Accessibility Policy
Skip to content
Oracle
Oracle Database Insider
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Oracle AI
Oracle Cloud Infrastructure (OCI)
Technical Solutions
Blogs Home
RSS
Oracle Database Insider
All things database: the latest news, best practices, code examples, cloud, and more
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
Take Action Today: Protect Your Oracle Database Against AI-Enabled ...
Jenny Tsai-Smith
1 minute read
Raising the Standard for Mission-Critical Availability and Security ...
Ashish Ray
11 minute read
Oracle AI Database Delivers Mission-Critical Agentic AI Built for ...
Hasan Rizvi
8 minute read
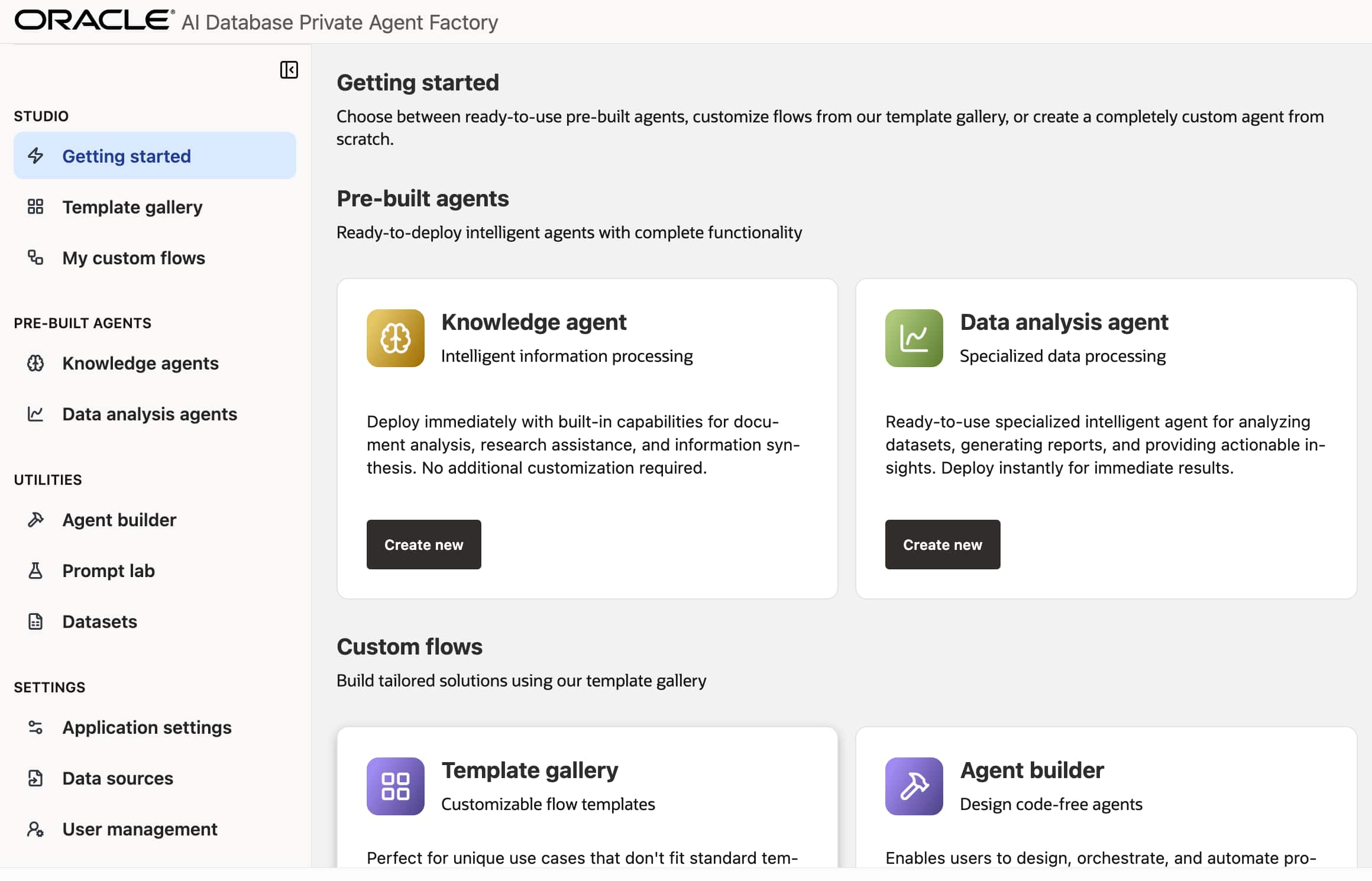
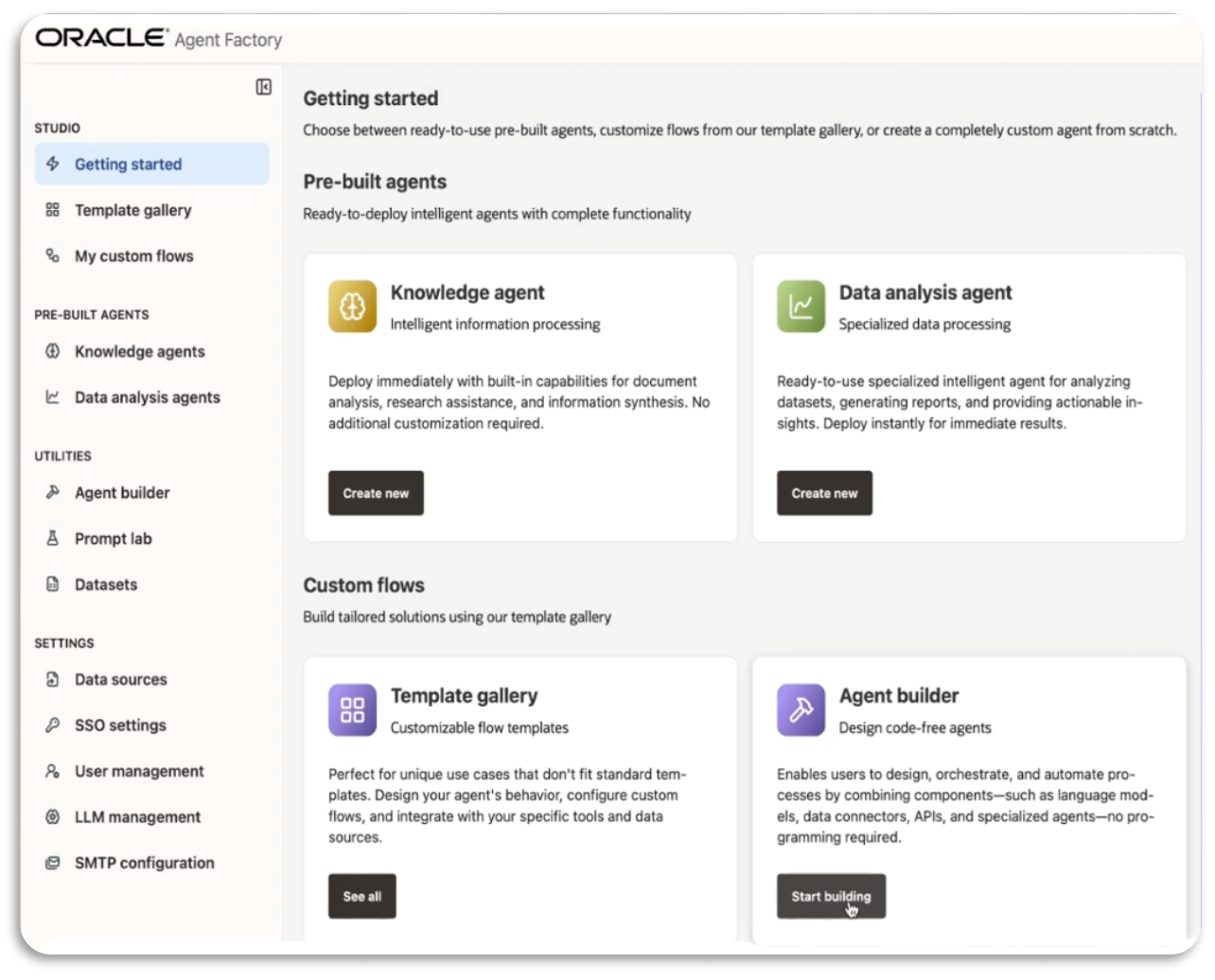
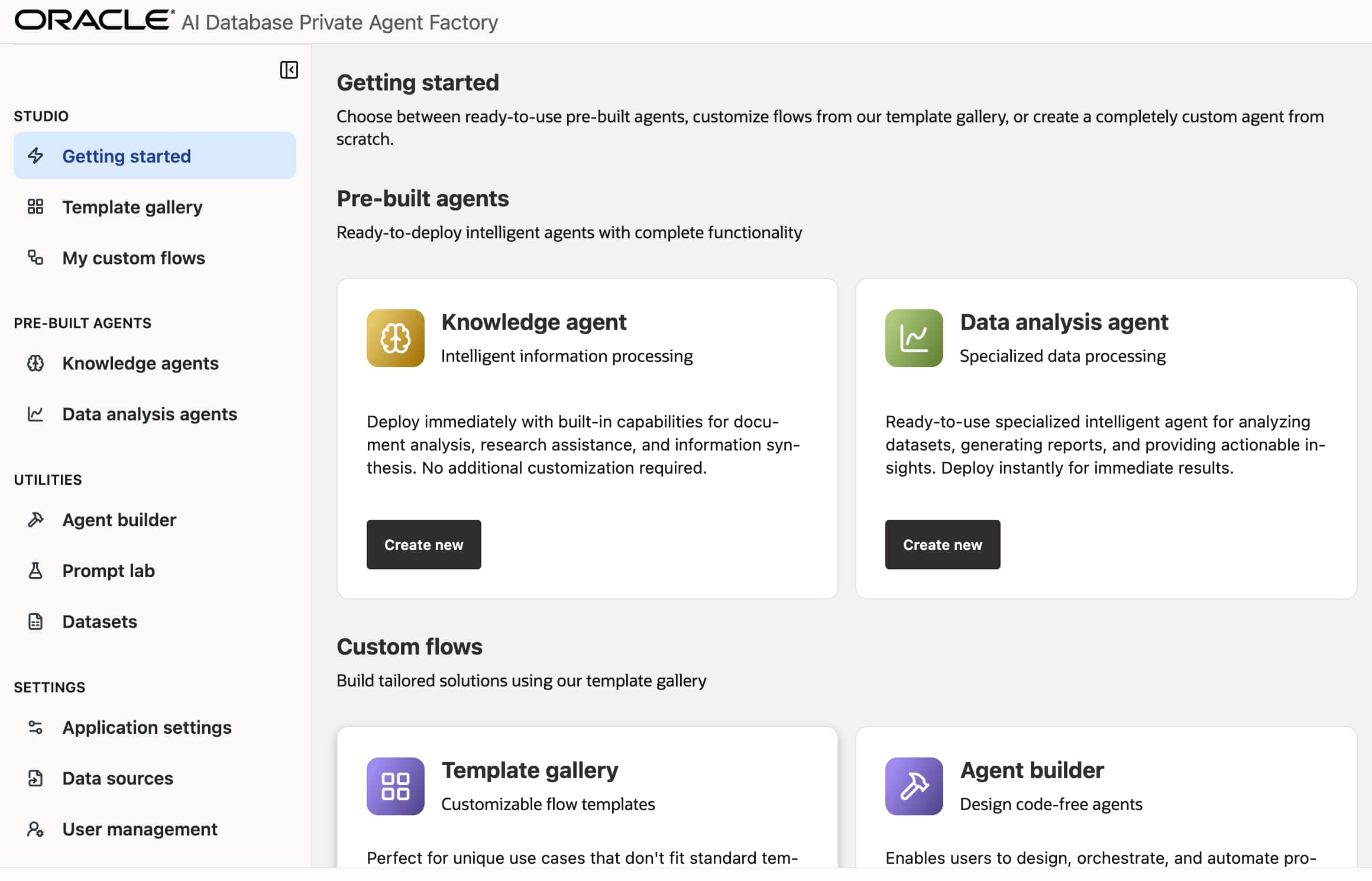
Introducing Private Agent Factory: Unlocking the Agentic AI Potential ...
