
What is deepfake?
Deepfake, a compound word of “deep learning” and “fake”, is AI-generated media that either replaces a person in a picture or video with someone else, or modifies the person’s external features (such as age, hairstyle, or voice).
The act of manipulating videos and images has been around for a long time, but using machine learning and AI to produce media with a high potential for deception is new. It is almost impossible to distinguish real and fake media with the naked eye.
Let’s look at some deepfake examples and how to build a deepfake on Oracle Cloud Infrastructure (OCI).
Run machine learning and deep learning on Oracle Cloud
Deepfake examples: The good, the bad and the ugly
Fake videos of public figures, in which they say or do controversial things, have appeared on internet platforms. The forgeries could influence political elections, incite violence, and damage people’s reputations. There have not been many cases in politics so far. Deepfakes are more often misused for cybercrime and in generating sexual explicit material of famous people.
However, there have been also many positive benefits from deepfake. Let’s think of the case that an actor/actress has died and you still want to have him/her appear in films, as with Peter Cushing, who passed away in 1994 and appeared as a deepfake in Star Wars: Rogue One (2017).
Deepfakes can also help people process trauma or grief. Audio and visual material of deceased people can be used to create videos where they say or do things that will help their relatives to deal with their grief. In 2018, the Illinois Holocaust Museum and Education Center created holograms of Holocaust survivors that answer questions from visitors and tell stories.
We can inexpensively create content in films or other creative work and make it available to a broader mass, removing barriers such as language and death.
How do deepfakes work?
Deepfakes are based on artificial neural networks that recognize patterns (e.g. faces, voices) in data (photos or videos of people). You enter a large amount of data into neural networks, which are trained to recognize patterns and fake them. Neuronal networks are algorithms that are inspired by the human brain.
A neuron receives and transmits signals to and from other neurons through their synapses over axons and dendrites. When a signal moves from A to B, it may be passed on by layers of neurons. Similarly, a neural network algorithm receives input data, processes it through a layer of mathematical operations (matrix multiplications) equipped with different weights, which are adjusted during the training, and finally generates an output.
The neuronal networks that are used for deepfakes are called GANs (Generative Adversial Networks), where two machine learning models compete with each other. The first model is called the generator, which reads the real data and generates fake data. The second model, called the discriminator, is responsible for detecting the fake data. The generator generates fake data until the discriminator is not able to detect them anymore. The more training data is available for the generator, the easier it gets for it to generate a credible deepfake.
Deepfake detection
Detecting deepfakes has become tougher due to the rapid development of AI models and cloud technologies with powerful computers. There are detection techniques that forensic scientists use manually or that AI-driven applications use algorithmically. However, these techniques are only effective until the deepfake algorithm has access to the detection method and is trained with it.
More robust methods for deepfake detection are media authentication and through the evidence of their media origin. Using watermark authentication, media verification marks, signatures, and chain-of-custody logging, you can verify the integrity of a video or image and track it throughout the media lifecycle. You can provide the origin of the media either in the media itself or in metadata, such as lists of websites on which certain media have appeared in the past.
Faceswap
The best known and most widespread platform for generating deepfakes is Faceswap. It is an open source platform based on Tensorflow, Keras, and Python and it can be run on Windows, macOS and Linux (Ubuntu is recommended). An active community has formed that exchanges information and solutions on Github and other forums.
How to run Faceswap on Oracle Cloud Infrastructure (OCI)
You can run your Faceswap workloads using the 30-day free Oracle Cloud trial where all available VM and BMs instances can be tested. If you want to test the GPU offering, you can upgrade your Oracle Cloud account to the PAYG offering.
You can access your compute instance through a VNC client or a terminal.
The first step is to copy your training data to the compute instance. You need to provide pictures or a video of the two persons from whom you want to swap the faces. You can run the face extraction, the GAN training, and the video conversion using either the Faceswap GUI or running the Python scripts in the terminal.
For the individual steps to set up and run Faceswap on OCI, check out our Oracle Live Lab.
Our Faceswap use case
In our example, we will make use of videos (both a minute and twenty seconds long) from Michelle Obama and Beyoncé. From both videos, we extract 2400 images and train the GAN for 24 hours with several CPU and GPU shapes available on OCI that are listed in the table below.
We use “Original” model with a batch size of 16 images fed through the model at once. For more information on the different types of models and training options, visit the Faceswap Training Guide.
| Source |
| VM.Standard2.1 |
| VM.Standard2.4 |
| VM.Standard2.8 |
| VM.Standard2.16 |
| BM.Standard.2.52 |
| VM.GPU2.1 |
| BM.GPU2.2 |
The Faceswap AI model
The best way to know if the GAN has finished training is to watch the preview tab in the Faceswap GUI, which is updated after each iteration and displays how the actual swap will look like.
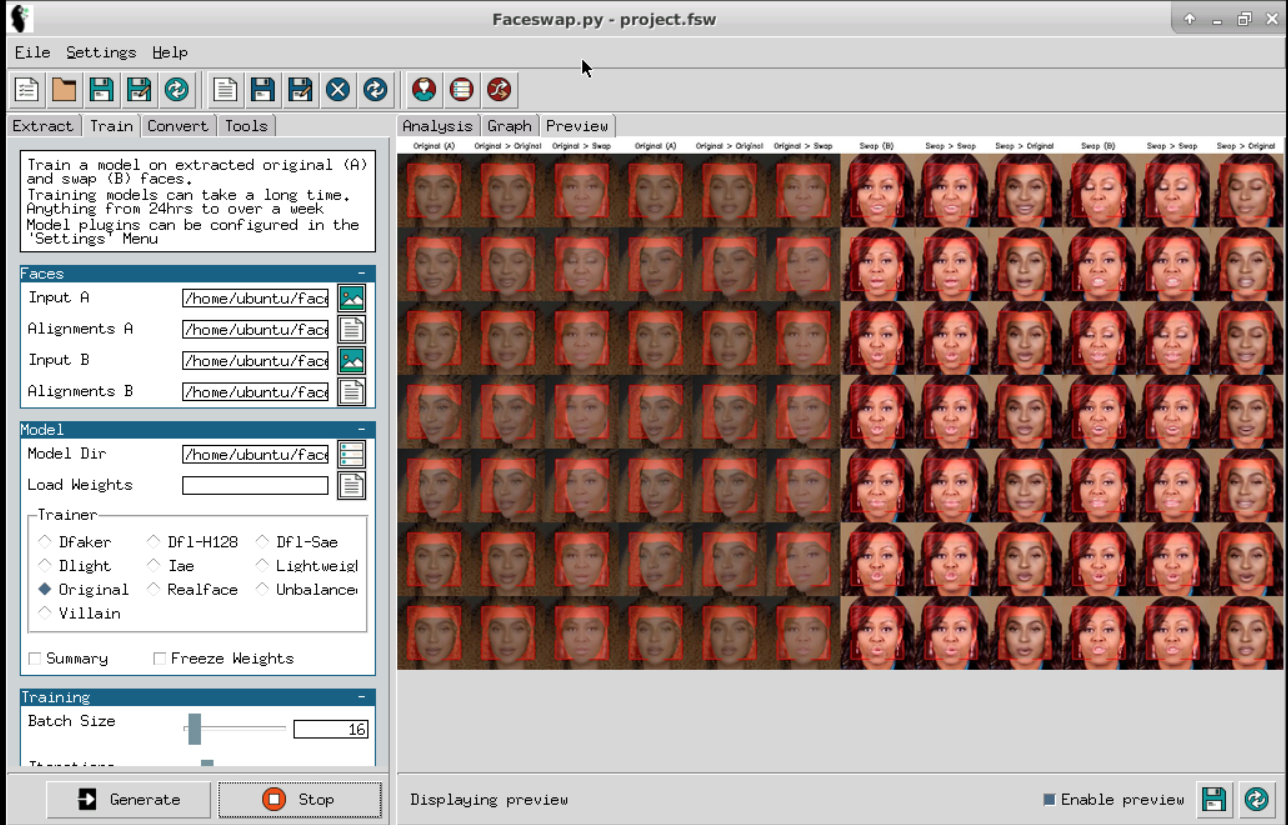
In the Analysis tab of the Faceswap GUI, you can check the value EG/sec, which will give you the number of faces processed through the GAN per second. The higher the EG/sec values are, the faster the GAN will converge.
Another way to check the conversion of the GAN is to check the loss values. For every batch of faces fed into the model, the GAN will look at the face it has tried to recreate and compare it to the actual face that you fed in. Based on how well it thinks it has done, it will give itself a score (the loss value). The closer the loss values are to zero, the higher the probability of a finished training.
GPU vs CPU for deep learning
Let’s have a look at some of the hardware differences between GPUs and CPUs:
| GPU | CPU |
| High compute density | Low compute density |
| Simple control logic | Complex control logic |
| Many ALUs (for parallel execution) | Fewer ALUs (for parallel execution) |
| Optimized for parallel operations | Optimized for serial operations |
| High memory bandwidth | Lower memory bandwidth |
Deep learning algorithms consist of massive matrix multiplications and additions. It is faster to solve multiple operations in parallel with a high compute density, instead of one operation after the other. In addition, deep learning algorithms are memory-intensive because they need to store the weights for each operation. With every iteration, the memory footprint increases requiring a high memory bandwidth for the algorithm to read and write data to the memory.
In order to execute matrix multiplications with 10 billion of parameters in a timely manner, you need adequate computing power. It is faster to run all operations at the same time instead one after another. A CPU executes one process after another with a small number of threads, whereas a GPU facilitates parallel computing with a large number of threads at the same time. The ability to process multiple computations at the same time makes GPU a better choice to train neural network algorithms.
CPU vs. GPU results
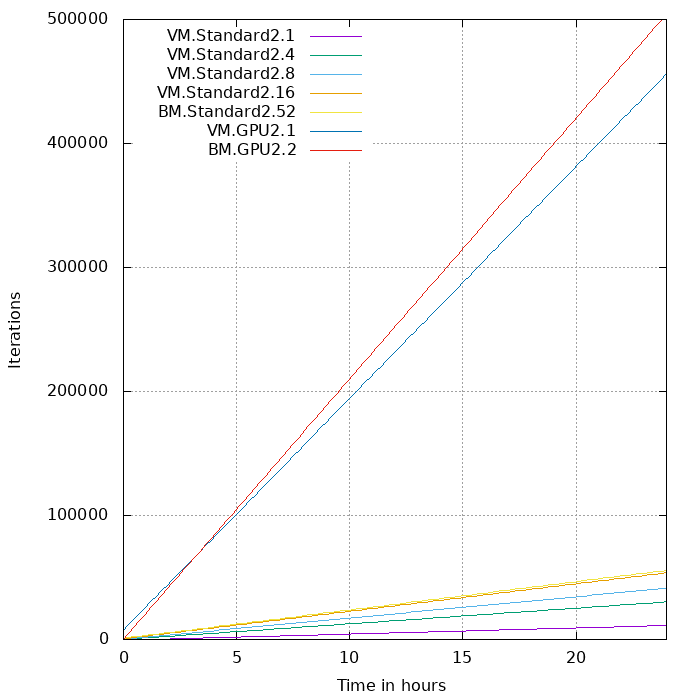
The figure below shows how many iterations of the GAN are processed within 24 hours for the CPU and GPU shapes on OCI listed above. The more cores are present in the CPU, the more iterations are processed over time. Still, there is a huge improvement in time when using GPU shapes, as they can process hundreds of thousands iterations more in the same amount of time by utilizing multiple compute threads in parallel simultaneously.
In the table below, you see number of faces processed through the GAN per second (=EG/s) for several CPU and GPU shapes. The more cores are present in the CPU, the more faces are processed per second. The EG/s value is ten to twenty times higher for the GPU shapes.
| Shape | EG/s |
| VM.Standard2.1 | 3.6 |
| VM.Standard2.4 | 11.2 |
| VM.Standard2.8 | 15.2 |
| VM.Standard2.16 | 20.2 |
| BM.Standard2.52 | 23 |
| VM.GPU2.1 | 179.3 |
| BM.GPU2.2 | 184.6 |
In the figure below, we compare the average loss values for face A between the VM.Standard2.16 and the GPU shapes. The average loss values are very close for the VM.Standard2.16 and BM.GPU2.1 shape, despite having different hardware characteristics. The BM GPU shape has a higher compute density (24 cores) that is utilized in parallel with a simple control logic, whereas the CPU shape (VM.Standard2.16) has a lower compute density (16 cores) that is able to execute complex operations sequentially. The GPU VM shape needs more iterations to minimize the average loss value, because it has a lower compute density (12 cores) than both the CPU and GPU BM shape in addition to the simple control logic. However, still the GPU VM is a better choice than the CPU shape, because it can process hundreds of thousand iterations more in the same amount of time (see previous figure).

View the deepfake video
The best choice for running deep learning algorithms like deepfakes are GPU instances, because they can process more iterations in a shorter amount of time and finish the GAN training earlier than CPUs.
You can also see the deepfake output video where the faces of Michelle Obama and Beyoncé are swapped.
Related content:
CPU vs GPU in Machine Learning
Data Science Technologies We Love
