Hello, my name is Zachary Smith, and I’m a Solutions Architect working on Big Data for Oracle Cloud Infrastructure.
You might have seen Larry Ellison’s keynote at Oracle OpenWorld 2018 regarding the significant price and performance advantages of running Big Data workloads on Oracle Cloud Infrastructure. I ran TeraSort benchmarks to understand the price and performance advantage, and I’d like to share an in-depth look at the benchmark process.
Creating the Environments
For the benchmark environments, I used Cloudera as the Hadoop distribution (v5.15.1).
Deployment on Oracle Cloud Infrastructure leveraged Terraform templates available on GitHub to automate cluster deployment and configuration. Oracle Cloud Infrastructure clusters were tested using four bare metal shapes: BM.StandardE2.64, BM.Standard1.36, BM.Standard2.52, and BM.HPC2.36, with 32 x 1-TB block volumes for HDFS capacity per worker, and 256-GB root volumes.
The AWS deployments were done using some of the same automation elements from the Terraform templates, but because of the differences in provider code, the provisioning and installation was done manually. I chose AWS M5.24xLarge and AWS M4.16xLarge shapes for comparative analysis, with 25 x 1-TB EBS GP2 volumes for HDFS capacity per worker, and 256-GB root volumes. I used 25 volumes instead of 32 (as done on Oracle Cloud Infrastructure) because the Cloudera Enterprise Reference Architecture for AWS Deployments document (page 20) says not to use more than 26 EBS volumes on a single instance, including root volumes.
All hosts had the same OS (CentOS 7.5) and similar Cloudera cluster tunings aside from variances in CPU and memory, which depend on the worker host resources.
For cluster sizing, I normalized the OCPU as close to 300 cores per cluster as possible. The following table shows relative cluster sizes, OCPU/vCPU, and RAM information:

Running the Tests
To run the TeraSort, I used a benchmarking script that submits jobs to the cluster with relative tuning to available cluster resources. It uses the following formulas to calculate the number of mappers/reducers, map/reduce memory, and Java JMX/JMS parameters:
- Mappers/reducers: (number of workers * cpu_vcores)
- Map/reduce memory: (number of workers * RAM per worker)/number of mappers
- Java JMS/JMX parameters: (map memory * 0.8)
When running the tests on AWS shapes, I encountered Java heap space errors because the memory values using these formulas was too low for the same cluster heap settings. I tuned for higher memory/JMX/JMS values by increasing the yarn.cpu.vcores, halving the number of mappers, and then adjusting the minimum allocation vcores to compensate. These values produced equivalent job submission parameters.
The following table shows the relative cluster tuning parameters in detail:

The following table shows the job submission parameters:
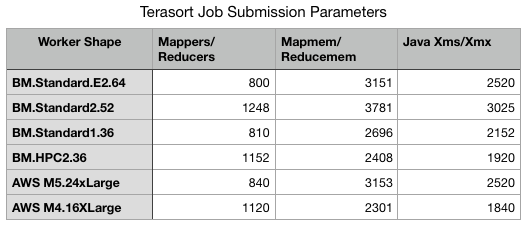
The following graphs show 1-TB and 10-TB TeraSort times:

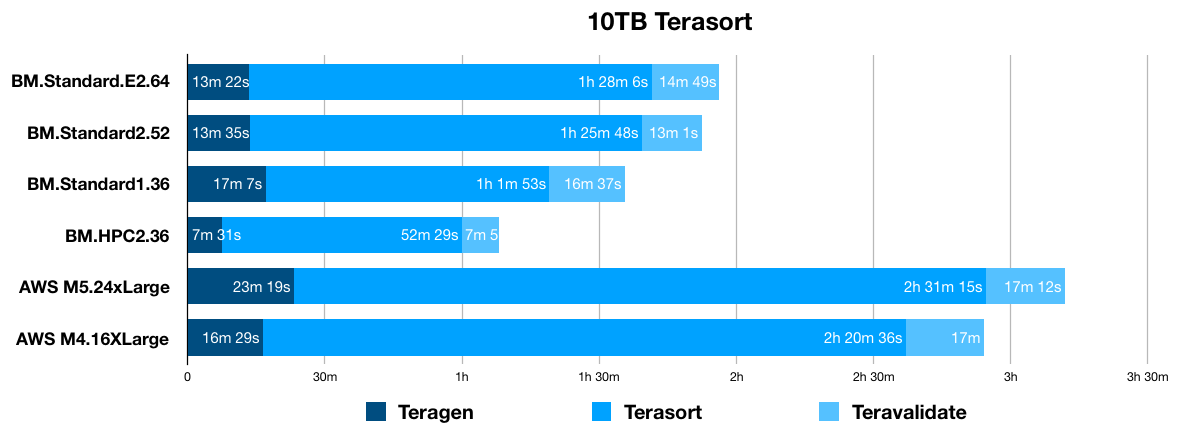
I also want to show some comparative utilization graphs in Cloudera Manager.
