This blog was originally published on Feb 7, 2019.
A new, improved Data Loading facility is one of the new features in Application Express 19.1. This new feature is not only a dramatic improvement of the existing CSV Data Upload utility – it also supports more file types, detects settings automatically, runs in the background and comes with a PL/SQL API, which application developers can use.
This blog posting will introduces the new Data Upload facility in Application Express SQL Workshop. You can try this feature out on the APEX 19.1 Early Adopter Instance, available on https://apexea.oracle.com.
SQL Workshop Data Loading
To access the new Data Loading utility, Navigate to SQL Workshop > Utilities > Data Workshop.
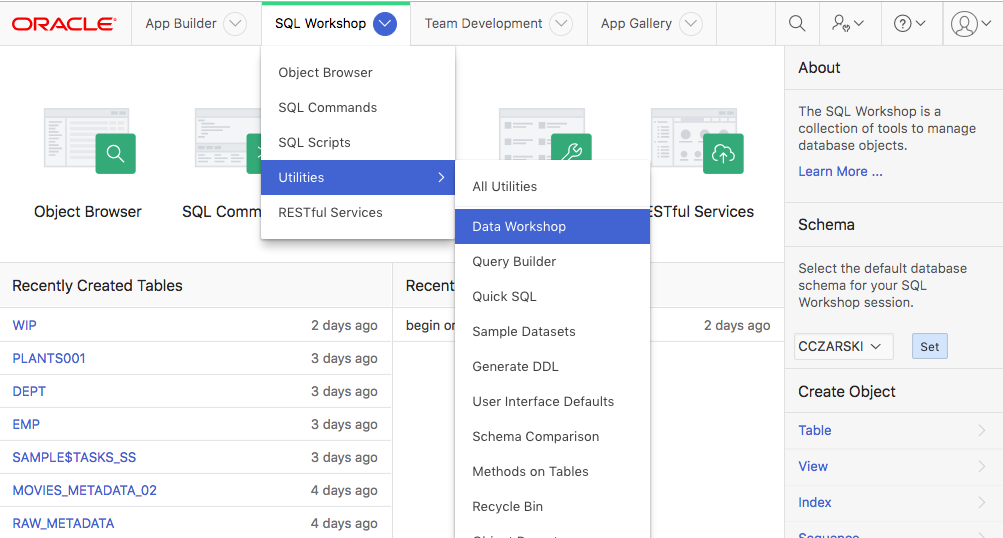
Click on Load Data
You’ll see a drop zone which allows to drag files to be uploaded.
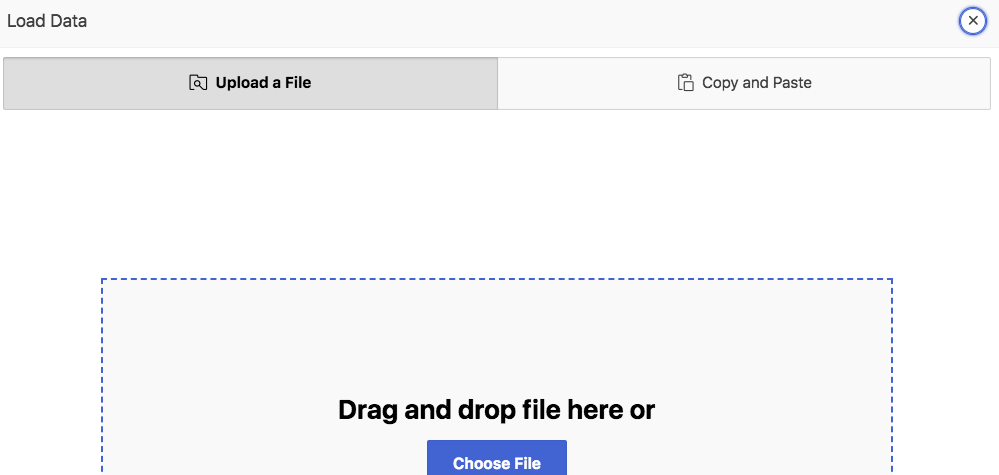
Drag a file to be uploaded here. The Data Loading utility supports Delimited files (CSV, tab-delimited), as previous APEX versions did. Beyond that, also XLSX files (Excel workbooks), JSON and XML files are supported.
