Overview
Oracle Analytics Cloud (OAC) data flows provide the ability to merge datasets in data preparation workflows. Combining data through a union presents several benefits including:
- Merging data from disparate data sources into a unified dataset
- Increasing dataset size by merging information from different time periods, geographical locations, product areas, and so on
- Reducing data duplication by eliminating repeated records
- Creating datasets with only common records among input datasets
This article focuses on the best practices for combining datasets with unions so that you can effectively use this feature. If you’re interested in learning about the different union types supported in OAC (Union All, Union, Intersect, among others) with several examples, visit this blog.
There are three general best practices to consider when combining data with unions from two source datasets:
- Ensure there’s a consistent number of columns among data sources. The data flow Union Rows step combines datasets by position and takes into consideration the overall structure of both datasets. You see an error message if your input datasets don’t contain the same number of columns.
- Pay attention to column order. As stated above, data flows are combined by position (that is, column 1 in dataset 1 is combined with column 1 in dataset 2, and so on), so it’s important to be aware of the location of each of the columns in the input datasets. There’s a column reordering feature to assist users in column arrangement. Data flows aren’t combined using column name similarity.
- Ensure data type consistency among corresponding columns. You see an error message if you attempt to combine datasets where the corresponding columns contain inconsistent data types.
The following description explains how you can implement these best practices using the tools in OAC.
1. Ensure there’s a consistent number of columns among data sources
There are a few methods to ensure that the input datasets you would like to combine contain the same number of columns. If you have read-write or full control access to the source datasets, open the dataset and look at the number of data elements (that is, number of columns) present in each table at the bottom of the screen. This approach is helpful if you’re working with datasets that contain many columns. If you’re working with smaller datasets, you can simply count the number of columns in the dataset Inspect panel, through the dataset preparation editor, or in the data flow itself.
2. Pay attention to column order
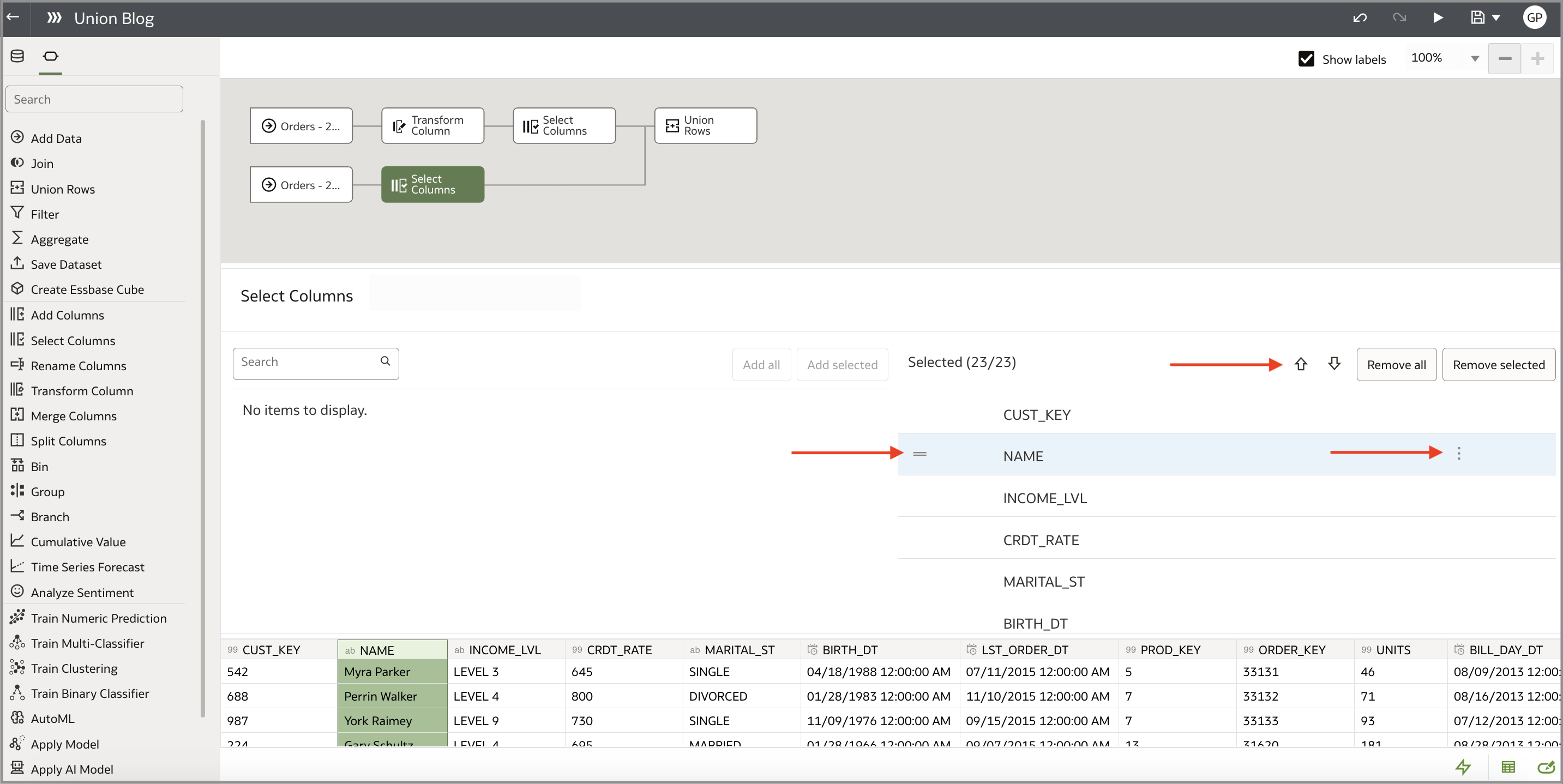
You can use the reordering feature in the ‘Select Columns’ step to easily modify the order in which the columns appear in each input dataset. There are three main ways to rearrange columns using the reordering feature:
- Select a column or group of adjacent columns and use the up/down arrows to move the column(s) left and right.
