This article follows up on previous articles about Governed Data Enrichments powered by Custom Reference Knowledge and How to easily and quickly create an automated and governed data standardization process in Oracle Analytics. Both of these articles explain ways to leverage the semantic enrichments feature in the Dataset editor. To recap the core feature, when data is ingested by Oracle Analytics, it triggers several AI processes including a deep semantic profile. Semantic profiling applies NLP and ML, leveraging a linked set of domain knowledge to identify and capture important patterns, domains, semantic types, entities, shape, distribution, uniqueness, and many other features of the data, both at the dataset and individual column levels. This information is presented to the user in the form of easily consumable Data Quality Insights, a set of interactive visual tiles showing the discovered types, distribution, and shape of the data. The semantic features are stored as metadata and used to recognize and automatically connect datasets to related entities and generate suggested transforms and links to add dimensions and measures that are exposed to the users as enrichment recommendations. In addition, Custom Knowledge support allows users to add their own reference knowledge to enable the system to discover custom semantic types, offer customized enrichments, and guide all users to the same curated datasets to be used for enrichments.
This article provides an overview of how, in addition to semantic enrichments being exposed in the Dataset editor, there are also options to expose them to workbook authors as on-demand data enrichments. The article includes examples for enriching your data during the visualization authoring process by simply dragging and dropping semantic enrichments that are displayed in the data elements tree under any classified column, which are the result of the deep semantic profiling done during the ingestion process explained above and in the previous articles referenced.
So let’s get started with some examples. In the Dataset editor, enrichments are displayed as recommendations where they can be individually accepted by the dataset authors and become a permanent part of the dataset.

With the On-Demand Enrichments in workbooks feature, all enrichments associated with columns during profiling are available in the Data Elements tree in workbooks. Columns in the Data Elements tree that have enrichments available are displayed as an arrow indicating that there are enrichments that can be used in the visualizations. This feature can remove the guesswork from the dataset author as to which enrichments the consumers of the dataset might be interested in. They’re all available in the workbook authoring experience as on-demand and don’t become part of the