Sanjay Goil
5 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to our blog
Artificial Intelligence
See all
Getting Started with the Vector Index Service – Part 2
Doug Hood
12 minute read
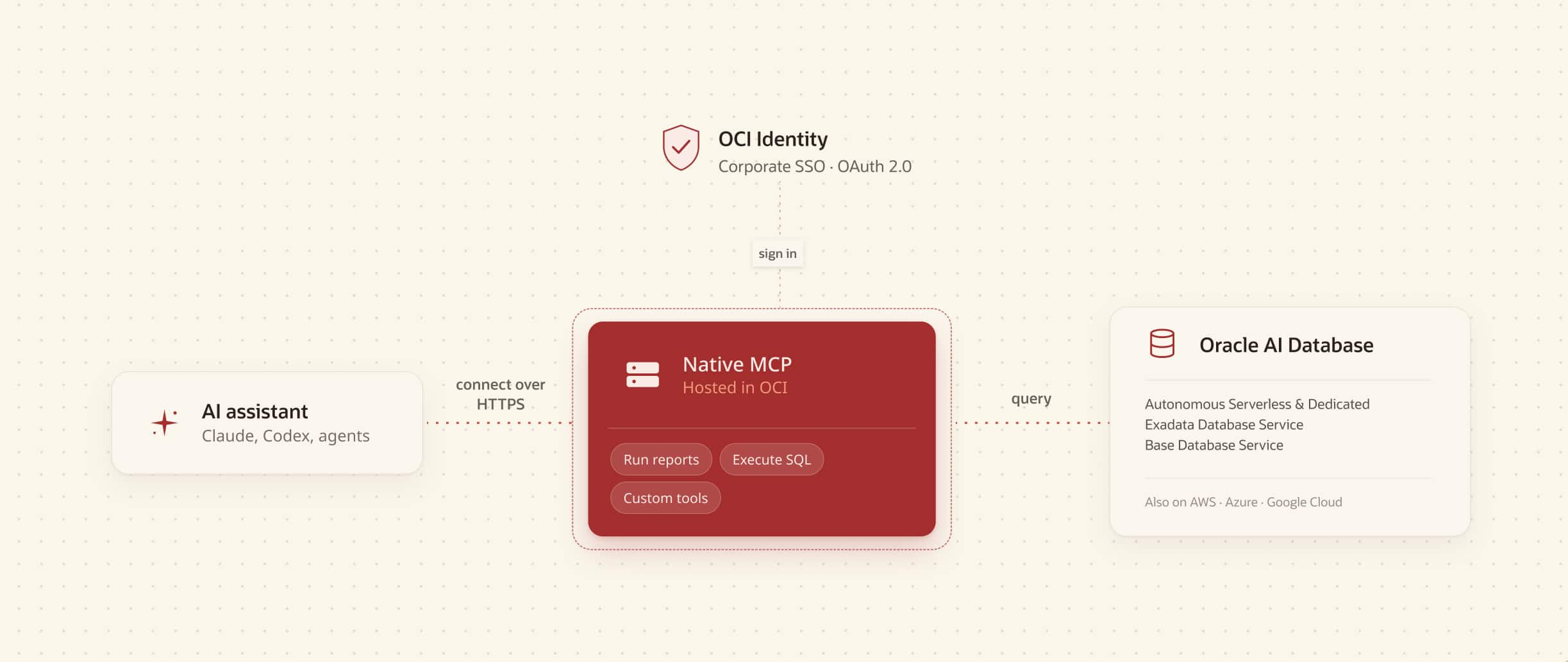
Gain Agentic Access to Any Oracle Database in the Cloud with Native, ...
Jeff Smith
Kris Rice
8 minute read
Getting Started with the Vector Index Service – Part 1
Doug Hood
15 minute read
Oracle AI Database Private Agent Factory: Enterprise FAQ
Kumar G Varun
10 minute read
Turning Invoice Compliance into a Scalable, Auditable Workflow with ...
Kumar G Varun
6 minute read
Pain Free Vector similarity search for your apps: Oracle Database ...
Chris Hoina
9 minute read
Oracle Introduces Trusted Answer Search to Deliver Fast, Accurate and ...
Sanjay Goil
Allen Hosler
6 minute read
Scaling Agentic AI: Why Transactional Messaging and a Converged ...
Nithin Thekkupadam Narayanan
4 minute read
Product News
See all
Getting Started with the Vector Index Service – Part 1
Doug Hood
15 minute read
Oracle Deep Data Security Is Now Available in Oracle AI Database 26ai
Vipin Samar
5 minute read
Oracle Customer Success Services: Patching and Upgrade Center for ...
Jenny Tsai-Smith
2 minute read
Take Action Today: Protect Your Oracle Database Against AI-Enabled ...
Jenny Tsai-Smith
1 minute read
Analyst Perspectives on Oracle AI Database Mission-Critical ...
Ron Craig
7 minute read
Raising the Standard for Mission-Critical Availability and Security ...
Ashish Ray
11 minute read
Introducing Oracle Database Security Central: Taking Control of ...
Vipin Samar
4 minute read
Announcing Oracle AI Database Operator for Kubernetes v2.1.0
Shefali Bhargava
Param Saini
Sanjay Singh
4 minute read
Vector Search
See all
Getting Started with the Vector Index Service – Part 2
Doug Hood
12 minute read
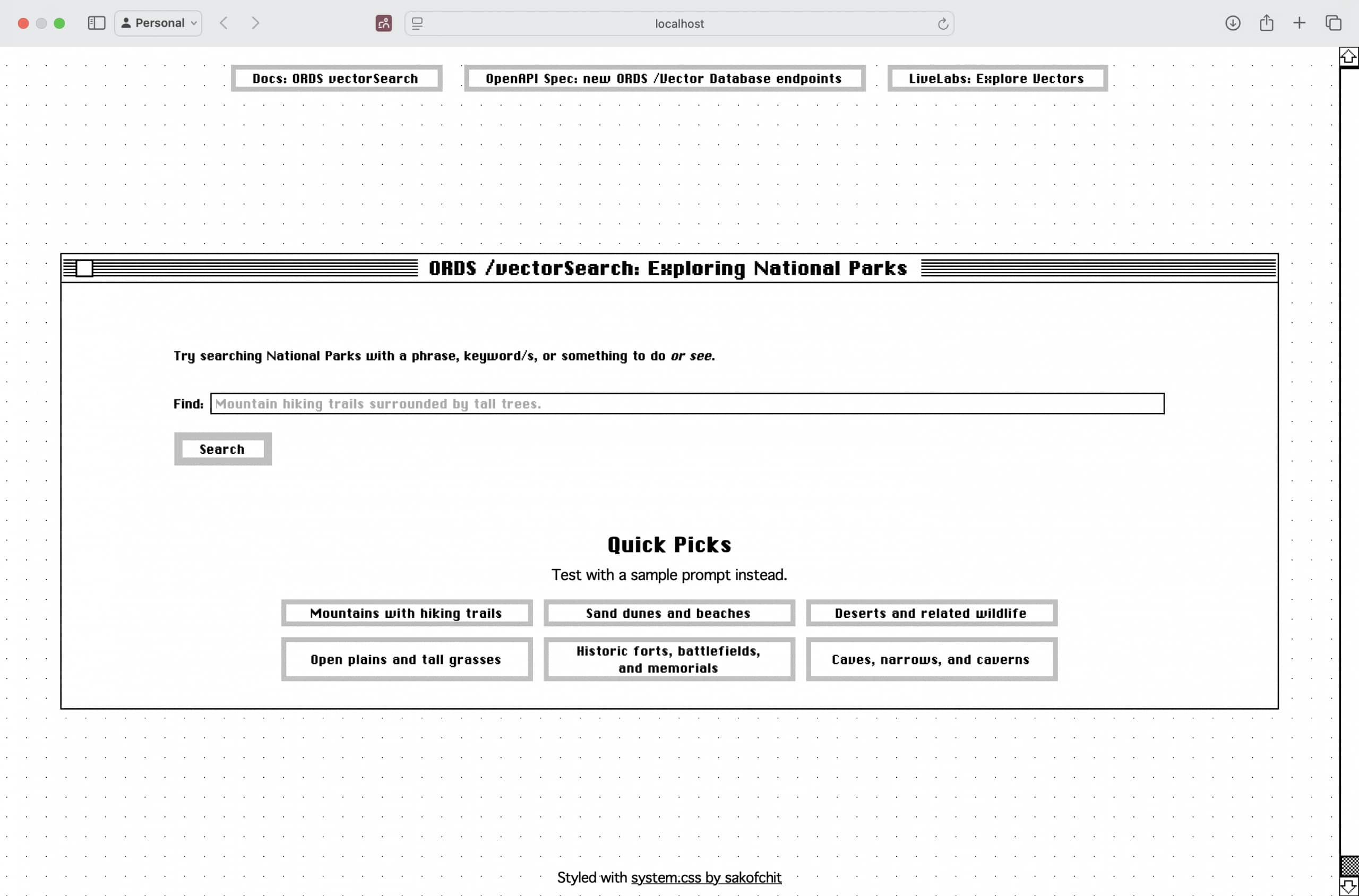
Getting Started with AI Vector Search LiveLabs Workshop Updates
Andy Rivenes
2 minute read
Getting Started with the Vector Index Service – Part 1
Doug Hood
15 minute read
Introducing the Vector Index Service
Doug Hood
3 minute read
Pain Free Vector similarity search for your apps: Oracle Database ...