CSV Files
CSV Files must have an extension of either .txt or .csv. After dropping such a file …
- it will be uploaded
- the parser will auto-detect the delimiter character
- the parser will sample the first 200 rows of the file to detect data types
APEX will present a preview of the file contents as follows:
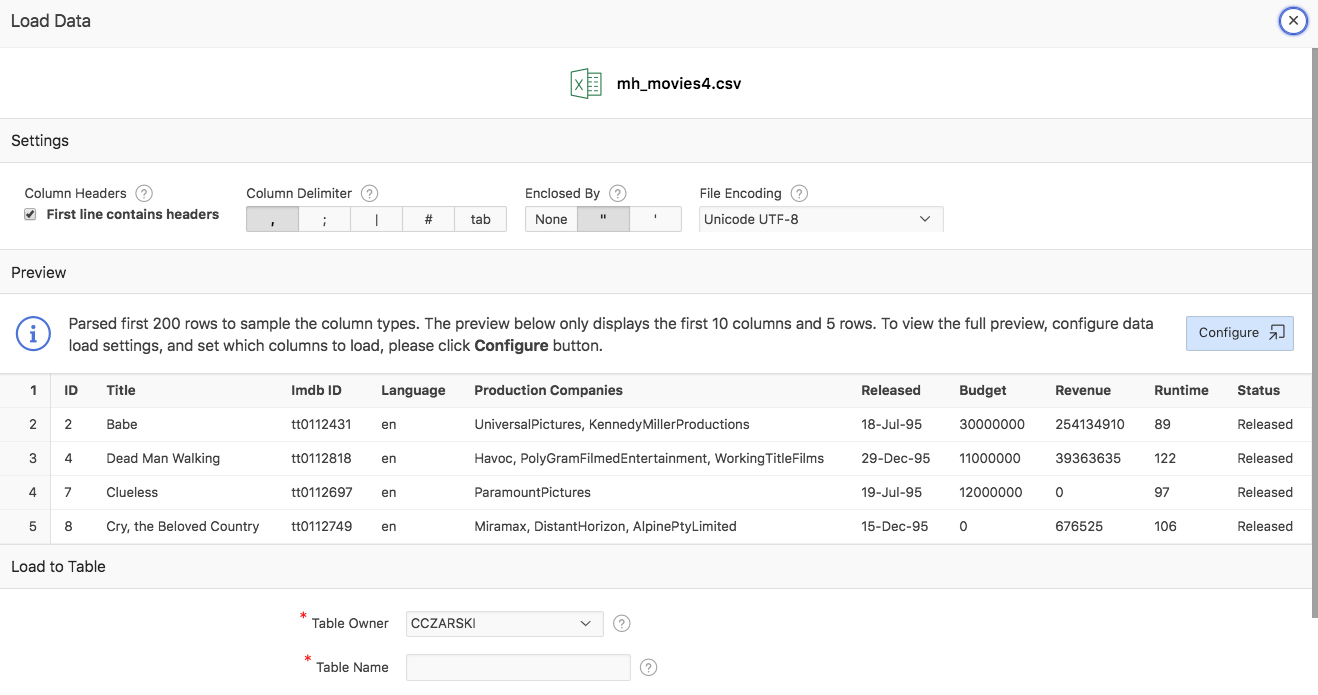
If APEX does not get the parser configuration right, settings can be adjusted …
- The delimiter character can be chosen as the comma (,), semicolon (;), pipe (|), hash (#) or the tab character. APEX detects this automatically
- Choose whether the first rows contains column headers (default is Yes).
- Choose whether contents are optionally enclosed by quotes. APEX assumes Yes by default. If you know that this is not the case, you might switch that off.