dataset until dragged to the visualization surface. Notice below the arrow next to ZIP_CODE and as we expand it, we see the same enrichment recommendations as the dataset author saw in the Dataset editor. Also notice that the feature supports both system knowledge, which is the source of the zip code enrichments, and custom knowledge, which is the source of the enrichments for the occupation column in the dataset. See the articles mentioned earlier for detailed information about system and custom knowledge.
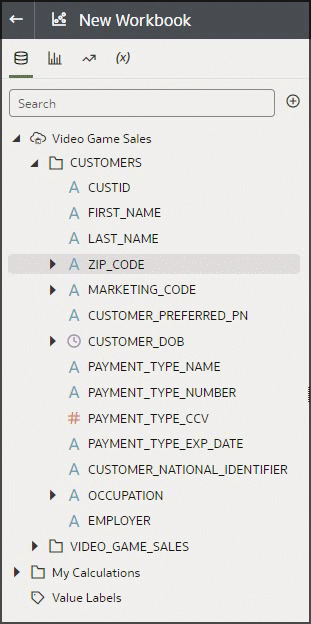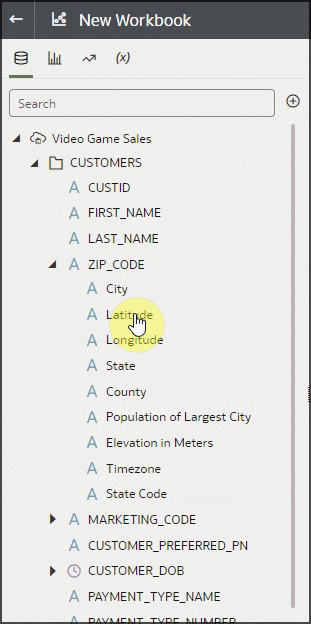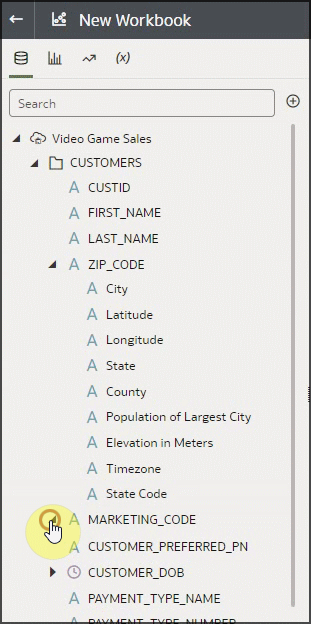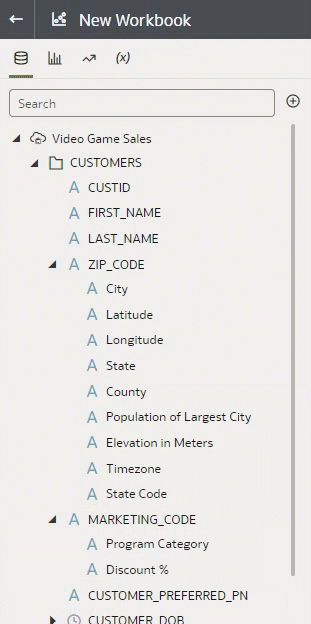
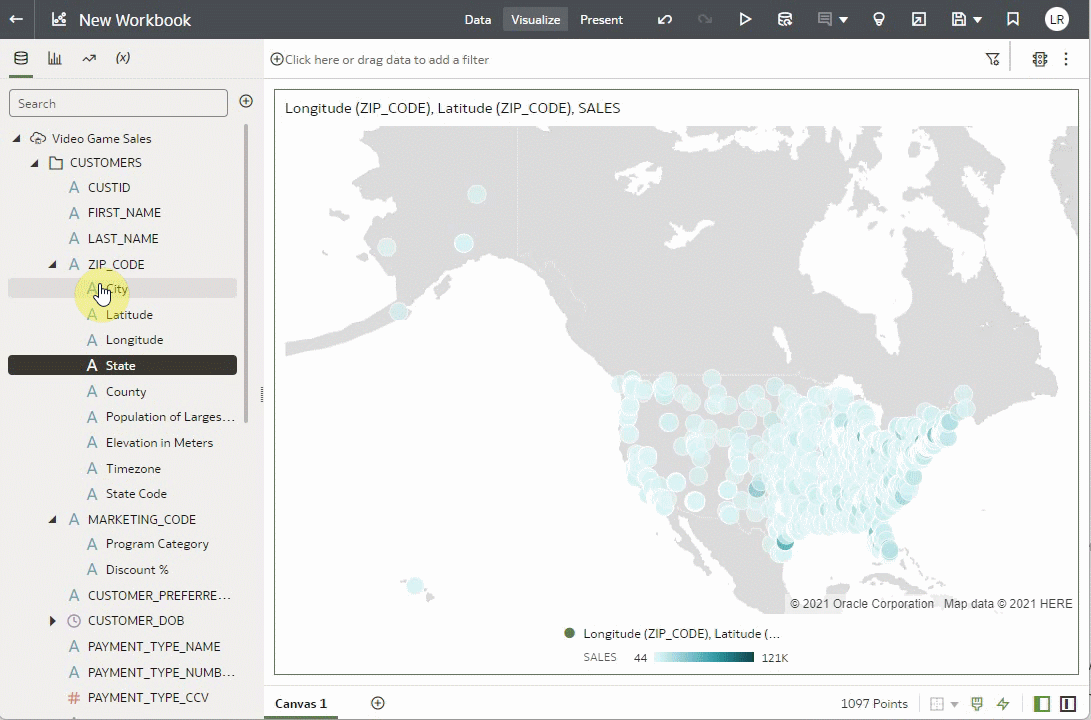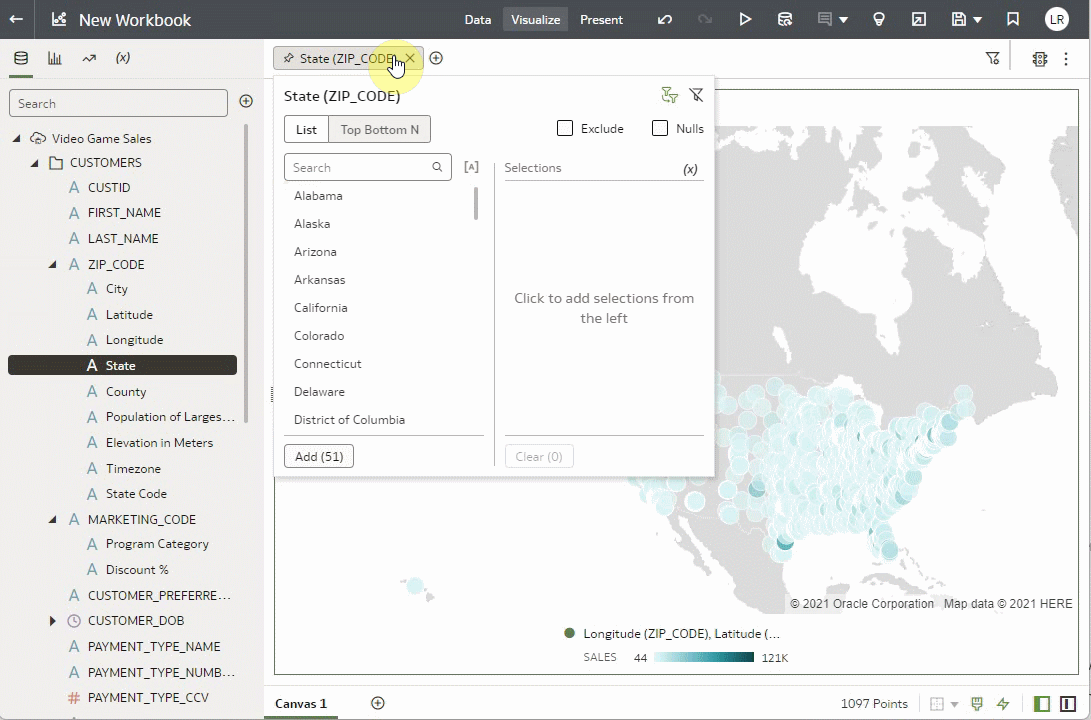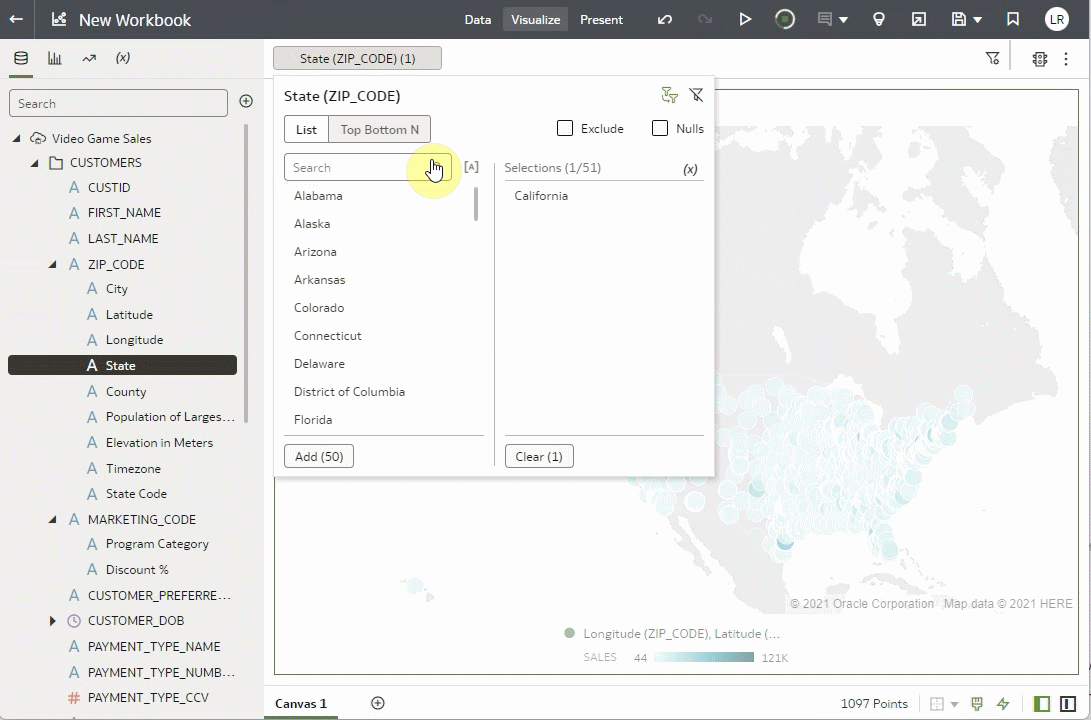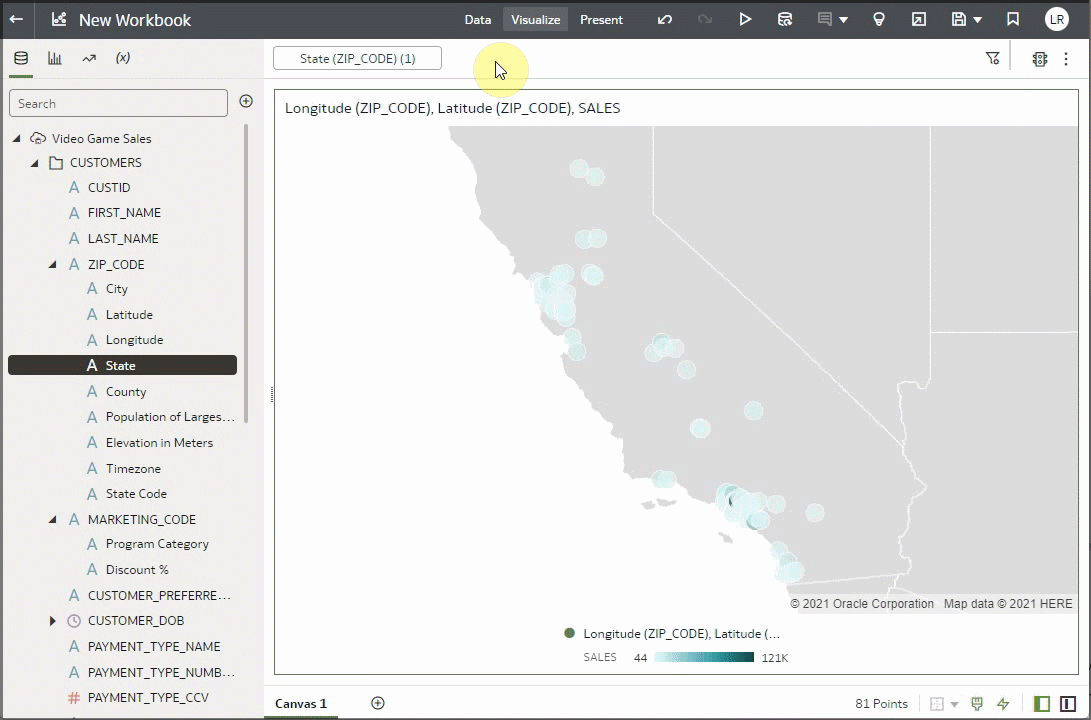
You can use enrichments directly in visualizations, with or without the parent column. To see the enrichments, simply click the arrow to expand. For example, in this zip code column, there are several enrichments available. These enrichment columns can be used as if they were regular columns in your data. You can also use the enrichments in visualizations with or without their parent columns. Let’s create a map visualization with the Lon/Lat columns and the Sales figures for those locations. Notice that the ZIP_CODE column, which is the source of the enrichments, isn’t used.