Chris Hoina
9 minute read
Enterprise AI Search Needs a New Approach
Allen Hosler
4 minute read
Getting Started with Private AI Services Container
Doug Hood
16 minute read
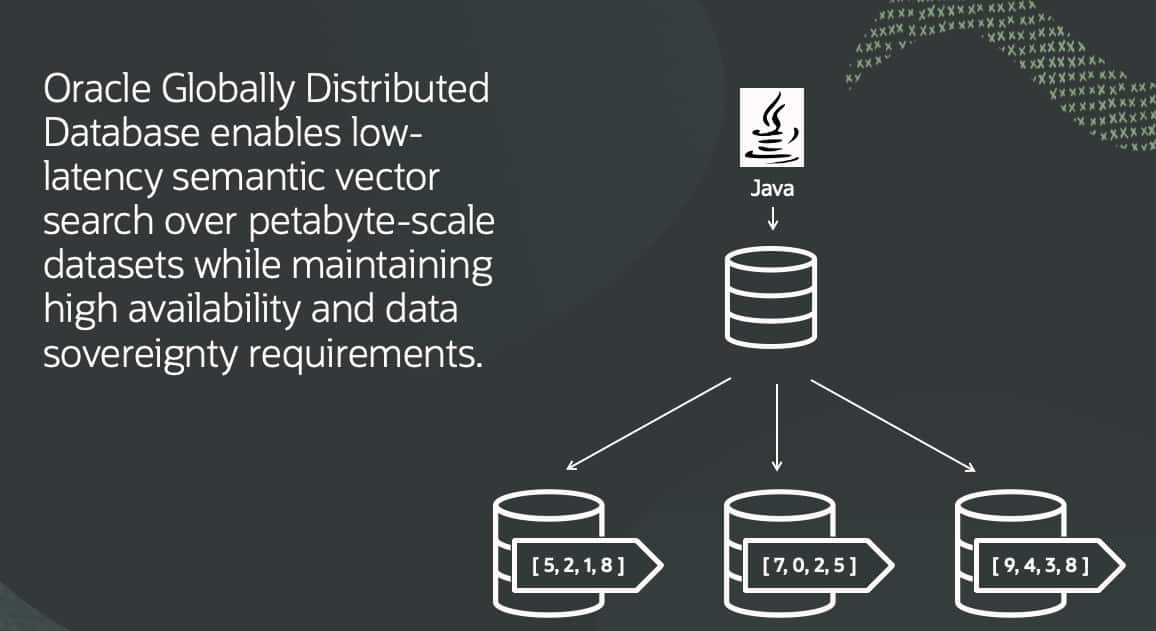
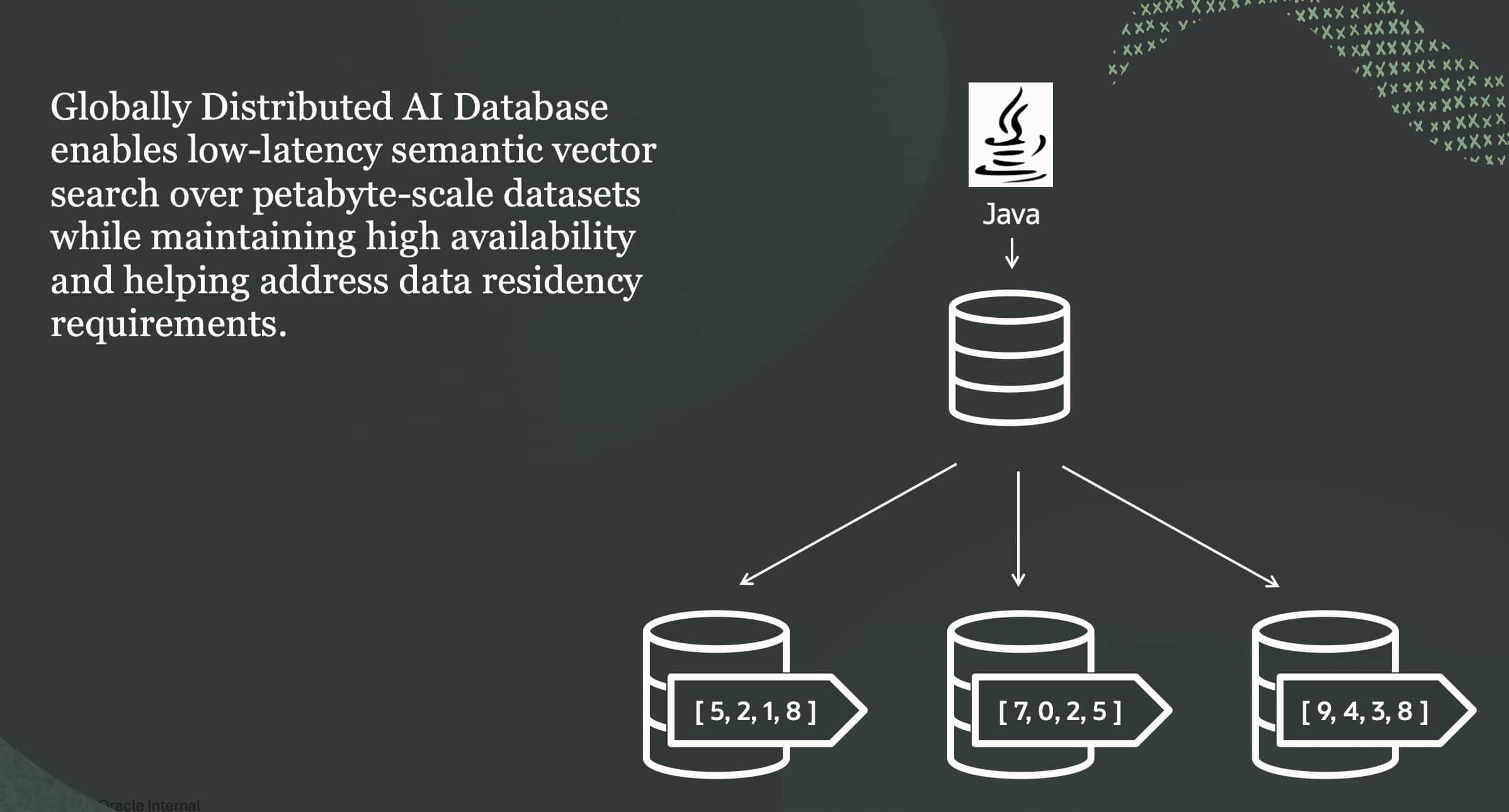
Building Scalable Vector Search with Oracle Globally Distributed ...
Kuldeep Bora
Kehinde Otubamowo
Deeksha Sehgal
7 minute read
Autonomous Database
See all
Cross-Platform Analytics: Oracle Autonomous AI Database Reads ...
Sathishkumar Rangaraj
9 minute read
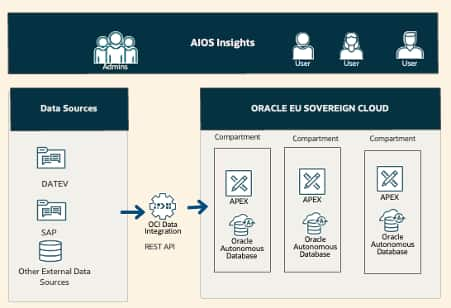
AIOS develops customized reporting and planning solutions with Oracle ...