- The file encoding as assumed as Unicode (UTF-8). If that is not the case, pick the right file encoding from the select list.
Click the Configure button and then the Columns to Load tab in order to get some insight on the detected data types.
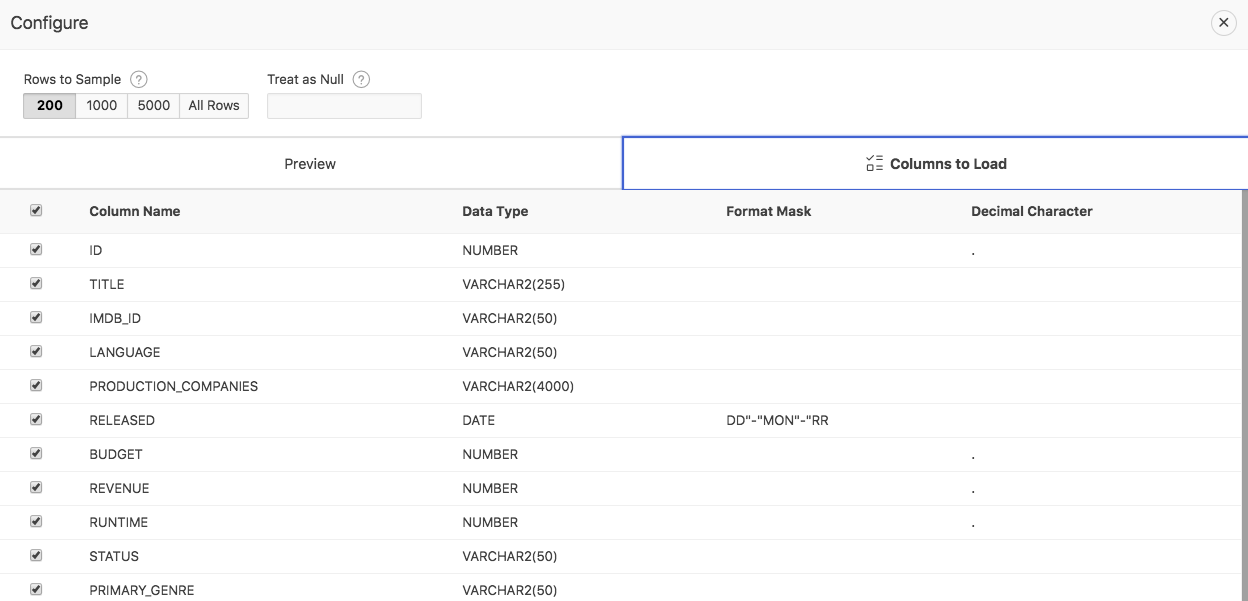
APEX shows which data types it has detected. All format masks for NUMBER, DATE or TIMESTAMP data types are also detected automatically. Decimal and group characters are detected individually for each NUMBER column.
For larger data sets, it might make sense to increase the Rows to Sample (click the 1000, 5000 or All Rows pill button) in order to have APEX sample more rows. The more rows APEX samples, the more accurate the detected data types will be.
Once you you’re sure that settings are fine, click the Save Changes button. The dialog closes and the previous dialog reloads.
