communicate directly and simplifies implementation, operation, and performance.
In fact, you can verify this for yourself: If you tcpdump an interface on Oracle Cloud Infrastructure (“OCI”) (or other cloud virtual network) and send an ARP from another instance in the same subnet, it will never arrive. In general, you will never see an ARP request originating from another interface (though some clouds, like OCI, monitor interface health by sending synthetic ARP requests just to verify that they are responded to).
For most applications, these limitations are absolutely fine: the vast majority of modern applications only use IP-based traffic, customers and applications are content to only use a single MAC per interface, and only MACs and IP addresses that have been explicitly assigned or attached to a specific interface via API. However, these limitations break a number of on-premises applications that leverage the flexibility and capabilities of L2 networking.
Why some applications can’t live without L2
Many applications written for physical networks, particularly ones that work with clusters of compute nodes that share a broadcast domain, use features from on-premises that aren’t supported in an L3 virtual network. The following six examples highlight the complications that not having that support can cause.
-
Assignment of MACs and IPs without a preceding API call. Network appliances and Hypervisors (such as VMware) weren’t built for cloud virtual networks. They assume they are able to use a MAC so long as it is unique and either get a dynamic address from a DHCP server or use any IP that was assigned to the cluster. There is often no mechanism by which they can be configured to inform our control-plane about the assignment of these L2 and L3 addresses. If we don’t know where the MACs and IPs are, the L3 virtual network doesn’t know where to send the traffic.
-
Low latency reassignment of MACs and IPs for high-availability and live migration. Many on-premises applications use ARP to reassign IPs and MACs for high availability – when an instance in a cluster or HA pair stops responding, the newly active instance will send a Gratuitous ARP (GARP) to reassign a service IP to its MAC or a Reverse ARP (RARP) to reassign a service MAC to its interface. This is also important when live-migrating an instance on a hypervisor: the new host must send a RARP when the guest has migrated so that guest traffic is sent to the new host. Not only is the assignment done without an API call, but it also needs to be extremely low latency (sub-millisecond). This cannot be accomplished with HTTPS calls to a REST endpoint.
-
Interface multiplexing by MAC address. When hypervisors host multiple VMs on a single host, all of which are on the same network, guest interfaces are differentiated by their MAC. This requires support for multiple MACs on the same virtual interface.
-
VLAN Support. A single physical VM Host will need to be on multiple broadcast domains as indicated by the use of a VLAN tag. For example, ESX uses VLANs for traffic separation (e.g. guest VMs may communicate on one VLAN, storage on another, and host VMs on yet another).
-
Use of broadcast and multicast traffic. ARP requires L2 broadcast, and there are examples of on-premises applications using broadcast and multicast traffic for cluster and HA applications.
-
Support for Non-IP traffic. Since the L3 network requires the IPv4 or IPv6 header to communicate, use of any L3 protocol other than IP will not work. L2 virtualization means that the network within the VLAN can be L3 protocol agnostic – the L3 header could by IPv4, IPv6, IPX, or anything else – even absent all together.
Of course, many on-premises virtualization solutions such as VMware provide their own network virtualization (VMware uses NSX), but it’s turtles-all-the-way-down: the host management and controller VMs run directly on the network without NSX virtualization.
VMware on OCI: The customer in control
So, if VMware requires support for L2 networking, how do clouds that only offer L3 virtual networks empower customers to run their VMware deployments on the cloud? Typically, they don’t. When you hear about VMware on other clouds, you’re likely being offered a “managed” solution. With these services, the cloud provider owns and operates the VMware deployment.2 In many cases, this allows them to treat the deployment as their infrastructure, leverage physical networking, and potentially alter the implementation to translate network calls into API calls.
But note what is lost for the customer – the cloud provider retains root access and administrative control, and it is they, not the customer, that decides which software versions to run and when to perform patching and upgrades.
These compromises mean that many customers’ existing tooling, automation, and even VMs may be incompatible with managed VMware offerings. Despite a promise of lift-and-shift compatibility and simplicity, the customer is still asked to do substantial work to take advantage of the cloud.
At OCI, we took a fundamentally different approach – We are committed to solving hard problems so customers can migrate their applications without re-architecting or sacrificing control and visibility. With Oracle Cloud VMware Solution, customers launch VMware clusters directly on OCI bare-metal instances with L2 virtual networking. The customer has total control over the cluster once it has been setup by us: they have the only administrative access to the cluster and its hosts, they determine patching and upgrades, and they select the software components and their versions. Instead of the customer’s VM’s on the cloud’s VMware, L2 networking allows us to offer the customer’s VMware, on the cloud.