Martina Keippel
3 minute read
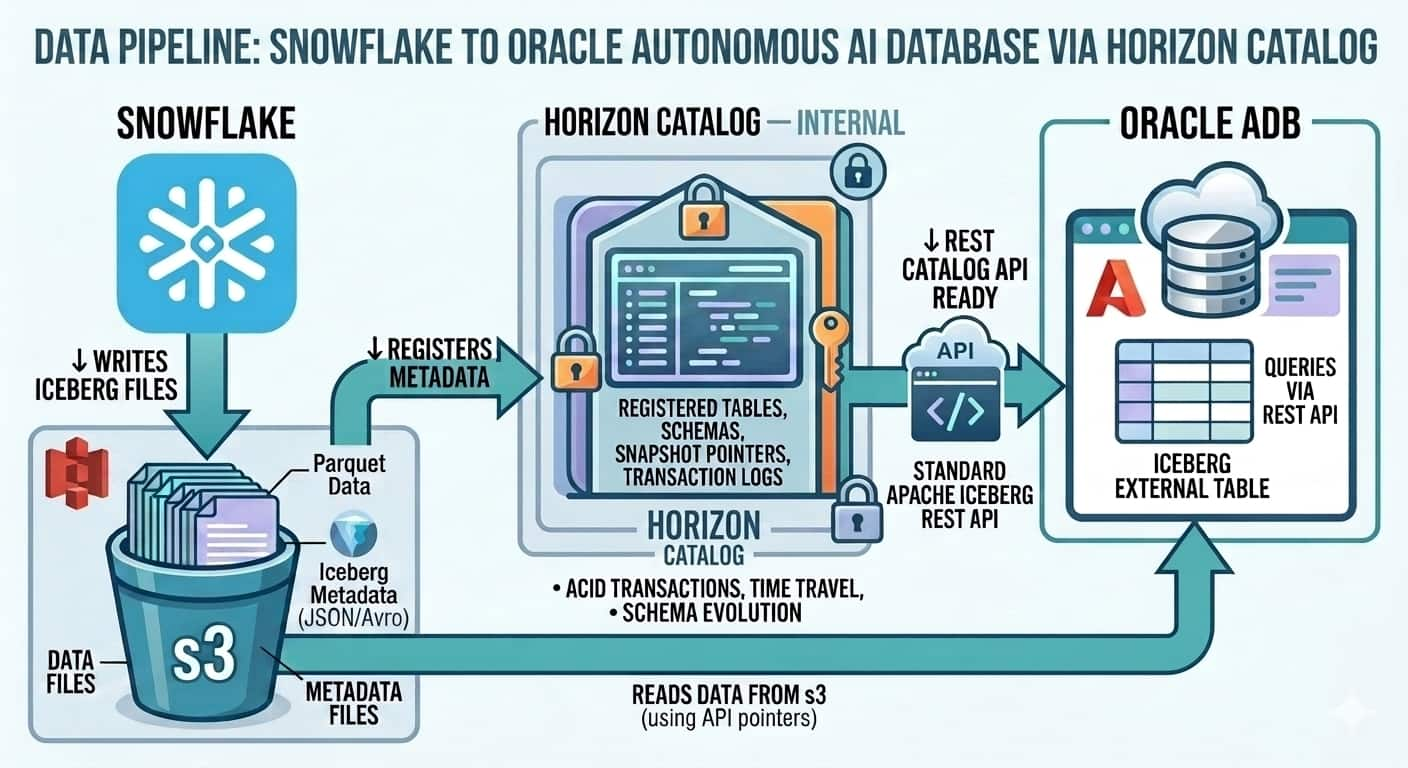
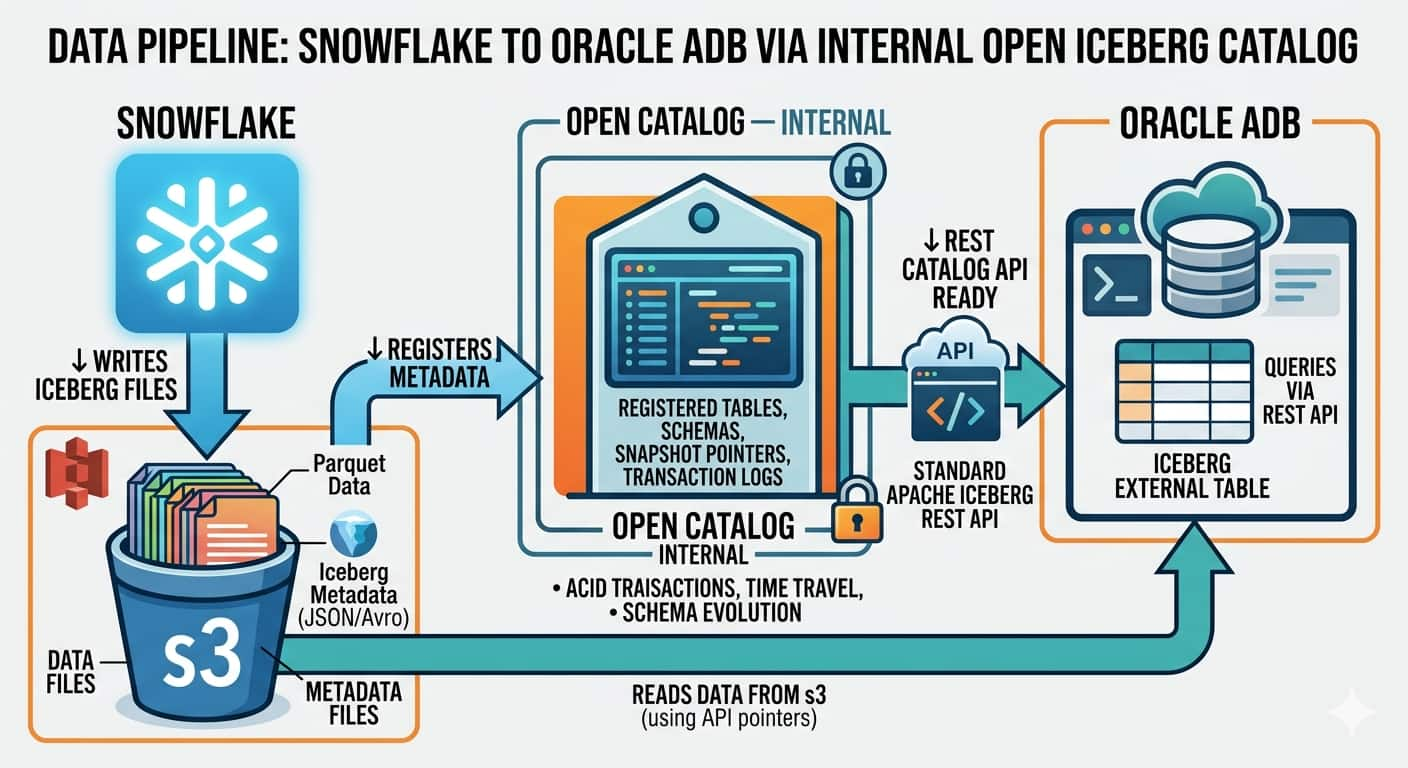
Bridging Oracle Autonomous AI Database and Snowflake: Reading Iceberg ...
Sathishkumar Rangaraj
8 minute read
Turning Invoice Compliance into a Scalable, Auditable Workflow with ...
Kumar G Varun
6 minute read
One Zero Bank Builds a Trusted Analytics Foundation for Digital ...
Sergiu Popovici
Reiner Zimmermann
3 minute read
Streamlining Your Path to Autonomous AI Database: Migration ...
German Viscuso
2 minute read
Announcing Oracle Autonomous AI Vector Database Limited Availability
Brian Macdonald
3 minute read
Cross-Region High Availability for MongoDB API on OCI: Testing with ...
Burak Akkus
Corina Todea
8 minute read
AppDev
See all
Build AI Agents on Enterprise-Grade Data–With Zero License Cost
Leo Alvarado
Tammy Bednar
5 minute read
Introducing Oracle Backend for Firebase: Build Mobile and Web Apps on ...
Killian Lynch
Dominic Giles
6 minute read
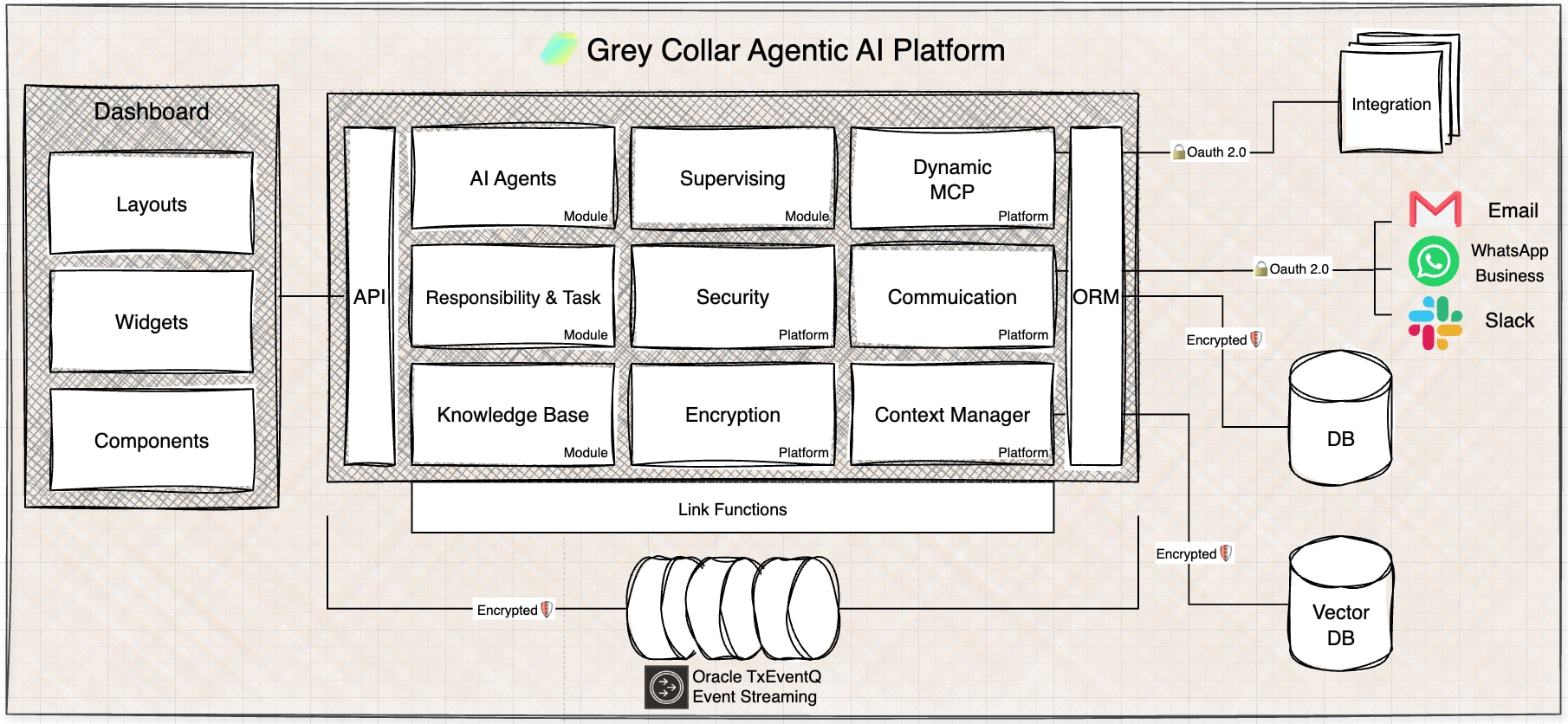
GreyCollar.ai moved agent messaging into Oracle Transactional Event ...
Anders Swanson
Nithin Thekkupadam Narayanan
5 minute read
Gain Agentic Access to Any Oracle Database in the Cloud with Native, ...
Jeff Smith
Kris Rice
8 minute read
Pain Free Vector similarity search for your apps: Oracle Database ...
Chris Hoina
9 minute read
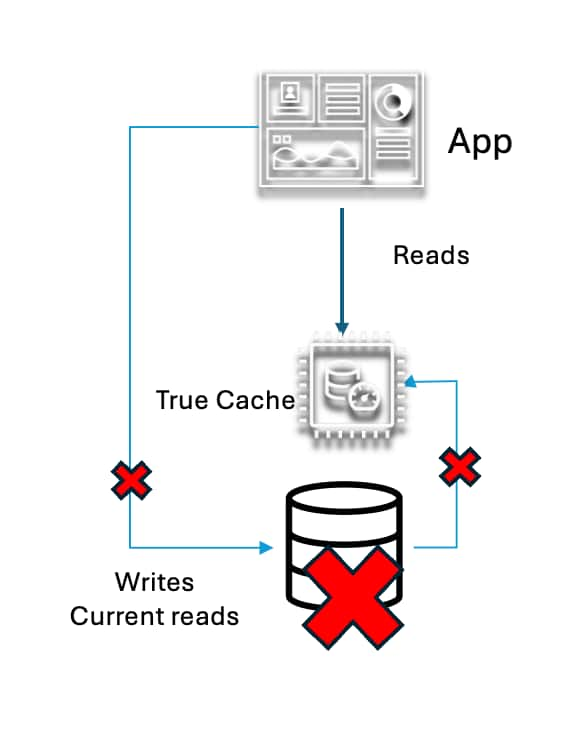
Maintain Application Read Availability as a bonus from Oracle True ...