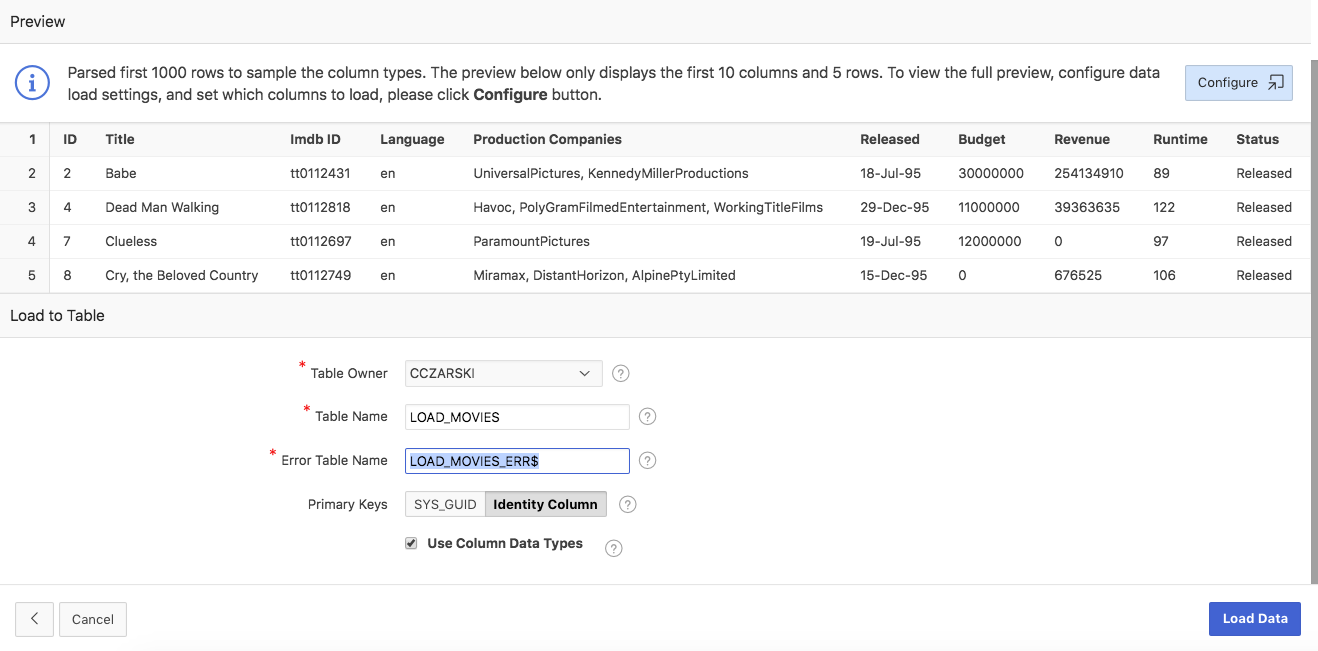 Now provide a name for the new table to be created. The Error Table Name will be used to create a second table: This error table will be used to store rows, which cannot be inserted into the target table.
Now provide a name for the new table to be created. The Error Table Name will be used to create a second table: This error table will be used to store rows, which cannot be inserted into the target table.
That can happen, if APEX e.g. only samples the first 200 rows and detects a column as NUMBER. But later on, the file contains non-numeric values for that column – those rows will be stored in the error table (for the experts: APEX leverages the DML Error Logging database feature here).
The error table is a normal Oracle table with the same columns as the target table, but all defined as VARCHAR2(4000). You can review the error table in SQL Workshop after load and manually process these rows. If APEX is able to load all rows to the target table successfully, it will drop the (empty) error table automatically.
When the Use Column Data Types checkbox is unchecked, APEX will not use the detected column data types – instead the target table columns will all be created as VARCHAR2(4000).
On Database 12c or higher, you can choose whether the Primary Key column will be generated using the Identity Column feature or whether a globally unique identifier (SYS_GUID) shall be used. The difference is values and space requirements. Identity Column values are like sequences – they start with 1 and increase. SYS_GUID values are globally unique, hard to predict, but require more space than the compact Identity Column numbers.
Configure your load as desired and click the Load Data button. Add loading will be executed in the background, so if you close the dialog while loading is in progress, it will continue.