How we evolved OCI to support L2 networking
OCI isn’t the first vendor to offer L2 virtual networking. VXLAN is a popular L2 overlay protocol and NSX is an L2 virtual network. But we’re the first to offer it as an integrated Virtual Cloud Network and it presents a number of particular constraints and challenges. Let’s talk about how we had to evolve our product and architecture to accomplish this task.
Subnets and VLANs
It’s important to note that an L2 virtual network isn’t simply a superset of the functionality provided in an L3 virtual network. It’s not L3 + ARP. The semantics are different. In an L3 virtual network, packets are delivered based on the destination address in the L3 header of the customer’s packet (the destination IP). In an L2 virtual network, packets are delivered based on the destination address in the L2 header of the customer’s packet (the destination MAC). This distinction is critical: it means we can send and receive traffic on an L2 network that doesn’t even have an L3 header (such as ARP), or that has an L3 header we don’t know how to parse (such as IPX).
We don’t want to risk changing the behavior of existing networks or complicate the customer experience for those that don’t need L2 features. Today’s customers break up their VCN into multiple subnets, each of which corresponds to a single CIDR block and each of which is a segment of an L3 virtual network. For L2 networking we introduced the VLAN as a corresponding construct. In a subnet, packets are delivered based on the destination IP found in the L3 header. In a VLAN, packets are delivered based on the destination MAC found in the L2 header.
Rethinking the architecture
To provide L2 virtual networking, we have to change not only what we use to deliver packets (MAC instead of IP), but also how we know it. We can’t move down one level of the OSI model and replace a <VCN, dest_IP> lookup for a <VCN, dest_MAC> lookup, because we need to support the dynamic use and migration of MACs unknown to the system. We have to learn their location and provide a customer model of a switch.

Figure 3. Customer logical view of V-Switch.
The first step is changing what the control plane tells the data plane. Instead of the control plane knowing the location of every IP on every host, or even the location of every MAC, the only thing we know for certain is which interfaces are attached to a given VLAN. So, for every vNIC on a VLAN, the control plane informs it about every other vNIC on that VLAN and its associated physical address and interface ID.
// L2 Broadcast Domain Set broadcast_vnic_set = VLAN_to_VNIC_MAP[<VCN, VLAN>];
With this list, we can solve for broadcast and multicast traffic: we can implement L2 broadcast as a series of overlay unicasts. In other words, if we receive an L2 header with a broadcast MAC, we iterate over every vNIC on the VLAN, excluding the sender, and encapsulate and send the packet.
This process creates a multiplicative effect on the number of packets and the total consumed bandwidth. For this reason, when a packet is sent as a broadcast in the overlay, we multiply by the number of destinations in the broadcast domain when enforcing bandwidth and packet throttles.
if is_broadcast(pkt.l2hdr): foreach vNIC in broadcast_vnic_set: encapsulate_and_send(pkt, vNIC.physical_IP, vNIC.interface_ID)
For unicast packets, we need to learn the association between MAC and vNIC and implement a virtual switch for every vNIC on a VLAN. When traffic arrives at a VNIC on a VLAN, we update the switch to associate the source MAC with the source interface found in the encapsulating header. So, when we see that MAC as a destination, the switch knows which interface to send it to.