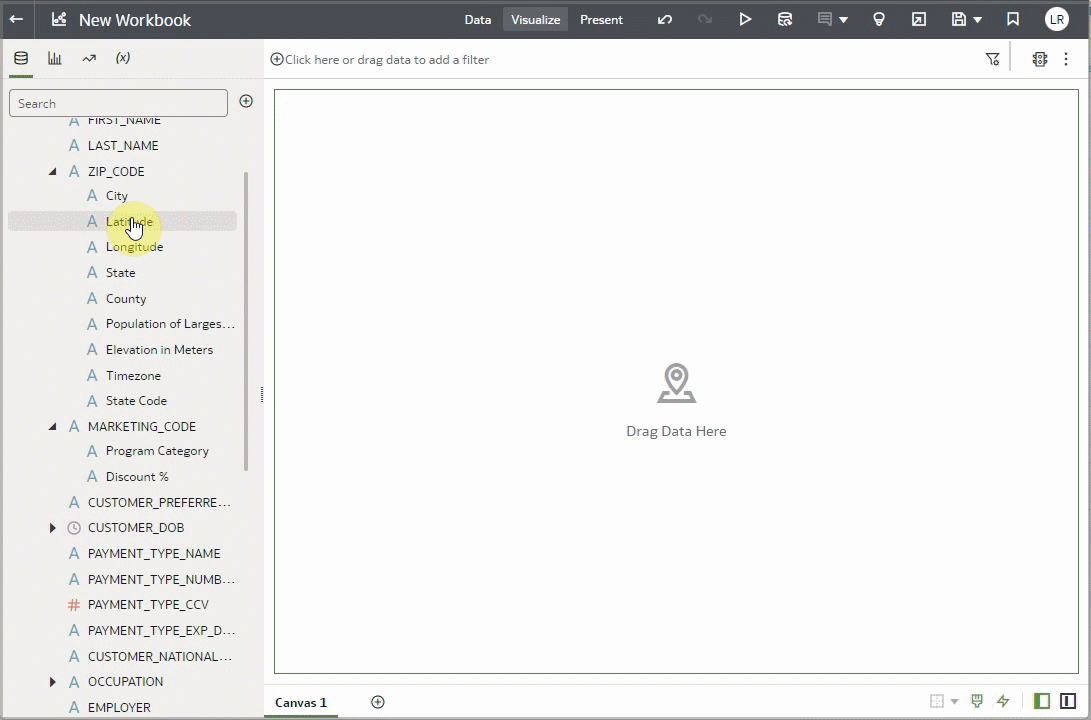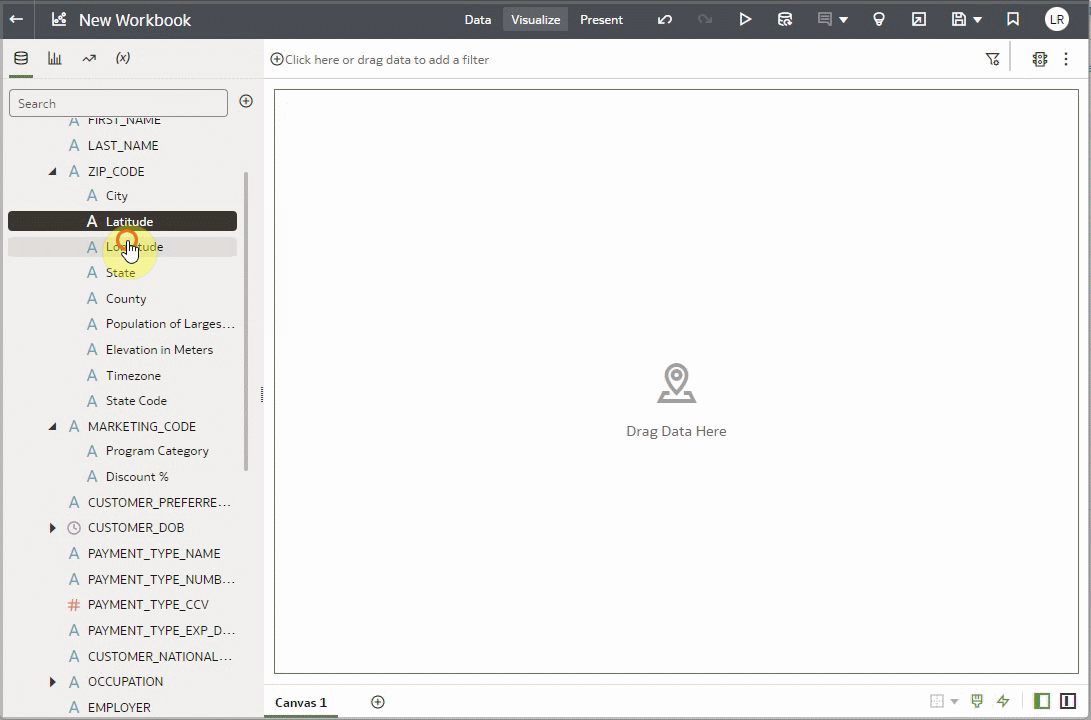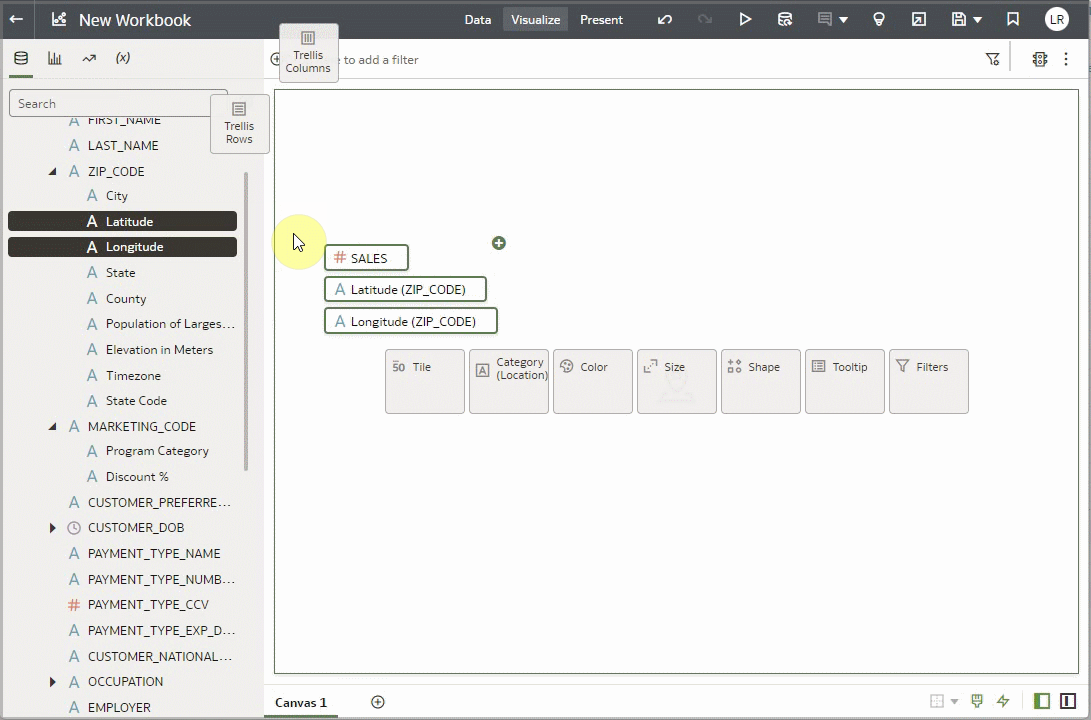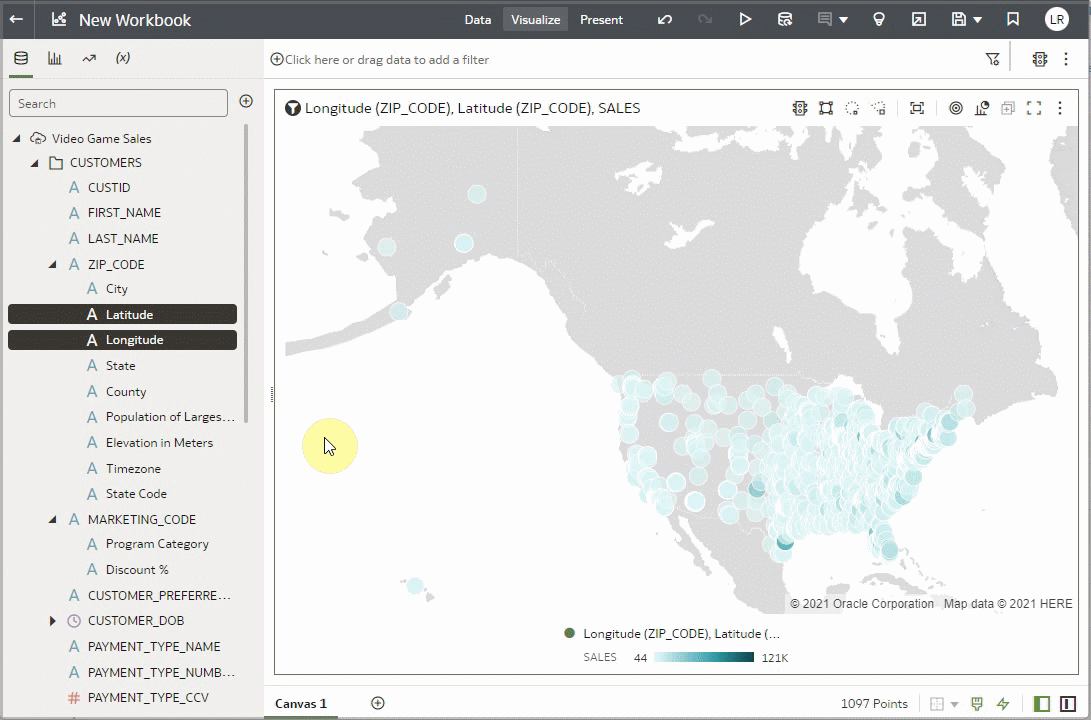
You can use on-demand enrichments as filters. Notice that the visualization above is for the entire dataset and has sales for all of the United States. Let’s use another of the enrichment columns to filter to only the sales figures for California to see if we can find some insights for sales in California.
Now, the above was an example of System Reference Knowledge, which is available with all instances of Oracle Analytics. But enrichments can also come from Custom Reference Knowledge. You can ask your administrator to create reference knowledge files and the enrichments display in the workbooks for use. In the following example, notice that the Marketing Code column has an indicator that there are enrichments. If we expand those, we see two enrichments that are coming from custom reference knowledge. To learn more about custom knowledge and how to leverage the feature to enrich and standardize your datasets, see the articles mentioned earlier for detailed information. Let’s create a visualization with Sales in California by Program, which is an enrichment coming from the Marketing Code custom reference knowledge.
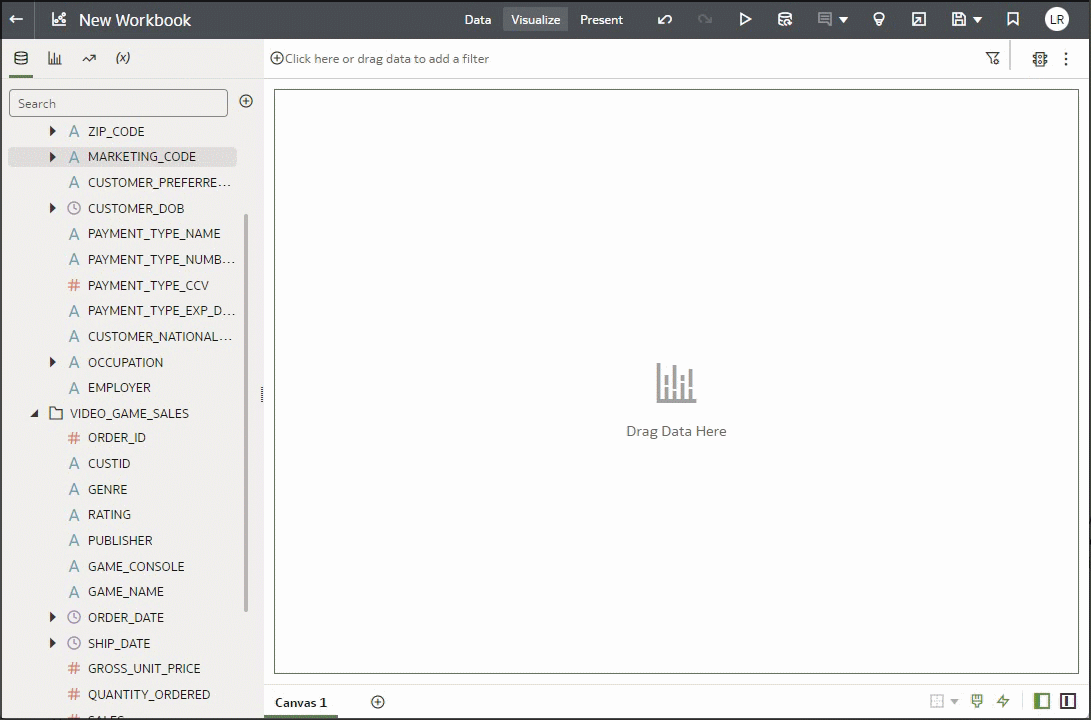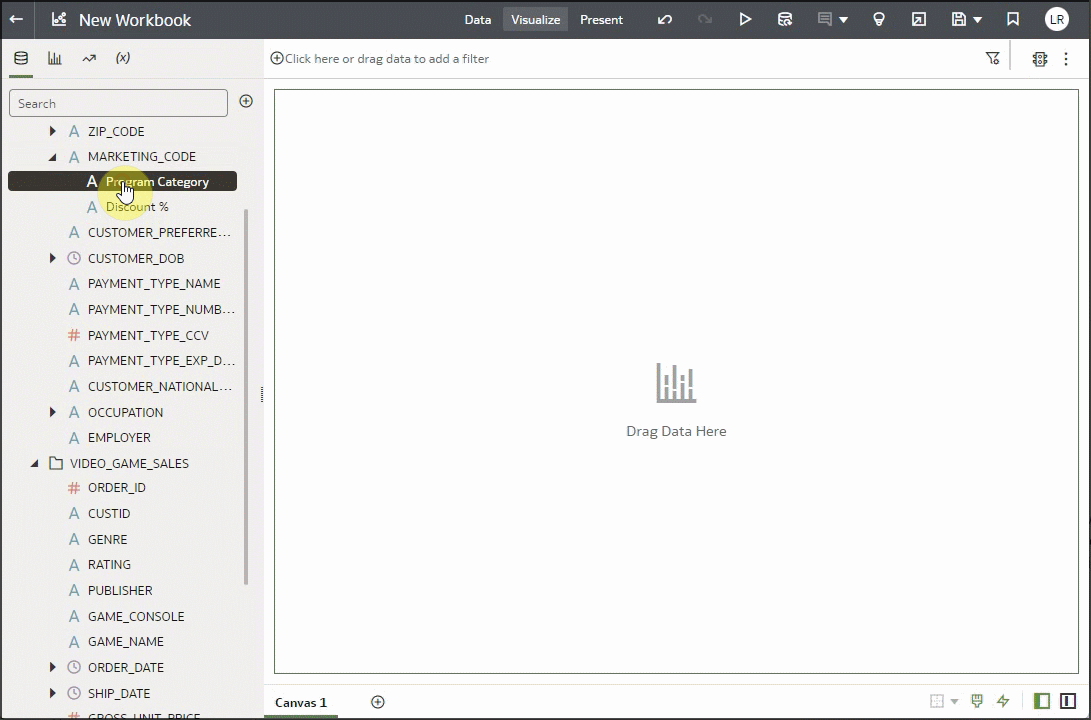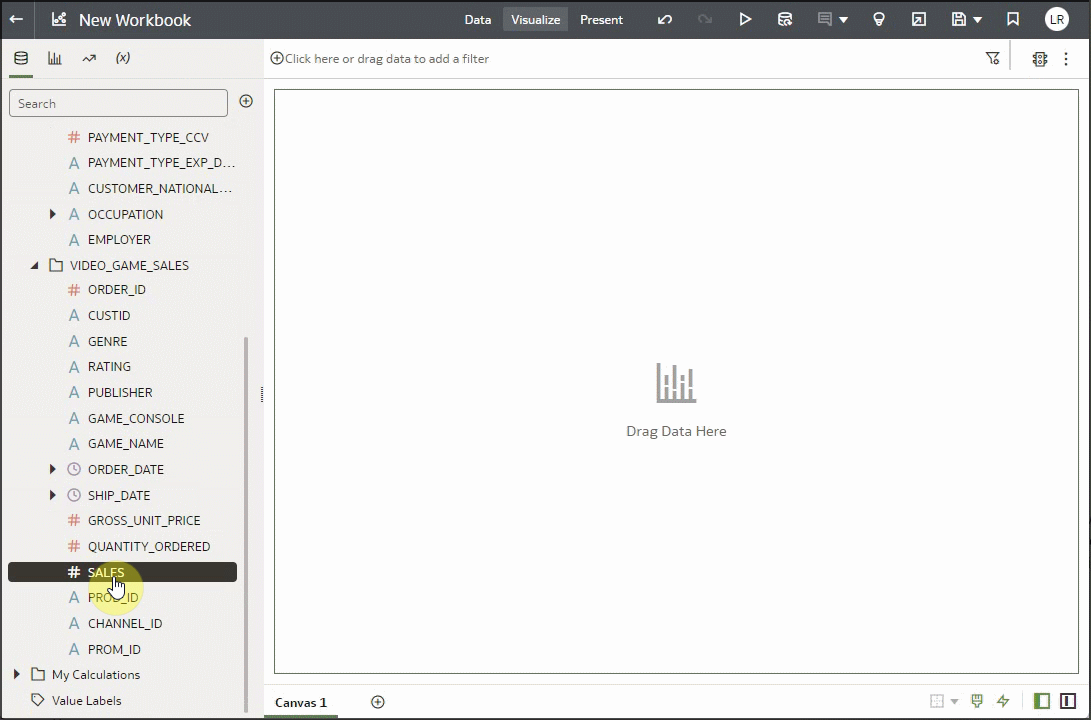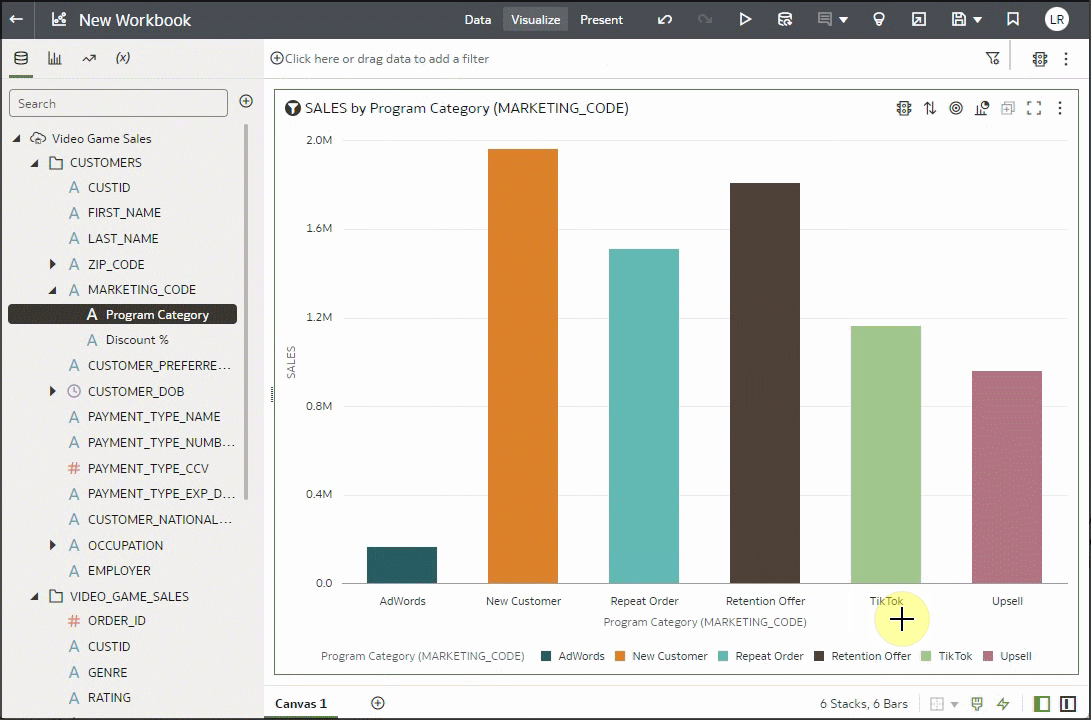