- Select a column or group of adjacent columns and use the horizontal lines icon to drag and drop to the desired position.
- Select the ellipsis icon to open the action menu and select either Move up or Move down to move the column left or right. This only works with an individual column, not a group of adjacent columns.
The arrows in the following image indicate the three locations where you can use the column reordering feature:
3. Ensure data type consistency among corresponding columns
There are a few ways that you can check the column data types and several methods to change the data types.
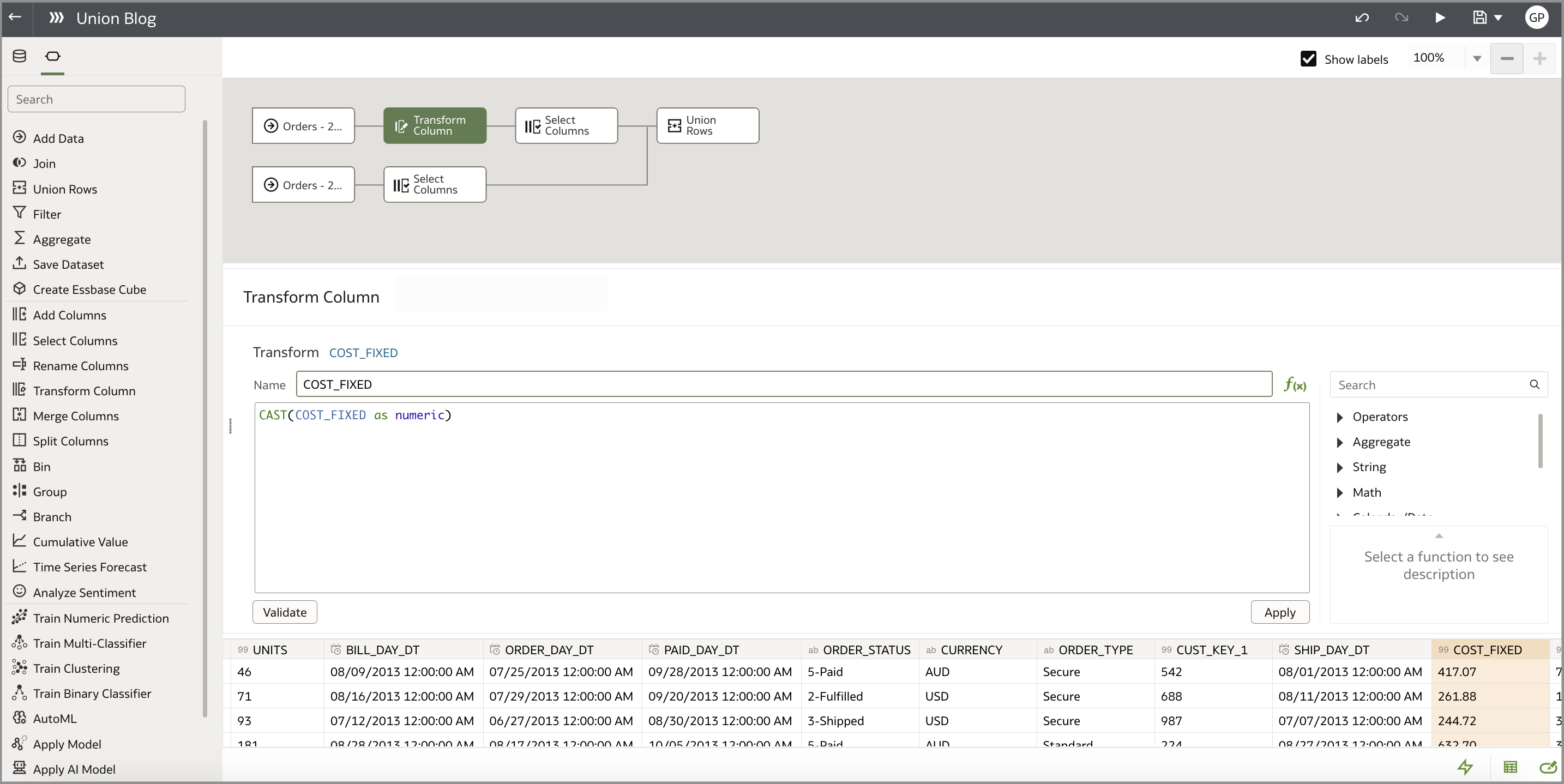
1. Verify and optionally change the column data types in the data preparation editor. To change the data types in the source dataset itself, you need read-write permissions at a minimum. Open the dataset and click the column of interest. On the left-hand side, you see a panel with some information related to the column, including data type. To change the data type, click the ellipsis next to the column name and select Convert to <data type>.
2. Verify and optionally change the column data types in the data flow. This won’t change the column type in the original dataset, only in the data flow. (This is the recommended approach if you don’t have read-write access to the source dataset, or if you don’t want to modify the dataset). You can change the data type of a column through the Transform Column step in a data flow. The following image shows converting the COST_FIXED column from a data type of text to a number data type using the Cast() function. Visit this blog if you’re attempting to convert a text column to a date-time column.
Call to action
Now that you know more about best practices, you can try some of these suggestions in your data preparation workflows when combining datasets. For more data flow-related blogs, visit my Oracle Analytics blog profile, and you can also ask questions about this and many other topics on the Oracle Analytics Community site.