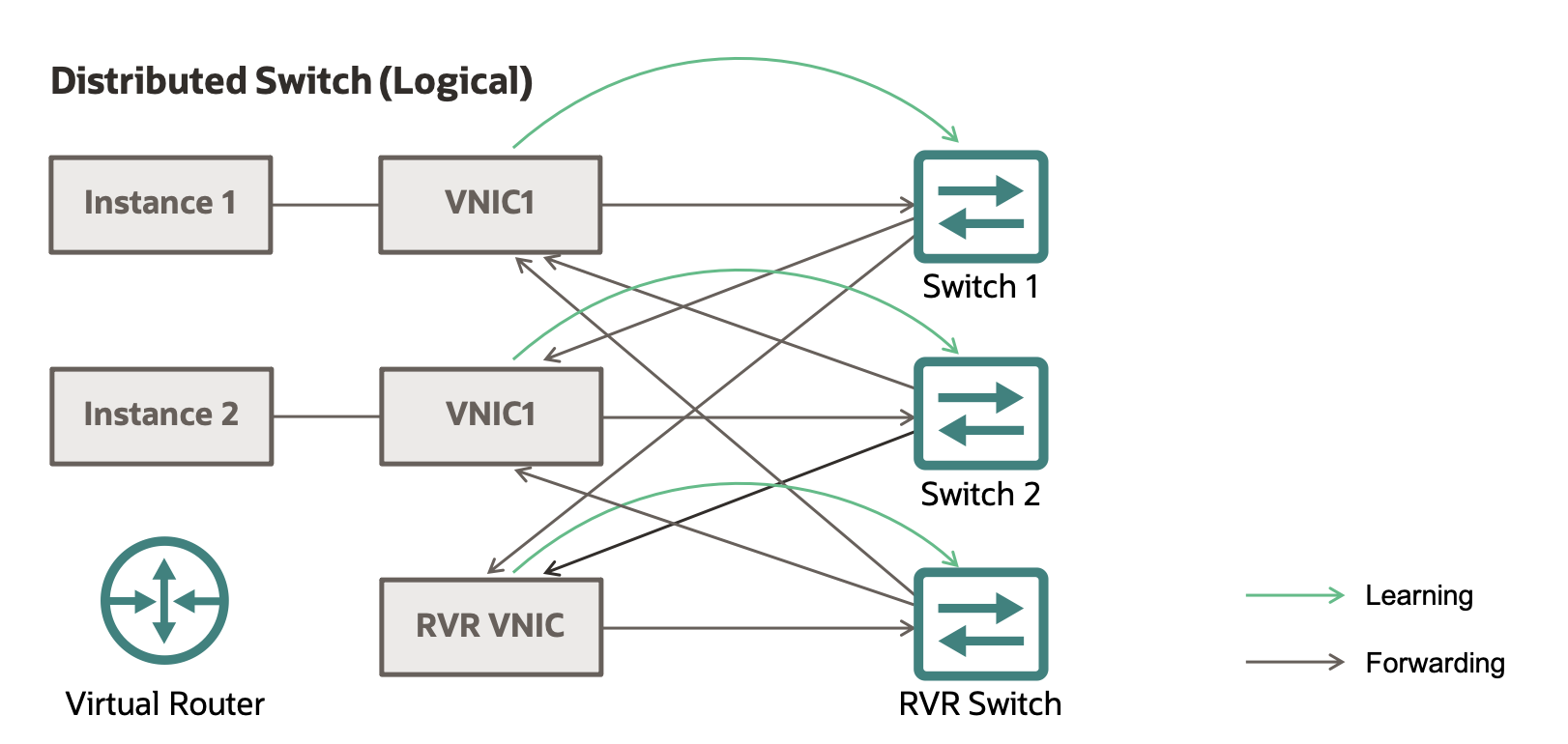
Figure 4. Distributed switch (logical)
This is exactly what a physical switch does when it learns the switch port for each MAC. The major difference is that, instead of learning a physical port, we’re learning a tunnel end-point and instead of a central switch architecture, each interface maintains its own switch state for scale and latency. In the event that an interface sends a packet with a destination MAC that our switch doesn’t have an entry for, we flood the packet to every interface (treat it as a broadcast) to ensure it reaches its destination and hope that a subsequent response packet will allow the switch to learn the location of the MAC on the VLAN.
There is an interesting subtlety in that, when we send a packet, we don’t send it to the corresponding switch of the destination interface, we send it directly to the interface and then update the switch based on any learned associations out of band. The reason for this is that, since each switch maintains its own tables, we have the possibility that (for a brief period of time), the sending and receiving switches have different state. We don’t want to perform switching at the source only to have the destination switch re-evaluate the destination interface and send it on. This would have the potential to lead to loops (bad), as well as ambiguity when enforcing a Network Security Group policy that is interface-based. If a customer has a policy that only allows traffic to a particular vNIC and the remote switch redirects the packet so that it is delivered to an unauthorized interface, we’ve broken our promise to the customer. Only by sending directly to the interface and skipping remote switching can we be certain that the packet is delivered to an authorized recipient.
At this point, we have all that we need for a viable L2 overlay network to send and receive traffic: the guest’s operating system will send and receive ARP requests to learn the mapping between IP/MAC, and our system will faithfully deliver these ARP requests to every interface in the broadcast domain, learning the MAC/Interface map along the way. When an instance needs to move a MAC (by sending a RARP), or an IP (by sending a GARP), the switches will observe the broadcast packet and update their state and the customer instances will also see the packets and update their ARP caches as appropriate.
However, there is one major issue we have yet to address: communication outside the VLAN.
Communicating with L3 networks
Recall that for an L3 virtual network, we need to know the location of an IP address in order to send a packet, and we get that information from our centralized control-plane which tracks the placement of compute instances and their associated virtual interfaces. For an L2 network, only the guest instances know the location of the IPs because they have been learned via ARP and stored in their ARP cache. Furthermore, only the data-plane knows the location of the MAC addresses on the network because it has learned them via their virtual switch and by broadcasting traffic that might update that learning to every interface on the VLAN.