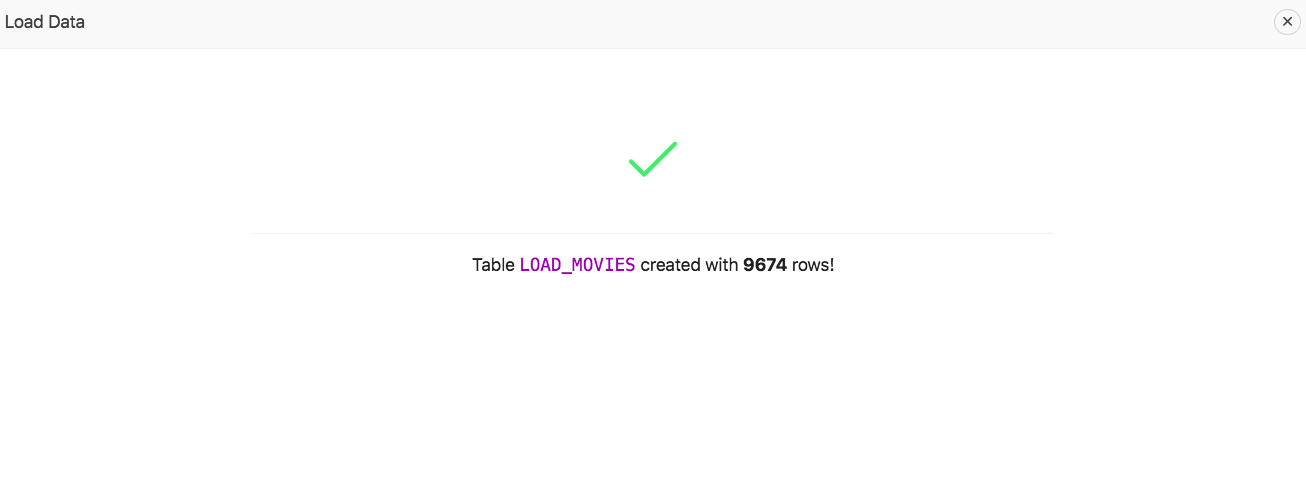
Once Data Loading is finished, you shall see a success message. In this case, all data has been loaded to the target table successfully. The (empty) error table has been dropped.
If some rows cannot be loaded to the target table, they will be stored to the error table. The success message will then look as follows:
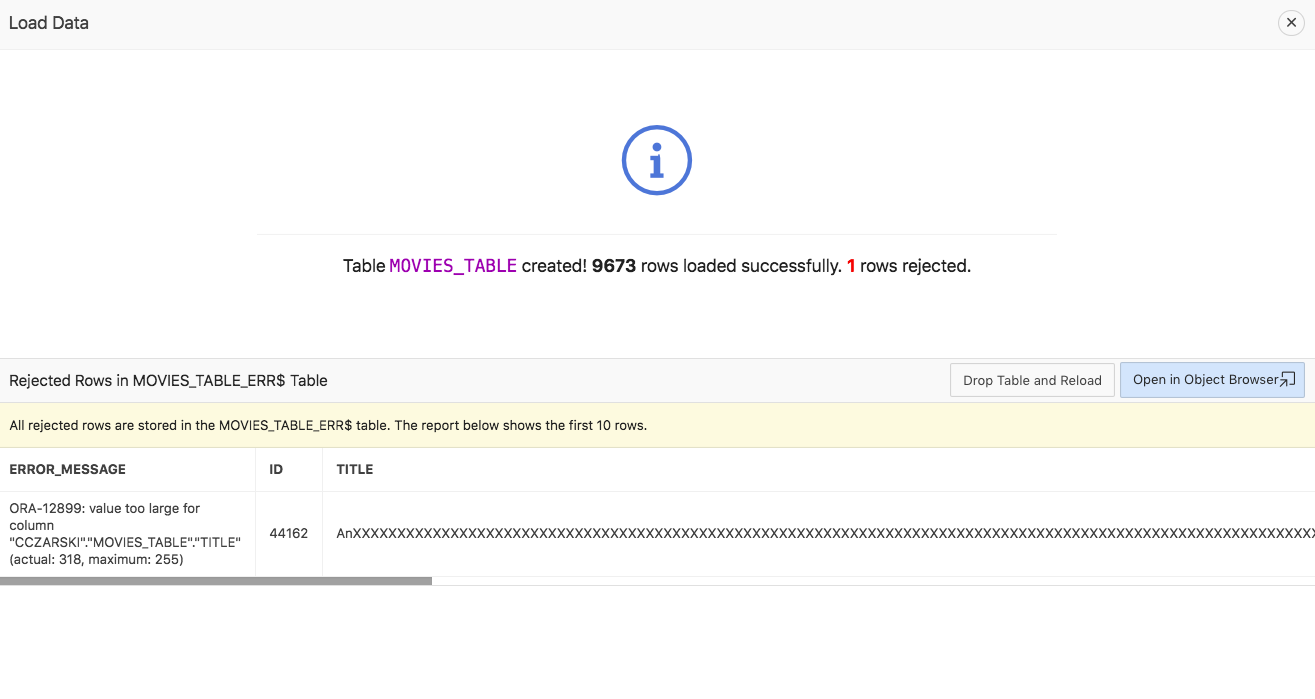
One option is to drop the tables and retry the data loading operation, the other one would be to continue with the target table as-is. The error table is available for manual processing in SQL Workshop, SQL Developer, SQL*Plus or other development tools.
Loading XLSX files
Loading XLSX files is similar to loading CSV files. Of course, there is no need to detect or to choose delimiter or enclosing characters. So, the preview dialog looks as follows after uploading an XLSX file.
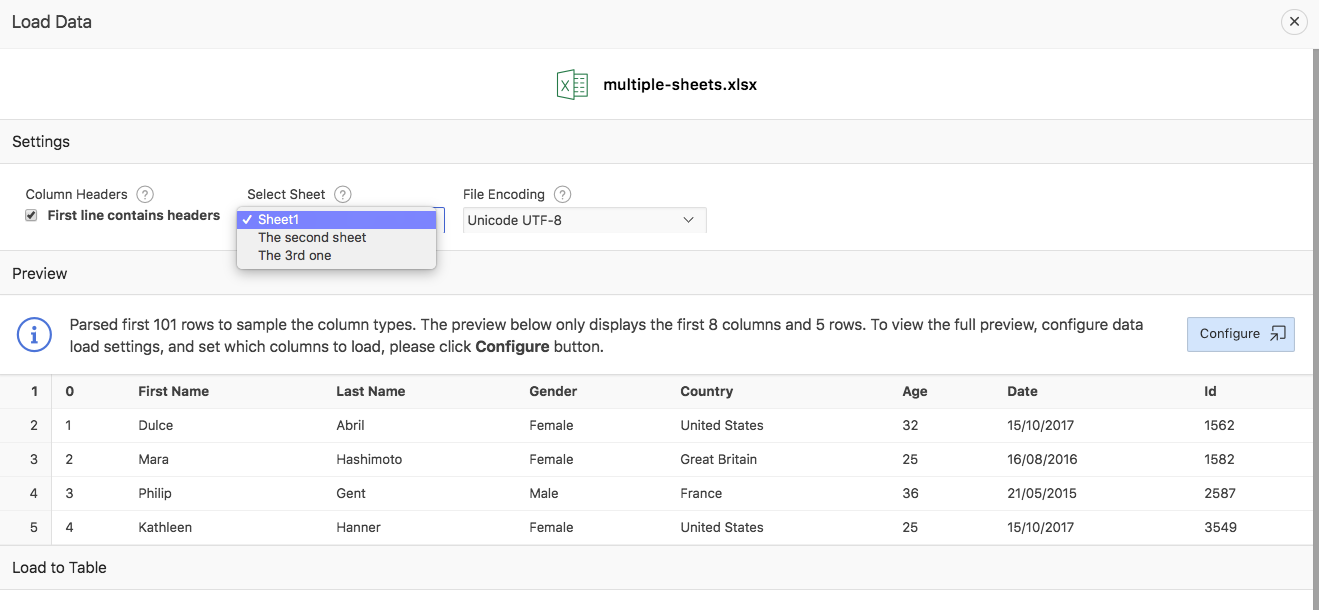
If the uploaded XLSX file contains multiple worksheets, APEX will pick the first sheet by default. To load another sheet, pick it from the Select Sheet select list. The First lines contains headers checkbox works similar to CSV files. The same is true for the Configure dialog: the behavior is the same as it is for CSV files. Uploading XLSX files is limited to 20MB for each file.