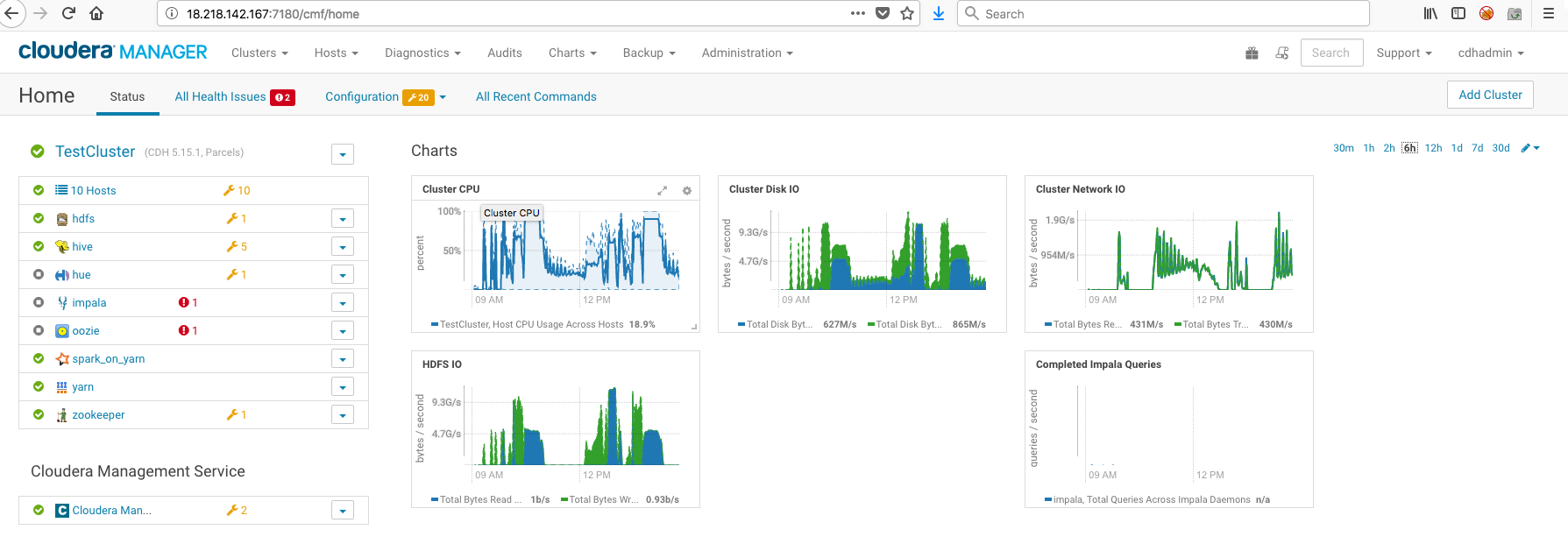
The following screenshot shows the AWS M4.16XLarge cluster:
The following screenshot shows the M5.24xLarge cluster:
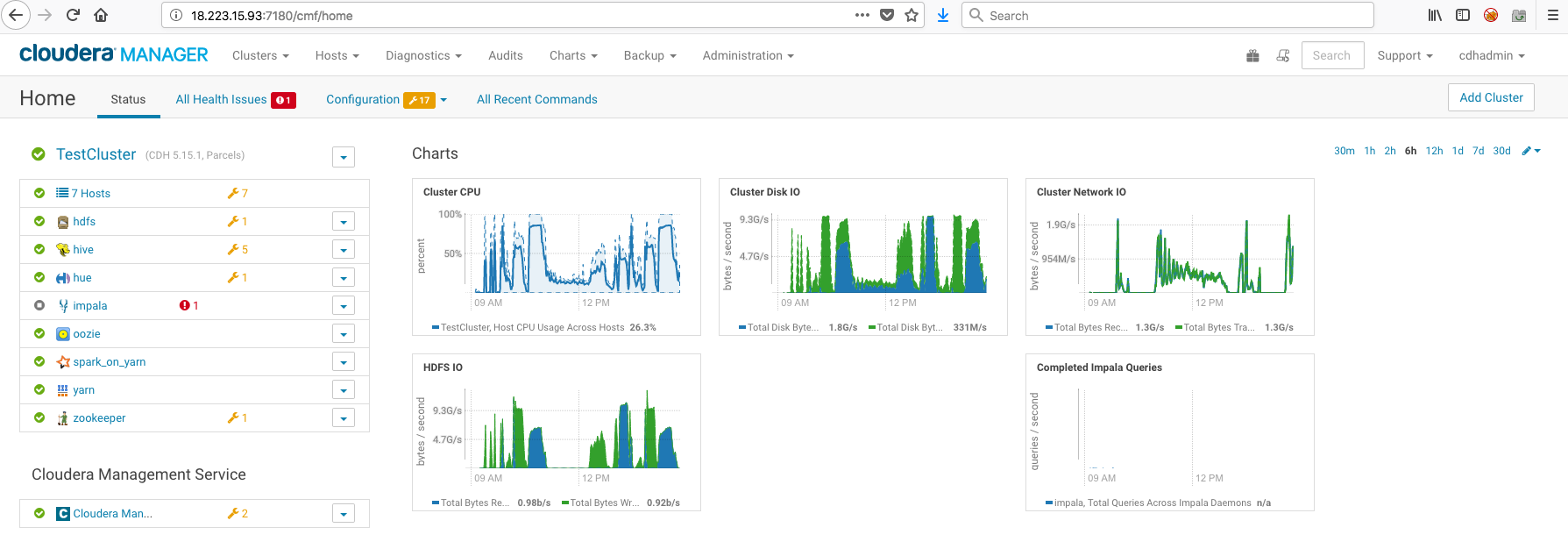
Note that the Cluster Network IO profiles are similar for both clusters, peaking at about 2G/s. Cluster Disk IO peaks a little over 9G/s, as does HDFS IO.
Now look at the comparative graphs on an Oracle Cloud Infrastructure cluster with BM.HPC2.36 worker shapes:
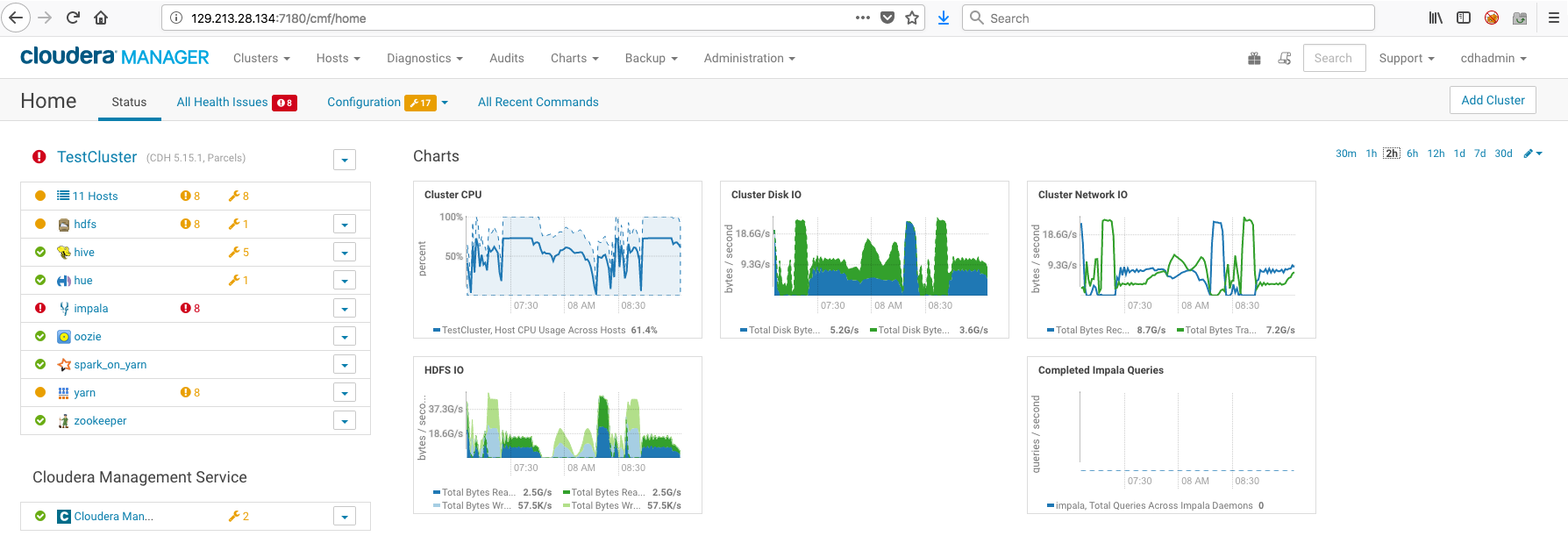
On Oracle Cloud Infrastructure, the Cluster Disk IO peaks at around 25G/s and Cluster Network IO mirrors it. That’s 10 times the bandwidth compared to AWS! HDFS IO also peaks at almost 5 times that of AWS. Also note the CPU utilization graphs; the impact of reduced I/O in AWS directly affects the processing ability of the cluster. In essence, the network performance is a bottleneck. With the Oracle Cloud Infrastructure shapes, you get near line-speed, which eliminates that performance bottleneck and allows maximum utilization of cluster resources. This leads to substantially faster workload processing times.
The bottom line: When you choose to run your Big Data workloads on Oracle Cloud Infrastructure, you are getting exponentially better performance, with guaranteed SLAs for performance, manageability, and availability, at a substantially cheaper price point as compared to AWS.
Next Steps
Sign up and try Oracle Cloud Infrastructure for free, download a Terraform deployment template, and experience the blazing fast performance of Big Data on Oracle Cloud Infrastructure yourself!
