Advancements in artificial intelligence (AI) are both frequent and game-changing, which makes the spot for the ‘best’ model in any given discipline highly competitive. However, often the best-performing algorithms are published in a way that anyone can implement, train, and utilize the algorithm for their specific use case.
Meet BERT
Bidirectional Encoder Representations from Transformers (BERT) is a deep learning model for language that has been making waves in the Natural Language Processing (NLP) space since the paper was published in May 2019. It made breakthroughs in three difficult tasks for NLP models, General Language Understanding Evaluation (GLUE), Multi-Genre Natural Language Inference (MultiNLI), and Stanford Question Answering Dataset (SQuAD). At a high level, the differentiator with BERT compared to other models is its bidirectional nature where the model determines the meaning of a word depending on the context both before and after the word appears in a sentence.
If you’re interested in testing the BERT algorithm, NVIDIA provides a fully functional example that you can run in Oracle Cloud Infrastructure (OCI), based in either PyTorch or Tensorflow. The DeepLearningExamples library provides an exhaustive look at different aspects of AI workloads, from source code, to training and inference, and expected benchmark performance metrics.
However, if you want to develop a practical application of BERT, it’s not necessary to start from scratch. The Transformers library from the group Hugging Face, which focuses on easing the barrier to NLP development, provides a streamlined API that covers the most common tasks, and includes access to pretrained models.
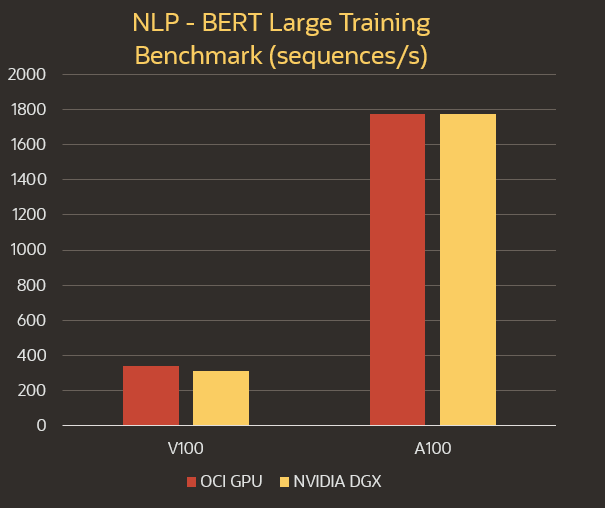
One of the attractive features of BERT for applications in research, education, and industry is its compatibility with the concept of pretraining. Natural Language Processing requires a large dataset to build a model with basic functionality. The model is first trained on either the Wikipedia Corpus or the Book Corpus and then trained against a smaller dataset, like the datasets provided by GLUE, MultiNLI, and SQuAD, for a specific task. Groups can either perform the pretraining themselves or download complete pre-trained models.
To provide some context, pretraining on OCI’s BM.GPU3.8, which features eight NVIDIA V100 GPUs, takes around 3.7 days or 14.8 hours on the new BM.GPU4.8, which features eight NVIDIA A100 GPUs. Training for a specific task takes hours for the V100 architecture, so the savings in both turnaround time and compute costs are reduced once you select a pretrained model. In a previous post, I detailed the performance improvements for BERT training between the BM.GPU3.8 and the BM.GPU4.8, along with a few other common deep learning use cases.

How Oracle Cloud can help
Oracle Cloud Infrastructure offers an array of GPU shapes that you can deploy in minutes to begin experimenting with NLP. If you’re interested in starting from scratch and training BERT with either Wikipedia or Book corpuses, I recommend deploying a BM.GPU3.8, or the BM.GPU4.8 once generally available. If you’re interested in developing with Transformers, you can find some of the V100 virtual machine (VM) shapes to suit your throughput needs.
Natural Language Processing is an exciting area of artificial intelligence development that fuels a wide range of new products for search engines, chatbots, recommendation engines, and pairs with speech-to-text. As human interfaces with computers continue to move away from buttons and forms and into context rendering models, the demand for growth in Natural Language Processing continues to increase. For this reason, Oracle Cloud Infrastructure is committed to providing on-premises performance in the cloud with our performance-optimized Compute shapes and to stay updated with the state-of-the-art systems.