Ilam Siva
5 minute read
Secure Agents, Built for the Enterprise
Allen Hosler
4 minute read
Eliminating Kafka Brokers with Oracle Transactional Event Queues for ...
Nithin Thekkupadam Narayanan
3 minute read
Analytics and Data Warehousing
See all
Cross-Platform Analytics: Oracle Autonomous AI Database Reads ...
Sathishkumar Rangaraj
9 minute read
Bridging Oracle Autonomous AI Database and Snowflake: Reading Iceberg ...
Sathishkumar Rangaraj
8 minute read
One Zero Bank Builds a Trusted Analytics Foundation for Digital ...
Sergiu Popovici
Reiner Zimmermann
3 minute read
Oracle Autonomous AI Lakehouse
Guest Author
5 minute read
Create Graph Databases with Graph Studio
Denise Myrick
3 minute read
Graph Database Use Cases for Financial Services Companies
Denise Myrick
4 minute read
Microsoft Azure and Oracle Database on OCI: A Big Win for Users
Guest Author
4 minute read
Why should you use graph analytics?
Neelima Tadikonda
5 minute read
Customer Stories
See all
AIOS develops customized reporting and planning solutions with Oracle ...
Martina Keippel
3 minute read
VakifBank migrates to Exadata next-gen infrastructure
Dana Serb
Kellsey Ruppel
3 minute read
Accelerating My Journey Building Enterprise AI Agents
Sanjay Goil
3 minute read
DZ Bank Accelerates Modernization and Data Protection with Oracle ...
Dana Serb
3 minute read
How Tawuniya tamed data management costs with Oracle ILM and Advanced ...
Maria Colgan
Peter Schutt
3 minute read
DeweyVision Transforms Media Discovery with Oracle AI Vector Search: ...
Malu Castellanos
6 minute read
Cummins in India uses Oracle Database Security to help meet ...
Viral Patel
Jeevan Pandit
Angeline Dhanarani
6 minute read
Umm Al-Qura University Meets Data Privacy and Data Protection ...
Mohannad Aljammal
Pedro Lopes
2 minute read
Database Cloud Services
See all
Build AI Agents on Enterprise-Grade Data–With Zero License Cost
Leo Alvarado
Tammy Bednar
5 minute read
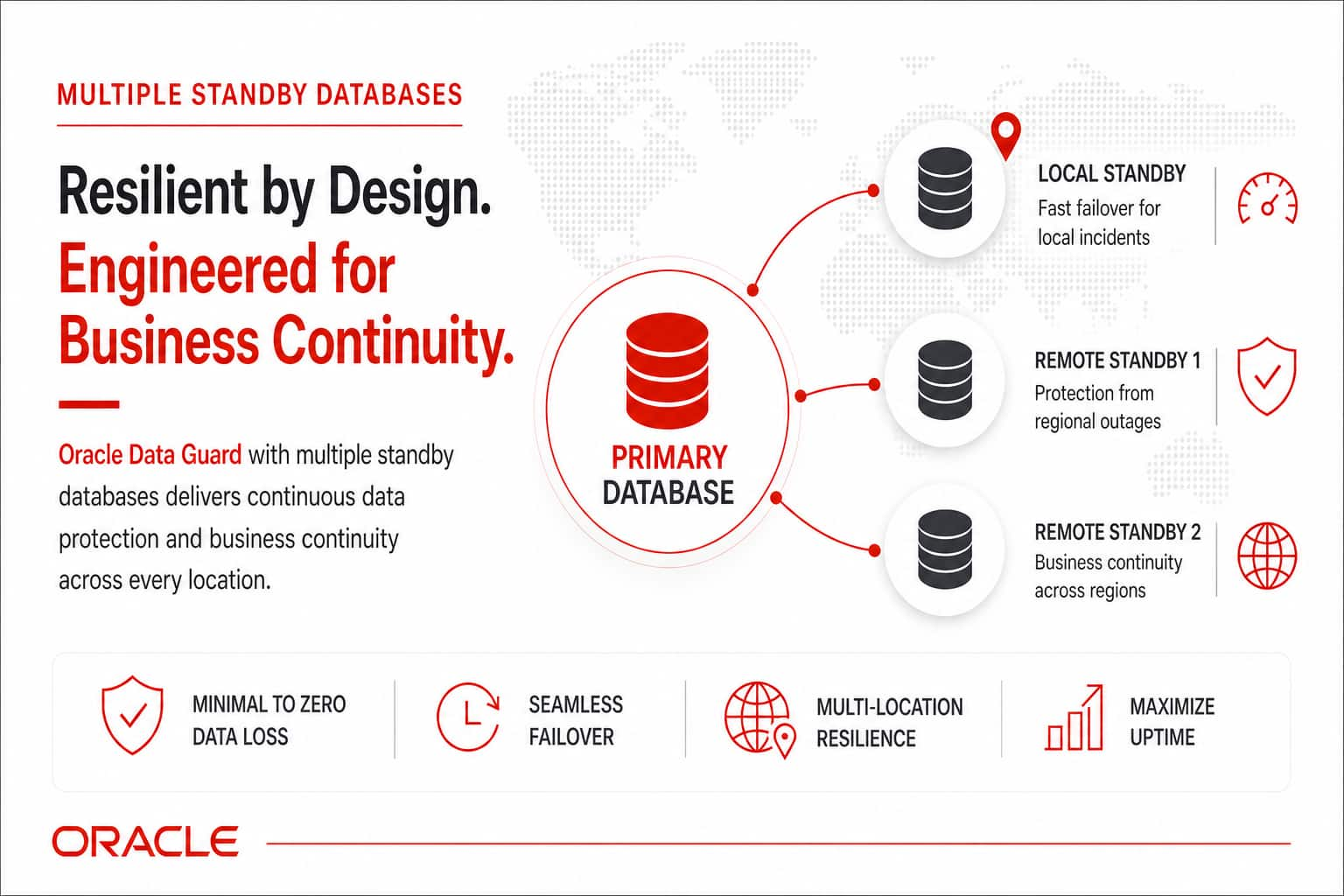
Modernize Your Disaster Recovery Strategy: Multiple Standby databases ...
Dileep Thiagarajan
Leo Alvarado
5 minute read
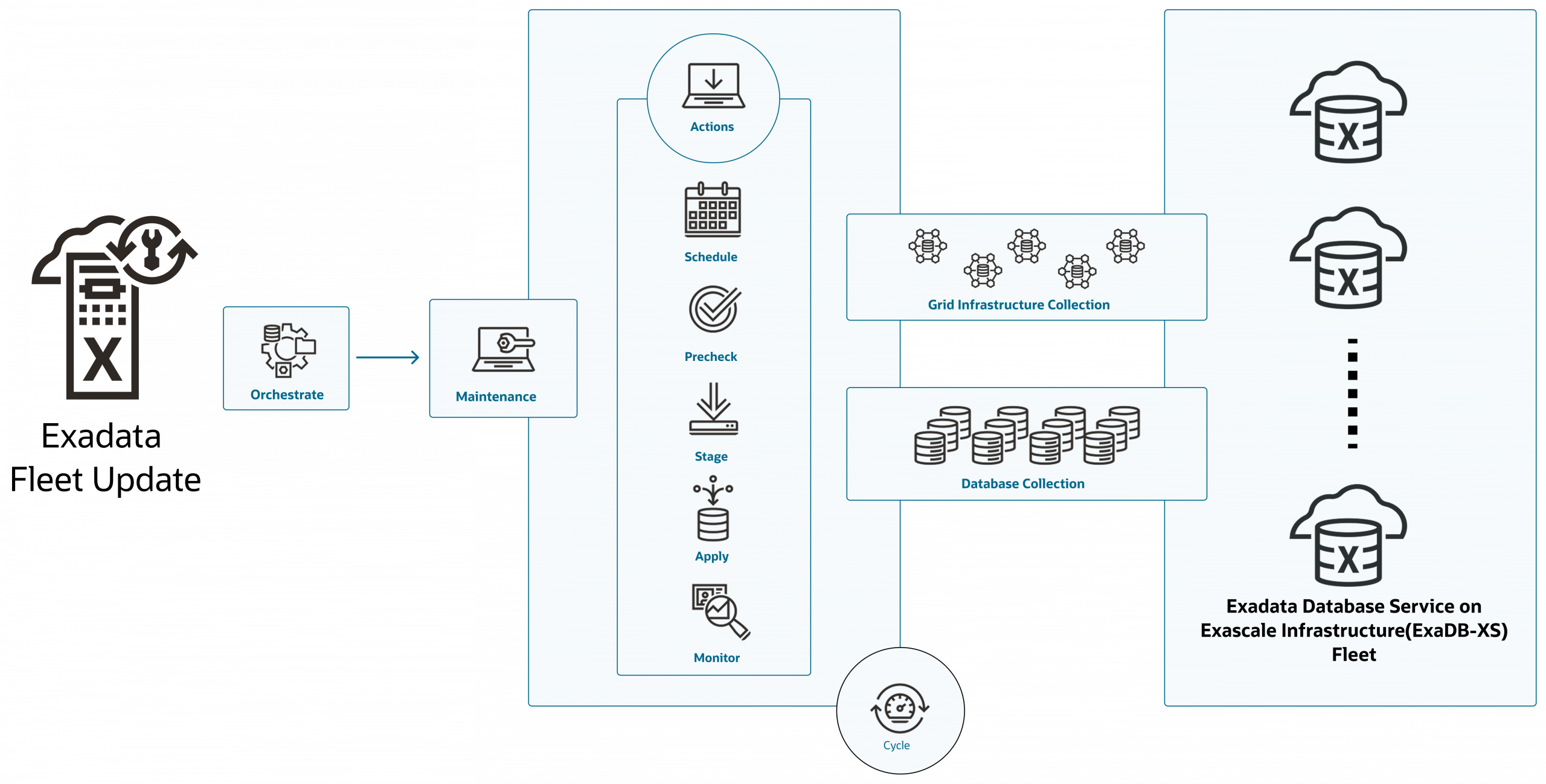
Announcing Exadata Fleet Update support for Exadata Database Service ...