Loading XML files
XML files can also be uploaded to APEX. However, APEX supports only “flat” XML structures, like the following, which can easily be mapped to a table and columns. XML structures with multiple levels of nesting cannot be loaded by the new Data Loading wizard.
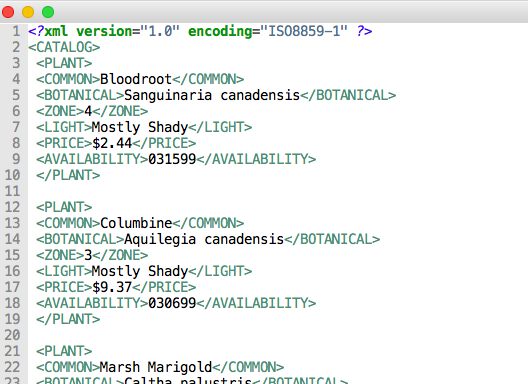
APEX will look for the first repeating XML (here: PLANT) Tag inside the document (root) element (CATALOG). All XML tags within the PLANT tag will be treated as columns.
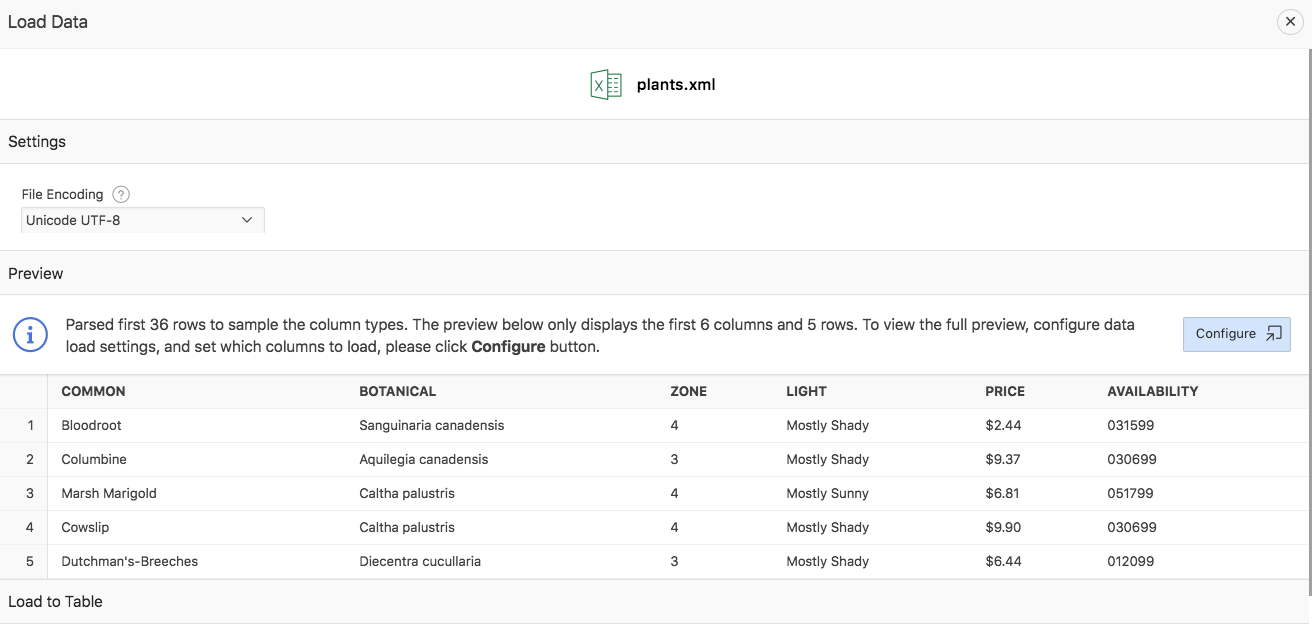
Of course, there are no delimiter or enclosing characters to choose. Also the column names are derived from the XML tag names, so there is no First lines contains headers checkbox. XML files are limited to 10MB each.
Loading JSON files.
Loading JSON files works similar to loading XML files. Only “flat” structures are supported – deeply nested JSON structures cannot be loaded.
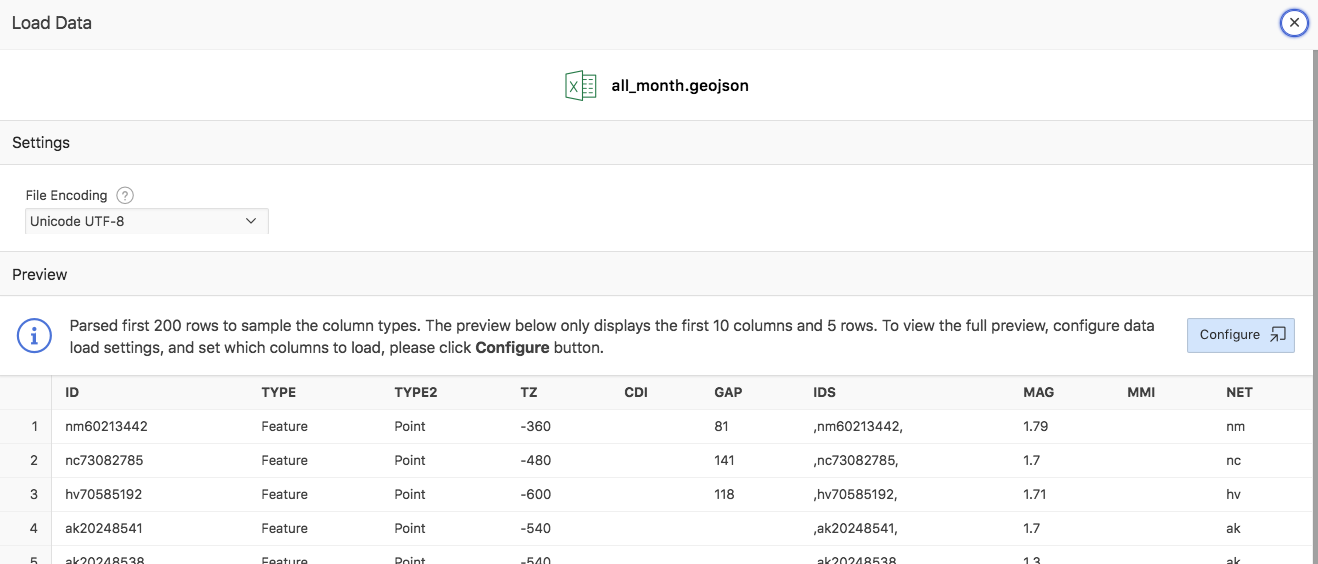
JSON files are limited to 20MB on 11g and 12.1 databases. For Oracle Database 12.2 or higher, there is no size limit for JSON files.
Summary
The new Data Loading wizard in Application Express 19.1 makes it super-easy to load Spreadsheet, CSV, XML or JSON data as a table into your APEX workspace. Unlike previous versions, APEX detects almost everything automatically – there is no need any more to manually pick data types, provide format masks or decimal characters.
The actual Data Loading runs in the background – so the dialog can be dismissed if a larger file is being uploaded. If “bad” rows cannot be inserted into the target table, the whole load is not “lost” any more – all rows are still accessible in the error table and can be post-processed manually.
But there is more …
The fundamental piece of functionality, the new file parser, is available as a PL/SQL API as well: Using the PARSE function within the new APEX_DATA_PARSER package, developers can parse JSON, XML, CSV or XLSX files themselves – and implement their own processing of uploaded data. This will be explained in more detail in a separate blog posting.
Stay tuned.