Now consider what happens when we want to send traffic between an L2 VLAN and an L3 subnet. When the L2 instance wants to send to L3, it should work just fine: The location of the destination IP is well known ahead of time so we can send directly based on the mappings provided by the control-plane.
However, now consider what happens in the reverse direction: the L3 vNIC wants to send traffic to a vNIC on a VLAN. It has no idea where to send it! The destination MAC will be that of the default gateway, but recall that the default gateway is just an illusion backed by the local virtualization data-path. The central control-plane doesn’t know where to find the overlay destination IP, and the local data-path hasn’t participated in any learning because it isn’t part of the broadcast domain.
To solve this problem, we have the following options:
-
Inform the control plane whenever the data plane in an L2 VLAN learns. This option has a number of pitfalls. First, the L2 vNICs don’t learn the location of IPs, they learn the location of MACs. Second, even if we did keep an ARP cache for the VLAN, such a system doesn’t address the problem of a packet sent to a destination that has not yet been seen on the VLAN. If this is the first packet to the IP or MAC, nothing on the VLAN will have learned it. Third, even if we solve these issues, the delay between informing the control-plane and propagating that learning to all potential senders will likely create customer-visible race windows when IPs and MACs move between interfaces and this will impact cluster/service availability.
-
Directly inform all vNICs in the VCN when the data plane in an L2 VLAN learns. This option has many of the same pitfalls with the added issue that it scales terribly. A VCN can have hundreds or thousands of vNICs. Sending to all of them when a GARP is issued or a new IP or MAC is seen would involve a tremendous overhead.
-
Use a router. Instead of performing direct peer-to-peer communication when sending from an L3 VNIC to an L2 VNIC, we can replicate the process in a physical network and send through a router, which participates in the broadcast domain to learn MAC and VNIC associations and implements an ARP cache to learn IP andMAC mappings. The problem with this approach is scale and availability: if all the traffic into and out of the VLAN has to traverse the router, it can become a bottle neck.
Practically speaking, any of these options can work. We can sort out how to propagate learned state to the rest of the vNIC fleet in an efficient way, and we can create code to handle ARP and switch learning at the L3 source when sending to L2 vNICs. However, these solutions are highly complicated and specific to L2 and L3 networking.
One of the things we’ve learned is that it’s better, whenever possible, to solve one big problem in a re-usable way than to solve a lot of little specific ones. It provides cleaner service ownership, lower operational costs, and most importantly, better composability and agility to offer new features and capabilities for our customers. It’s why our Gen 2 Cloud started with off-box virtualization and bare metal support and why we decided to tackle L2 networking instead of building a one-off solution for VMware.
As we mature as a cloud, we see those investments pay dividends. We have scalable, highly available router technology that we built for our internet gateway, service gateway, and dynamic routing gateway fleets. We have a low-latency, consistent distributed data store that we built for distributing network state across a cluster for our NAT gateway. Finally, we have a vNIC implementation that runs on a server cluster instead of our off-box virtualization engine) which was engineered for our Private Endpoint and Network Load Balancer products.
If we combine these technical investments, we end up with a scalable router fleet that can share state at low latency with strong consistency and run our vNIC network stack. By gluing together our previous investments, we have a highly available, scalable router to connect our L2 VLANs to the rest of the L3 VCN. Instead of a virtual router simulated in our local virtualization device, we use a real gateway fleet for VLANs, and we call it the RVR – Real Virtual Router.
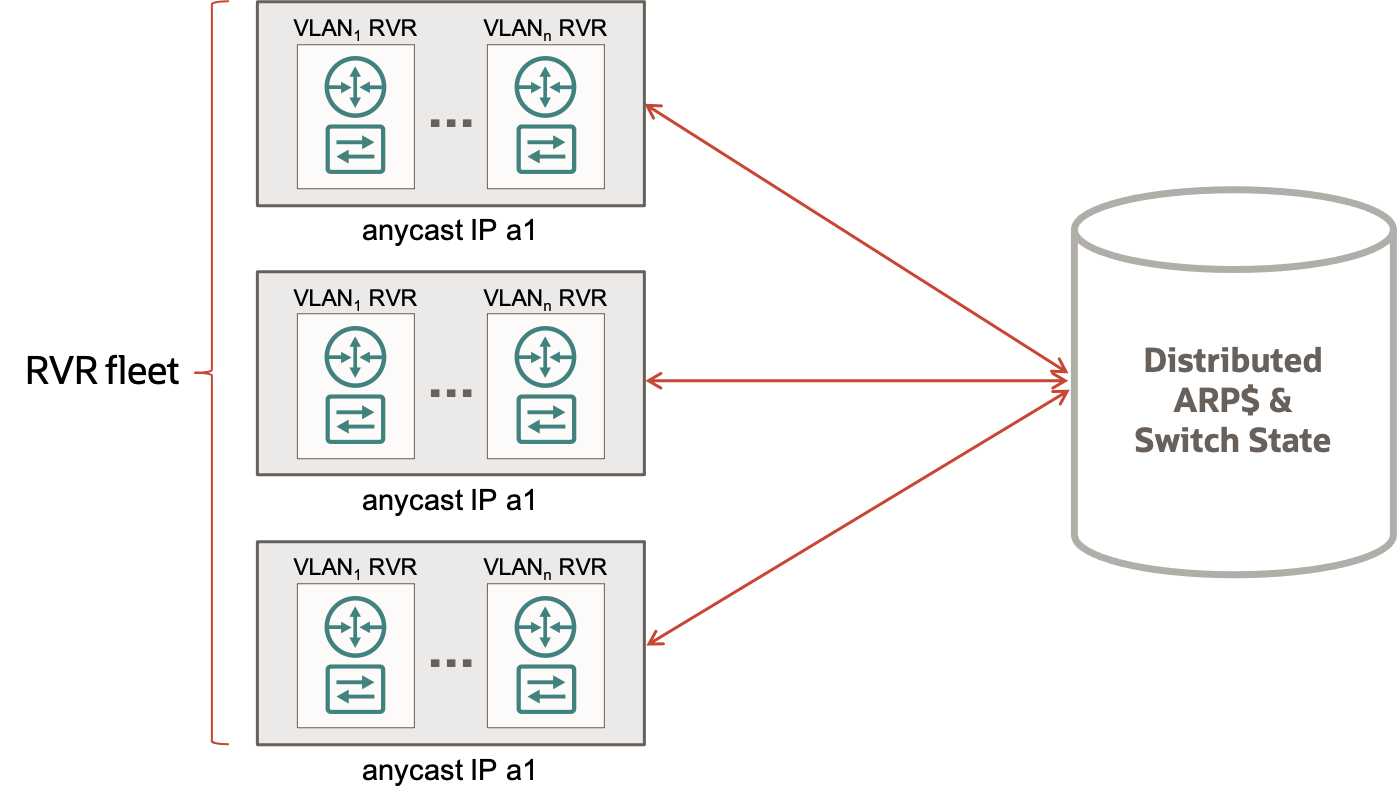
Figure 5. The RVR fleet connected to the Distributed ARPs and Switch State.
When a customer configures a VLAN for reachability from elsewhere in the VCN, they assign a CIDR block to the VLAN. The control plane doesn’t know where all the IPs in that CIDR are located (they can move around the interfaces in the VLAN or not be in use at all). But the control plane does know that they access them through the RVR. So, instead of mapping those IPs to their final interface like with L3 networks, the control plane maps those IPs to the RVR fleet. When an L3 vNIC needs to send to an IP that’s mapped to a VLAN, it performs the mapping lookup and sends to the RVR. The RVR uses substrate anycast addresses to scale across multiple hosts and it uses our distributed key-value store to share ARP cache and switch state across the fleet. So, packets can arrive on any RVR host without impacting functionality.
When packets arrive at the RVR from outside the VLAN, the ARP cache is consulted to look up the destination MAC and, in the event of a cache miss, the packet is buffered to wait for ARP resolution. Then, the packet is sent to the same virtual switch stack used by our off-box virtualization devices, which uses the MAC/Port map or flooding to send the packet to the correct interface. In the opposite direction, when packets leave the VLAN, the RVR updates switch and ARP tables based on the observed source of the traffic, and then performs routing based on the route-table the customer has configured for the VLAN’s “virtual” router.
Conclusion
OCI’s commitment to solving hard problems for customers in composable and reusable ways has positioned us to offer Layer 2 networking at cloud-scale. So, customers can migrate existing applications without substantial rearchitecting and Oracle Cloud VMware Solution can provide customers with unparalleled compatibility and control over their cloud VMware deployments.
Sources
1 – Based on Oracle analysis of AWS, Microsoft Azure, Google Cloud offerings as of January 2021.
2 – Based on Oracle analysis of AWS, Microsoft Azure, Google Cloud offerings as of January 2021.
3 – Based on Oracle analysis of AWS, Microsoft Azure, Google Cloud offerings as of January 2021.
Click to view more First Principles posts.