Vishal Patil
Prince Mathew
3 minute read
Announcing the Extreme Flash Storage Server for Exadata Cloud@Customer
Kevin Deihl
2 minute read
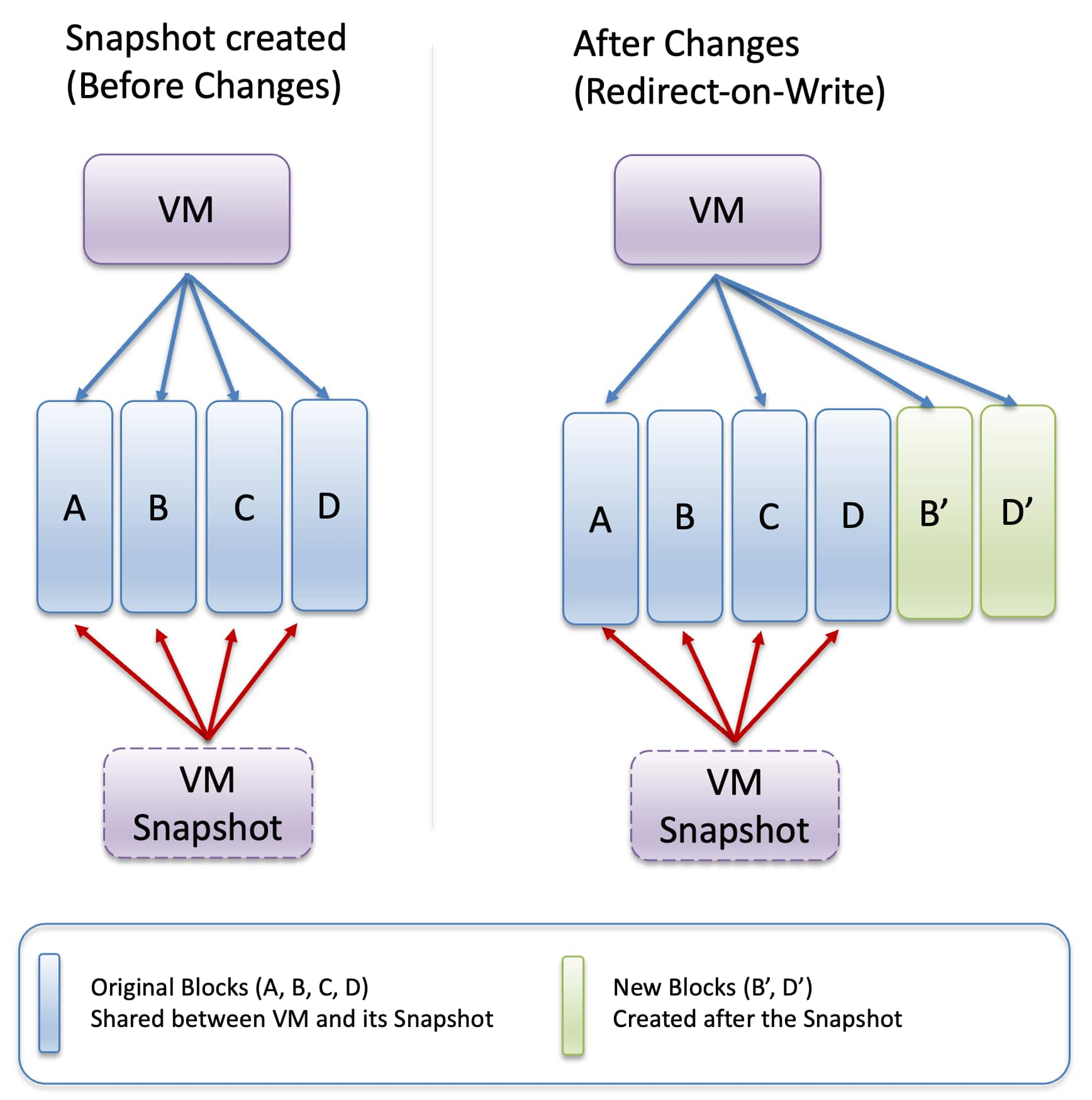
Introducing On‑Demand VM Snapshots for Oracle Exadata Database ...
Deepika Pandhi
5 minute read
Maintain Application Read Availability as a bonus from Oracle True ...
Ilam Siva
5 minute read
Secure Agents, Built for the Enterprise
Allen Hosler
4 minute read
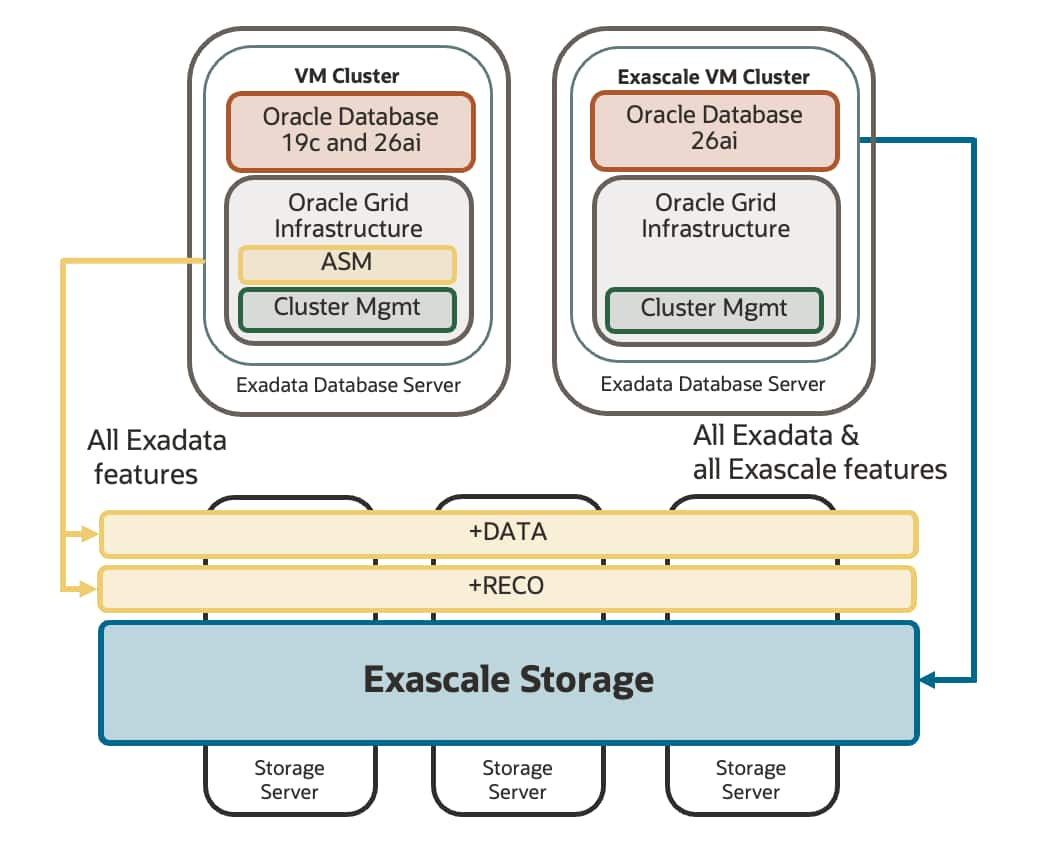
Exascale: Oracle Database Storage in the Age of the Cloud
Nathan Fuzi
7 minute read
Distributed Database
See all
Getting Started with the Vector Index Service – Part 2
Doug Hood
12 minute read
Getting Started with the Vector Index Service – Part 1
Doug Hood
15 minute read
Introducing the Vector Index Service
Doug Hood
3 minute read
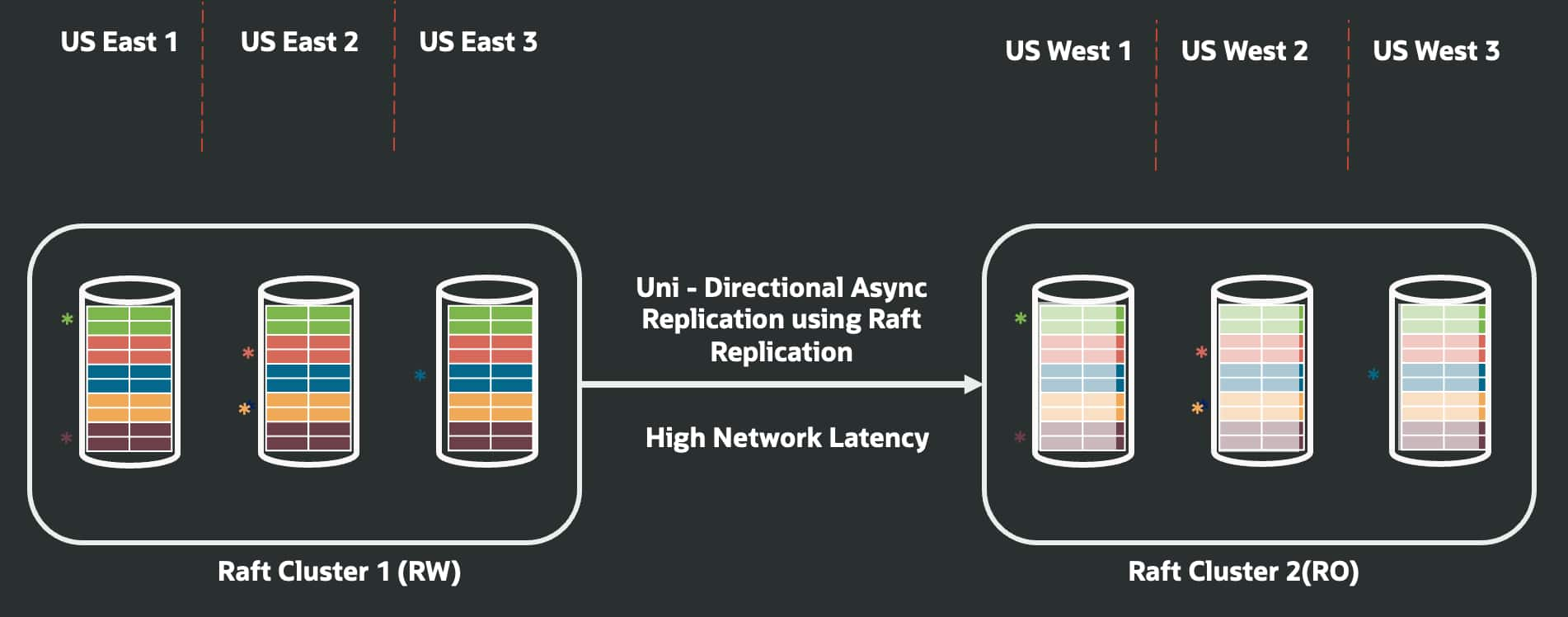
From HA to Multi-Region: Always-On Distributed Databases with ...
Pankaj Chandiramani
Deeksha Sehgal
5 minute read
Maintain Application Read Availability as a bonus from Oracle True ...
Ilam Siva
5 minute read
Building Scalable Vector Search with Oracle Globally Distributed ...