Notice how seamlessly the on-demand enrichments become part of your dataset to allow you to enrich and find deeper insights in the datasets. In some instances, you might want to control which datasets display these enrichments in workbooks. You can click a new flag in the Inspector dialog for each dataset. The enrichments are visible by default and you can turn them off by unchecking the box.
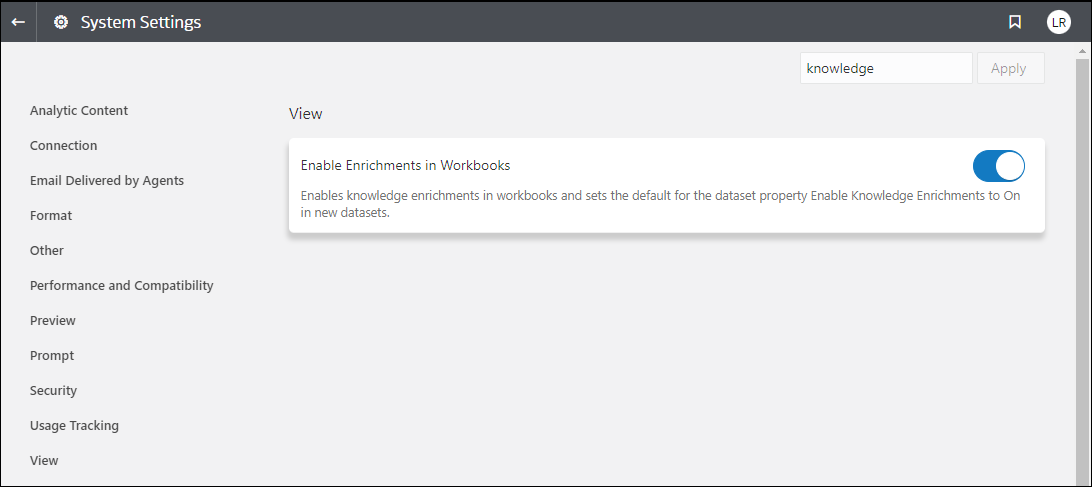
And finally, you can use a system flag to control the feature system-wide. You can turn on or off all enrichments in workbooks for all users for all datasets, regardless of their inspector flag settings.
Call to Action
We hope that you found this information useful and that you’ll experiment with enriching and standardizing your datasets with on-demand enrichments in workbooks. As you have learned from this example, using these enrichments in your visualizations or as filters makes your visualizations richer and more insightful. See documentation on quality insights. And make sure to stay tuned for additional articles with more tips and tricks!
