Hello, my name is Zachary Smith, and I’m a Solutions Architect working on Big Data for Oracle Cloud Infrastructure.
In June 2018, we announced the availability of Terraform automation to easily deploy Cloudera Enterprise Data Hub on Oracle Cloud Infrastructure.
Today we are proud to introduce the next version of the automation templates, which enables you to use data tiering with Cloudera Enterprise Data Hub deployments on Oracle Cloud Infrastructure. You can now leverage the multiple classes of storage available in Oracle Cloud Infrastructure—block volumes, local NVMe SSD, object, file, and archive—in a single Hadoop cluster. You can also define storage policies customized for your workloads, which can help lower costs without compromising on SLAs. The storage policies can now be defined through the command line automation tool.
You can continue to use the Cloudera Manager to set up new policies or update defined policies. You can find out more in Cloudera’s documentation.
Splitting up data within tiers reduces costs. Less frequently used data resides on block volumes or is copied to Object Storage, which are both less expensive and allow for higher storage density. This enables you to meet storage capacity requirements while minimizing compute costs to meet workload demands. We are already seeing large enterprise customers leverage this feature to drive cost and operational efficiencies by using the fast bare metal NVME storage for hot data while using the Block Volumes storage for cooler data.
In addition to using the updated automation scripts to configure Enterprise Data Hub to use various data tiers, you can use the mover tool periodically to move data between storage classes for greater efficiency in data storage and to ensure compliance with storage policies.
In our initial experiments, we found an average transfer rate of 4 GB/s between local NVME and block volumes in a six-worker-node cluster with 12 2-TB block volumes per worker.
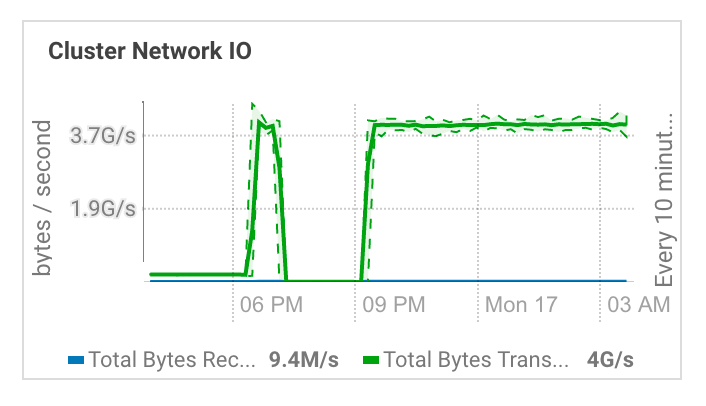
Additionally, the data movement between tiers scales with the number of nodes. Because the recommended guidance is to run the mover tool on a regular basis, we don’t expect the data movement overhead to be significant during regular operations of the cluster.
You can find the Terraform automation template on GitHub, included with the availability domain spanning architecture that we announced last month.