Kuldeep Bora
Kehinde Otubamowo
Deeksha Sehgal
7 minute read
Oracle AI Vector Search on Globally Distributed Databases
Pankaj Chandiramani
Deeksha Sehgal
6 minute read
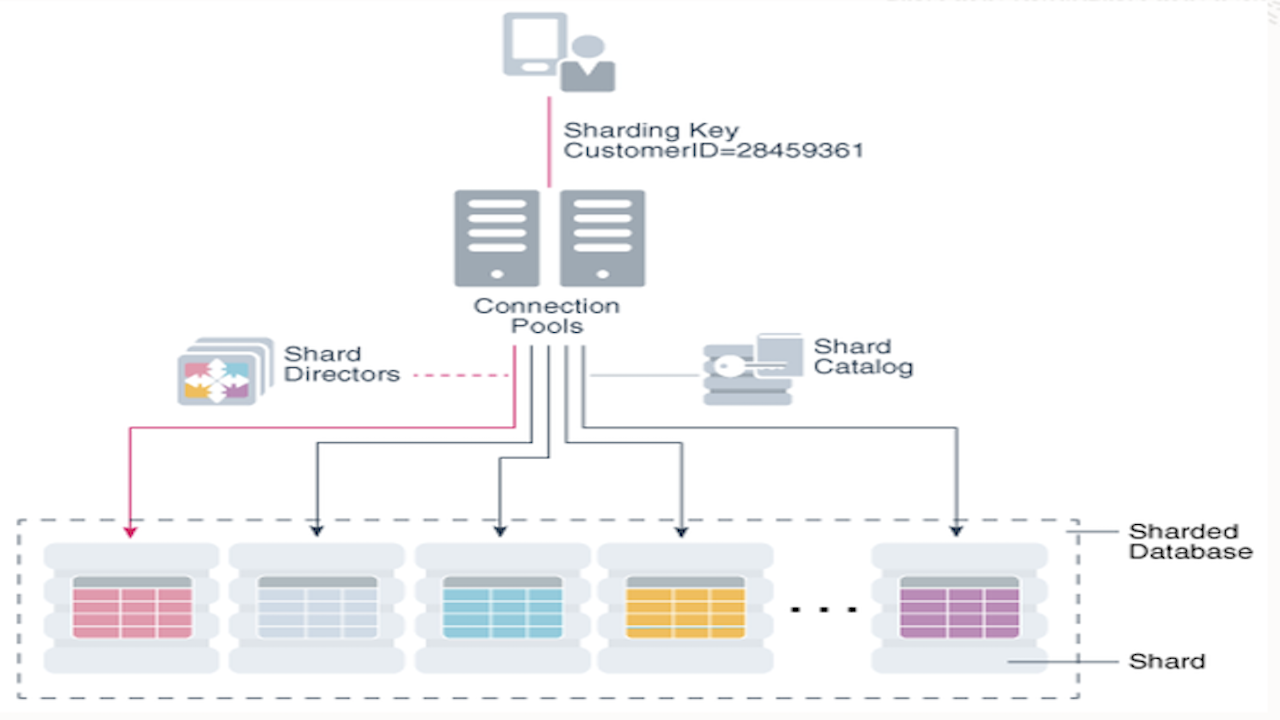
Oracle Sharding: Enterprise-Grade Distributed Database
Deeksha Sehgal
6 minute read
Engineered Systems
See all
Getting Started with the Vector Index Service – Part 2
Doug Hood
12 minute read
VakifBank migrates to Exadata next-gen infrastructure
Dana Serb
Kellsey Ruppel
3 minute read
DZ Bank Accelerates Modernization and Data Protection with Oracle ...
Dana Serb
3 minute read
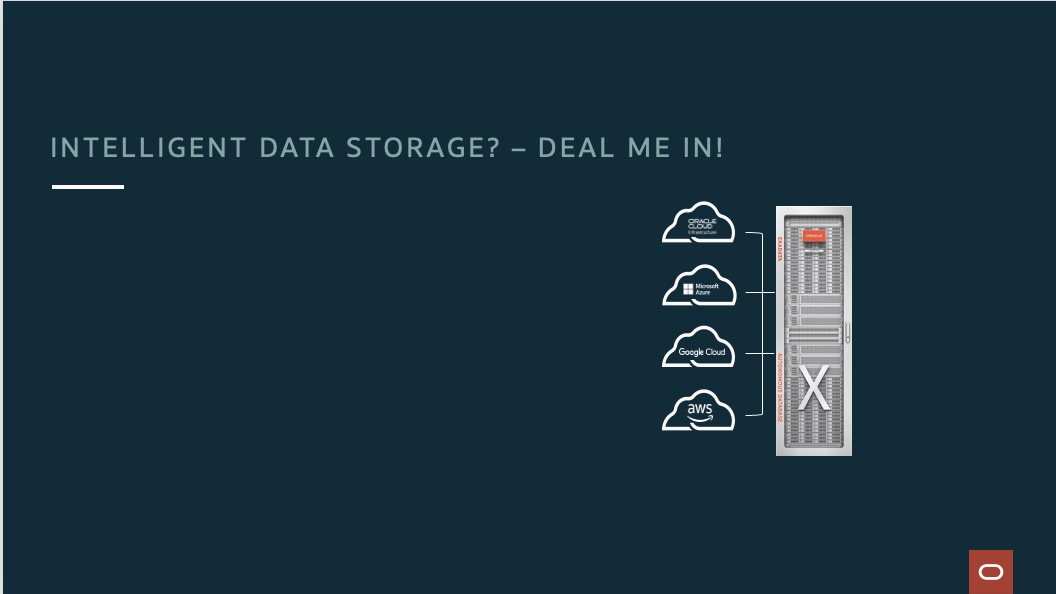
Intelligent Data Storage? – Deal Me In!
Steve Kilgore
2 minute read
Oracle Key Vault is now available on Oracle Database Appliance
Peter Wahl
4 minute read
Run Oracle True Cache on-premise with Oracle Database Appliance (ODA)
Ilam Siva
4 minute read
Don’t Be Fooled by Misleading Data Egress Announcements
Steve Kilgore
10 minute read
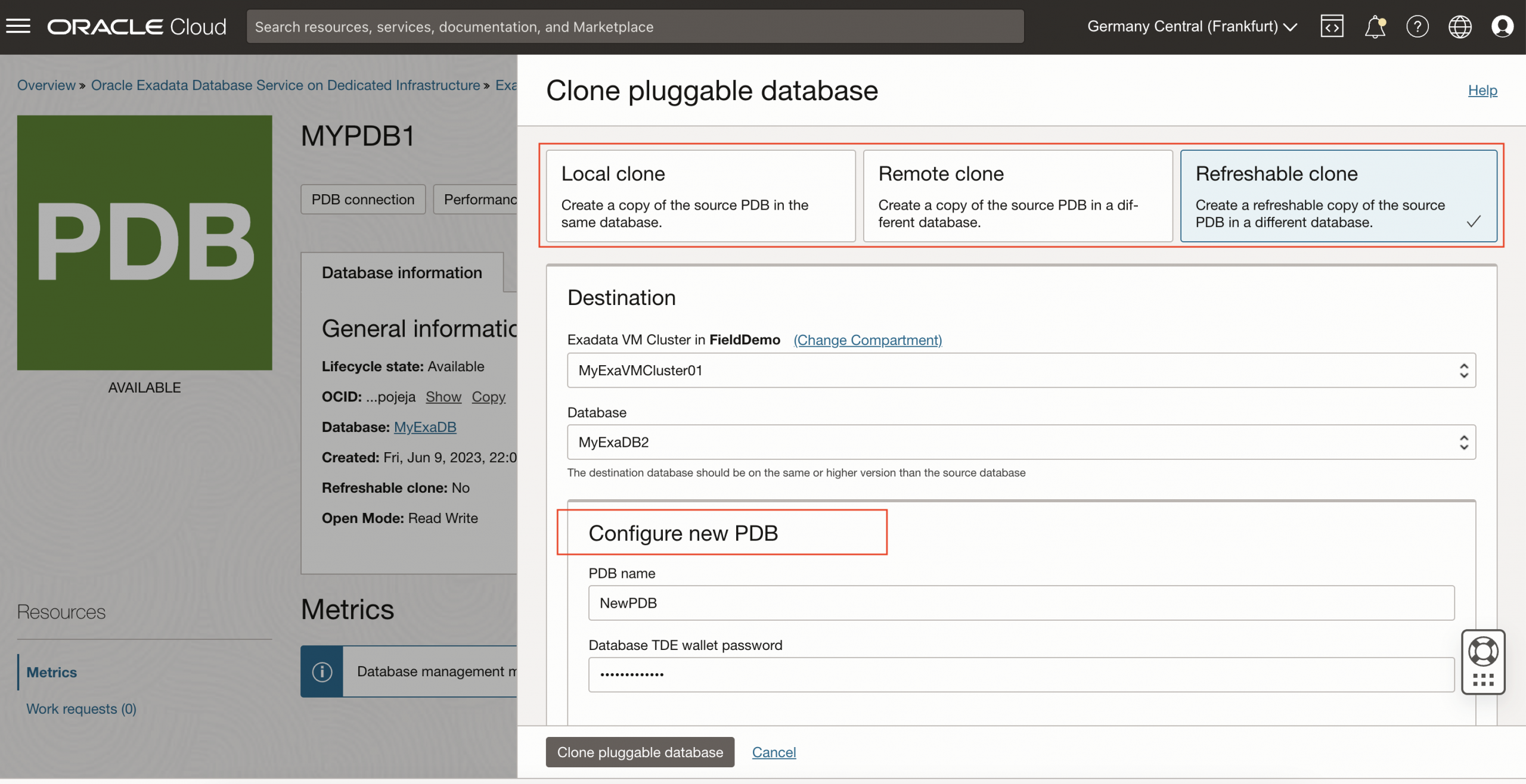
Enhanced PDB automation on Exadata and Base Database Services
Pravin Jha
7 minute read
Graph
See all
Automate Graph Creation with Generative AI
Melliyal Annamalai
4 minute read
Leading Industry Analysts Comment on the Latest AI and Machine ...
Youko Watari
4 minute read
New! Discover connections with SQL Property Graphs in Oracle ...
Marty Gubar
Jayant Sharma
3 minute read
Oracle Graph Learning Path
Rahul Tasker
5 minute read
Graph RAG: Bring the Power of Graphs to Generative AI
Melliyal Annamalai
5 minute read
Join us for Analytics and Data Summit 2023, March 14-16, Redwood ...
Jean Ihm
2 minute read
Graph Analytics for All of Your Data
Melliyal Annamalai
7 minute read
Third Quarterly Update On Oracle Graph (2025)
Rahul Tasker
6 minute read
High Availability
See all
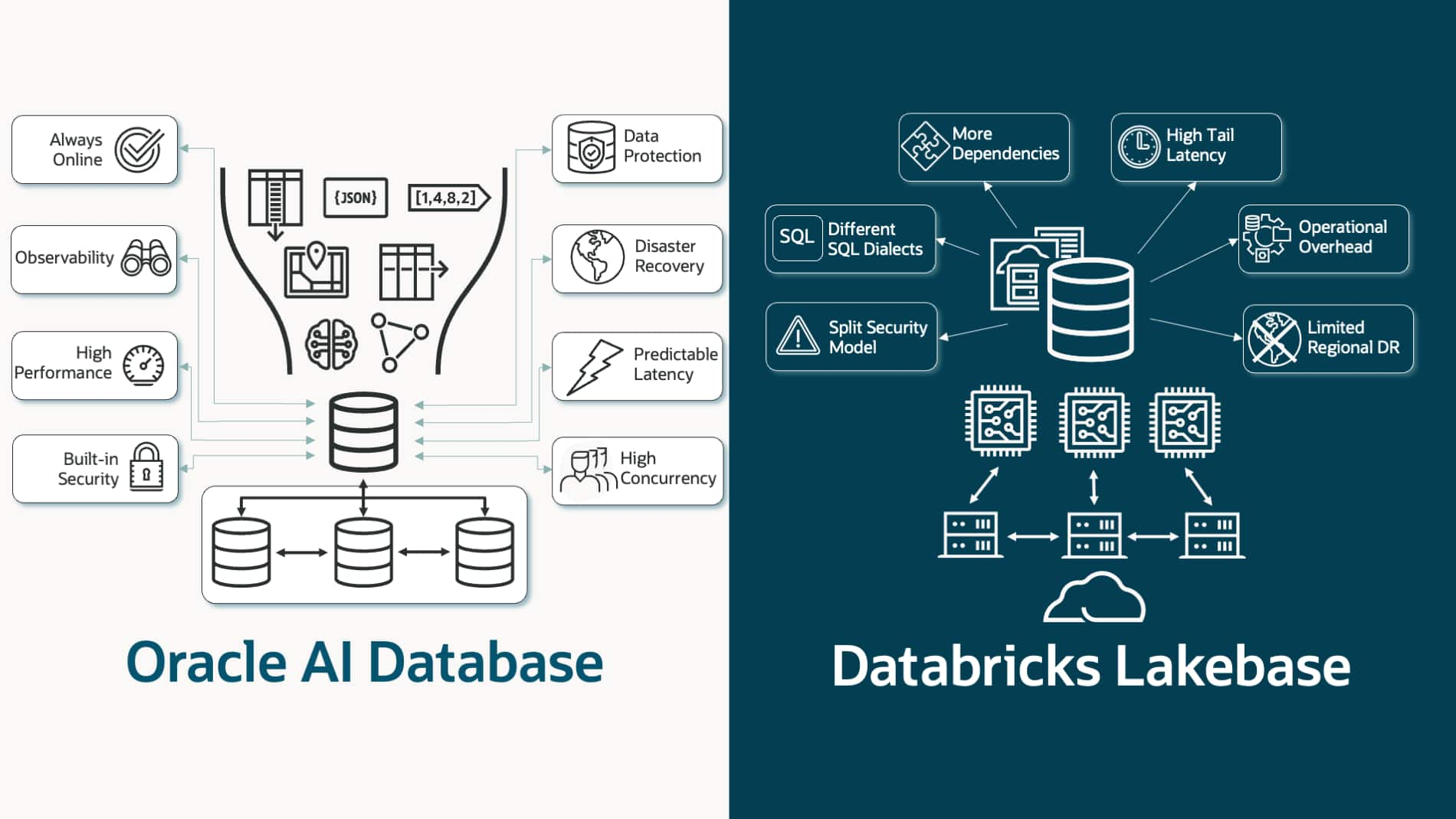
Oracle AI Database vs Databricks Lakebase for Modern OLTP
Ludovico Caldara
14 minute read
Modernize Your Disaster Recovery Strategy: Multiple Standby databases ...
Dileep Thiagarajan
Leo Alvarado
5 minute read
Analyst Perspectives on Oracle AI Database Mission-Critical ...
Ron Craig
7 minute read
Raising the Standard for Mission-Critical Availability and Security ...
Ashish Ray
11 minute read
Maintain Application Read Availability as a bonus from Oracle True ...
Ilam Siva
5 minute read
Oracle AI Vector Search on Globally Distributed Databases
Pankaj Chandiramani
Deeksha Sehgal
6 minute read
VakifBank migrates to Exadata next-gen infrastructure
Dana Serb
Kellsey Ruppel
3 minute read
Cross-Region High Availability for MongoDB API on OCI: Testing with ...
Burak Akkus
Corina Todea
8 minute read
JSON
See all
Cross-Region High Availability for MongoDB API on OCI: Testing with ...
Burak Akkus
Corina Todea
8 minute read
Cross-Region Active-Active Resilience for MongoDB API: Zero Downtime ...
Burak Akkus
Corina Todea
7 minute read
Cross-Region High Availability for MongoDB API on OCI: Testing with ...
Burak Akkus
Corina Todea
28 minute read
Cross-Region Active-Active Goldengate Deployment Step By Step Guide
Burak Akkus
Corina Todea
9 minute read
From SQL to GraphQL: Exploring Native GraphQL Support in Oracle AI ...
Sathishkumar Rangaraj
6 minute read
Native GraphQL in Oracle AI Database 26ai: A New Era of ...
Sathishkumar Rangaraj
3 minute read
SODA with partitioning
Maxim Orgiyan
6 minute read
Get Started with Autonomous JSON Database
Marty Gubar
Keith Laker
3 minute read
Performance
See all
Getting Started with the Vector Index Service – Part 2
Doug Hood
12 minute read
Getting Started with the Vector Index Service – Part 1
Doug Hood
15 minute read
Introducing the Vector Index Service
Doug Hood
3 minute read
Maintain Application Read Availability as a bonus from Oracle True ...
Ilam Siva
5 minute read
VakifBank migrates to Exadata next-gen infrastructure
Dana Serb
Kellsey Ruppel
3 minute read
Unveiling the Power of Oracle Globally Distributed Database: Oracle ...
Deeksha Sehgal
8 minute read
Oracle Transactional Event Queues (TxEventQ): Scalable Messaging ...
Ben Kocabasoglu
6 minute read
Oracle True Cache – AI World Round-Up + Get Hands On
Ilam Siva
4 minute read
Security
See all
Getting Started with the Vector Index Service – Part 2
Doug Hood
12 minute read
Getting Started with the Vector Index Service – Part 1
Doug Hood
15 minute read
Oracle Deep Data Security Is Now Available in Oracle AI Database 26ai
Vipin Samar
5 minute read
Raising the Standard for Mission-Critical Availability and Security ...
Ashish Ray
11 minute read
Introducing Oracle Database Security Central: Taking Control of ...
Vipin Samar
4 minute read
Introducing Oracle Deep Data Security: Identity-Aware Data Access ...
Roger Wigenstam
3 minute read
Sometimes the needle jumps! Why you need to care about ...
Vipin Samar
6 minute read
You Can’t Modernize Database Cryptography You Can’t See – First ...
Yi Ouyang
19 minute read
Spatial
See all
Unlock Spatial Insights Faster with Spatial Studio, Now Built into ...
David Lapp
4 minute read
Accelerating Geospatial Innovation with CARTO on Oracle Autonomous AI ...
Hans Viehmann
5 minute read
Leading Industry Analysts Comment on the Latest AI and Machine ...
Youko Watari
4 minute read
Join us for Analytics and Data Summit 2023, March 14-16, Redwood ...
Jean Ihm
2 minute read
What’s new in Oracle Spatial Studio 25.1
Denise Myrick
2 minute read
Oracle named to Geoawesome’s Global Top 100 Geospatial Companies 2025 ...
Youko Watari
Jean Ihm
3 minute read
Optimize Streaming Map Data with Vector Tile Cache in Oracle Spatial
Rahul Tasker
3 minute read
Spatial Studio 24.2 Now Available
Denise Myrick
2 minute read
Autonomous Health Framework
See all
AHF Fleet Insights 25.1 with Single-Instance Support and More!
Gareth Chapman
4 minute read
AHF Fleet Insights 25.2 with AI powered Capacity Analysis and ...
Rohini Ramadath
7 minute read
Explore Diagnostic Collections Triggering Events with AHF 25.3
Gareth Chapman
5 minute read
Support for Exadata X11M and Exadata System Software 25.1 with AHF ...
Gareth Chapman
5 minute read
Maximizing Application Resilience, Performance, and Security with AHF ...
Gareth Chapman
11 minute read
Optimize Database Performance and Hardware Usage with AHF 24.11
Gareth Chapman
5 minute read
New Automatic Solutions for Node Eviction with AHF 24.10
Gareth Chapman
6 minute read
Introducing AHF Fleet Insights
Gareth Chapman
3 minute read
Select AI
See all
Building an Autonomous Fraud Detection Pipeline with Autonomous AI ...
German Viscuso
10 minute read
Autonomous AI Database
See all
Cross-Platform Analytics: Oracle Autonomous AI Database Reads ...
Sathishkumar Rangaraj
9 minute read
Bridging Oracle Autonomous AI Database and Snowflake: Reading Iceberg ...
Sathishkumar Rangaraj
8 minute read
Turning Invoice Compliance into a Scalable, Auditable Workflow with ...
Kumar G Varun
6 minute read
Building an Autonomous Fraud Detection Pipeline with Autonomous AI ...
German Viscuso
10 minute read
Enterprise AI Search Needs a New Approach
Allen Hosler
4 minute read
Oracle AI
See all
Cross-Platform Analytics: Oracle Autonomous AI Database Reads ...
Sathishkumar Rangaraj
9 minute read
Oracle AI Database Private Agent Factory: Enterprise FAQ
Kumar G Varun
10 minute read
Turning Invoice Compliance into a Scalable, Auditable Workflow with ...
Kumar G Varun
6 minute read
Technical Solutions
See all
Cross-Platform Analytics: Oracle Autonomous AI Database Reads ...
Sathishkumar Rangaraj
9 minute read
Bridging Oracle Autonomous AI Database and Snowflake: Reading Iceberg ...
Sathishkumar Rangaraj
8 minute read
Receive the latest blog updates
Subscribe to our blog
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers