This blog is part of a series of best practice blogs for Oracle Analytics.
When Oracle Analytics uses a multi-dimensional database as a data source, there are additional design considerations that may have a big impact on performance.
It’s important to understand that performance improvement design solutions vary depending on the use case. This blog won’t provide you with best practices or a one-size-fits-all solution that should always be applied. Instead, we’ll offer you tuning methods and techniques to help you boost the performance of your analyses and generated code.
It’s up to the development team to review the options, analyze the Oracle Analytics query logs, and select the best solution for the use case.
This blog doesn’t address performance issues caused by your infrastructure, such as networks, browsers, or report presentation.
Methodology
We recommend you complete the following tasks to increase performance. As a pre-requisite to these tasks, it’s important to understand multidimensional expression (MDX) query structure as well as the generated BI Server query logs. The main tasks are:
- Simplify the MDX generated.
- Reduce the number of MDX queries generated.
- Ensure that optimal filters and selections are applied in the MDX.
- Performance tune with the DBA on the multi-dimensional database side and verify why the source database is still performing poorly.
- Modify the analysis based on DBA feedback.
Simplify the MDX generated / Reduce the number of MDX queries generated.
Selection Steps Optimization
When you optimize Oracle Analytics Cloud Classic, the selection step(s) defined can simplify the MDX queries, reduces the number of MDX queries generated, and increase performance.
Example
| Optimized |
|
Selection steps are optimized to include all members and the keep only the relevant member. |
| Not optimized |
|
Selection step is poorly defined and complex MDX is generated. |

Case Statements
Case statement functionality isn’t supported in MDX and must always be applied on the BI Server. The logic explained below with regards to Case statements is valid for most functions that aren’t supported in MDX (if null, etc.).
There are pros and cons when using Case statements:
- The main benefit of using a Case statement in report formulas is that it can’t be included in the MDX and may help to simplify the generated MDX query and improve performance.
- The main drawback for using a Case statement in reports formulas is that it can’t be included in the MDX and may prevent from you from applying optimal filters in MDX queries, resulting in more records being returned for processing.
As you can see, each use case is unique. The key objective is to simplify the MDX queries and at same time apply optimal filters and selections.
There are restrictions for using Case statement functionality :
- If the Case statement doesn’t combine multiple members, the base column used in the statement should be included in the query and the views as a hidden separate column.
- If the Case statement combines multiple members, the base column can’t be included in the view without impacting the level of aggregation. If this is the case:
- If the aggregation rule of measure is not External Aggregation, the base column shouldn’t in the query.
- If the aggregation rule of measure is External Aggregation, the base column must be included in the query and excluded from the view. You must change the Aggregation rule of measure from the default into a simple internal aggregation rule (SUM, MAX, MIN). This works only if the internal aggregation rule is used to combine members and provides correct results.
Filter Function
Unlike the Case statement, the FILTER function can be shipped to the database for execution.
- The main benefit of using the FILTER function in report formulas is that the selection is applied in the MDX query and the volume of data calculated and retrieved from the database is reduced.
- The main drawback of using the FILTER function is that it may increase the number of MDX queries executed. By default, one query is executed for each FILTER function used.
Remember, each use case is unique. The objective is to simplify MDX queries and at same time apply optimal filters and selections.
Scenario:
Let’s continue looking at the same scenario with the results of using the Case versus Filter functionality.
The user requests a report that shows profit by quarter and selected product SKU. In addition, the SKUs are grouped together into 12 categories. The category “Other Cola” has the following LOB’s products assigned: Cola, Diet Cola, and Shared Diet Cola.
Case Statement Scenario

Case Statement Logical Query
SELECT
0 s_0,
case when XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” in (‘Cola’,’Diet Cola’,’Shared Diet Cola’) THEN ‘Other Cola’ ELSE XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” END s_1,
DESCRIPTOR_IDOF(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Category”) s_2,
DESCRIPTOR_IDOF(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU”) s_3,
DESCRIPTOR_IDOF(XSA(‘Admin’.’Sample.BasicPM’).”Year”.”Quarter”) s_4,
SORTKEY(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Category”) s_5,
SORTKEY(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU”) s_6,
SORTKEY(XSA(‘Admin’.’Sample.BasicPM’).”Year”.”Quarter”) s_7,
XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Category” s_8,
XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” s_9,
XSA(‘Admin’.’Sample.BasicPM’).”Year”.”Quarter” s_10,
XSA(‘Admin’.’Sample.BasicPM’).”Basic”.”Profit” s_11
FROM XSA(‘Admin’.’Sample.BasicPM’)
ORDER BY 8 ASC NULLS LAST, 11 ASC NULLS LAST, 5 ASC NULLS LAST, 2 ASC NULLS LAST, 7 ASC NULLS LAST, 10 ASC NULLS LAST, 4 ASC NULLS LAST, 6 ASC NULLS LAST, 9 ASC NULLS LAST, 3 ASC NULLS LAST
FETCH FIRST 125001 ROWS ONLY
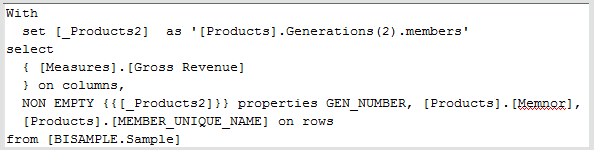
MDX Generated
With
set [_Product3] as ‘Descendants([Product], [Product].Generations(3), leaves)’
set [_Year2] as ‘Descendants([Year], [Year].Generations(2), leaves)’
select
{ [Measures].[Profit]
} on columns,
NON EMPTY {crossjoin({[_Year2]},{[_Product3]})} properties GEN_NUMBER, [Product].[MEMBER_UNIQUE_NAME], [Product].[Memnor], [Year].[MEMBER_UNIQUE_NAME], [Year].[Memnor] on rows
from [Sample.Basic]
Execution Plan:
The Case statement is executed on the BI Server, and this is seen by the database setting set to “database 0:0,0”.
RqList <<11777451>> [for database 0:0,0]
D1.c6 as c6 [for database 0:0,0],
D1.c4 as c4 [for database 0:0,0],
case when D1.c7 in ([ ‘Cola’, ‘Diet Cola’, ‘Shared Diet Cola’] ) then ‘Other Cola’ else D1.c7 end as c2 [for database 0:0,0],
D1.c5 as c5 [for database 0:0,0],
D1.c3 as c3 [for database 0:0,0],
D1.c1 as c1 [for database 0:0,0],
D1.c7 as c7 [for database 0:0,0],
D1.c8 as c8 [for database 0:0,0]
Filter Statement Scenario:
Alternatively, you can use a filter against the profit metric to retrieve only the required LOB members. In this scenario, you create 3 metrics with the corresponding filters applied.
Filter Statement Logical Query
SELECT
0 s_0,
DESCRIPTOR_IDOF(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Category”) s_1,
DESCRIPTOR_IDOF(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU”) s_2,
DESCRIPTOR_IDOF(XSA(‘Admin’.’Sample.BasicPM’).”Year”.”Quarter”) s_3,
SORTKEY(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Category”) s_4,
SORTKEY(XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU”) s_5,
SORTKEY(XSA(‘Admin’.’Sample.BasicPM’).”Year”.”Quarter”) s_6,
XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Category” s_7,
XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” s_8,
XSA(‘Admin’.’Sample.BasicPM’).”Year”.”Quarter” s_9,
FILTER(XSA(‘Admin’.’Sample.BasicPM’).”Basic”.”Profit” USING XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” in (‘Cola’,’Diet Cola’,’Shared Diet Cola’)) s_10,
FILTER(XSA(‘Admin’.’Sample.BasicPM’).”Basic”.”Profit” USING XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” in (‘Sasprilla’,’Birch Beer’,’Dark Cream’)) s_11,
FILTER(XSA(‘Admin’.’Sample.BasicPM’).”Basic”.”Profit” USING XSA(‘Admin’.’Sample.BasicPM’).”Product”.”Product SKU” in (‘xxxxx’)) s_12
FROM XSA(‘Admin’.’Sample.BasicPM’)
ORDER BY 7 ASC NULLS LAST, 10 ASC NULLS LAST, 4 ASC NULLS LAST, 6 ASC NULLS LAST, 9 ASC NULLS LAST, 3 ASC NULLS LAST, 5 ASC NULLS LAST, 8 ASC NULLS LAST, 2 ASC NULLS LAST
FETCH FIRST 125001 ROWS ONLY
MDX Generated (3 queries)
In this scenario, 3 queries, 1 for each filter is generated, and you experience performance issues.
Query 1
With
set [_Product3] as ‘Filter([Product].Generations(3).members, ((IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “xxxxx”)))’
set [_Year2] as ‘Descendants([Year], [Year].Generations(2), leaves)’
select
{ [Measures].[Profit]
} on columns,
NON EMPTY {crossjoin({[_Year2]},{[_Product3]})} properties MEMBER_NAME, GEN_NUMBER, property_expr([Product], [MEMBER_NAME], Ancestor(currentaxismember(), [Product].Generations(2)), “Category_Null_Alias_Replacement”), property_expr([Product], [Default], Ancestor(currentaxismember(), [Product].Generations(2)), “Category”), property_expr([Product], [MEMBER_UNIQUE_NAME], Ancestor(currentaxismember(), [Product].Generations(2)), “Category – Member Key”), property_expr([Product], [Memnor], Ancestor(currentaxismember(), [Product].Generations(2)), “Category – Memnor”), [Product].[MEMBER_UNIQUE_NAME], [Product].[Memnor], [Year].[MEMBER_UNIQUE_NAME], [Year].[Memnor] on rows
from [Sample.Basic]
]]
Query 2
With
set [_Product3] as ‘Filter([Product].Generations(3).members, ((IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “Birch Beer”) OR (IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “Dark Cream”) OR (IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “Sasprilla”)))’
set [_Year2] as ‘Descendants([Year], [Year].Generations(2), leaves)’
select
{ [Measures].[Profit]
} on columns,
NON EMPTY {crossjoin({[_Year2]},{[_Product3]})} properties MEMBER_NAME, GEN_NUMBER, property_expr([Product], [MEMBER_NAME], Ancestor(currentaxismember(), [Product].Generations(2)), “Category_Null_Alias_Replacement”), property_expr([Product], [Default], Ancestor(currentaxismember(), [Product].Generations(2)), “Category”), property_expr([Product], [MEMBER_UNIQUE_NAME], Ancestor(currentaxismember(), [Product].Generations(2)), “Category – Member Key”), property_expr([Product], [Memnor], Ancestor(currentaxismember(), [Product].Generations(2)), “Category – Memnor”), [Product].[MEMBER_UNIQUE_NAME], [Product].[Memnor], [Year].[MEMBER_UNIQUE_NAME], [Year].[Memnor] on rows
from [Sample.Basic]
]]
Query 3
With
set [_Product3] as ‘Filter([Product].Generations(3).members, ((IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “Cola”) OR (IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “Diet Cola”) OR (IIF(IsValid([Product].CurrentMember.MEMBER_ALIAS), [Product].CurrentMember.MEMBER_ALIAS, [Product].CurrentMember.MEMBER_Name) = “Shared Diet Cola”)))’
set [_Year2] as ‘Descendants([Year], [Year].Generations(2), leaves)’
select
{ [Measures].[Profit]
} on columns,
NON EMPTY {crossjoin({[_Year2]},{[_Product3]})} properties MEMBER_NAME, GEN_NUMBER, property_expr([Product], [MEMBER_NAME], Ancestor(currentaxismember(), [Product].Generations(2)), “Category_Null_Alias_Replacement”), property_expr([Product], [Default], Ancestor(currentaxismember(), [Product].Generations(2)), “Category”), property_expr([Product], [MEMBER_UNIQUE_NAME], Ancestor(currentaxismember(), [Product].Generations(2)), “Category – Member Key”), property_expr([Product], [Memnor], Ancestor(currentaxismember(), [Product].Generations(2)), “Category – Memnor”), [Product].[MEMBER_UNIQUE_NAME], [Product].[Memnor], [Year].[MEMBER_UNIQUE_NAME], [Year].[Memnor] on rows
from [Sample.Basic]
Product Filter Applied Scenario.
A better approach is to include the product column in the report with a single measure column without a filter. Then create a filter that includes the required products. If you want to group the products into different categories a case statement can be used. In this scenario there will be a single MDX query generated with the filtered rows and even though the case statement is applied on the BI server it will use the subset of data and not all records.
Let’s look at another scenario where Case statements cause performance issues.:
Scenario – Dashboard Prompt:
A developer applies a Case statement to rename brands, and a dashboard prompt allows users to select the brand:
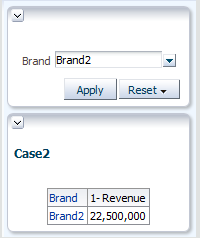

As the Case statement is not supported in MDX, the filter on ‘Brand2’ can’t be applied in the MDX query. All brands are selected, and this is not optimized.
In this scenario, we recommend you remove the Case statement and rename members in the database or create aliases.
Summary
When you use a multi-dimensional database as a data source, you may experience Oracle Analytics performance issues which result in sub-optimal MDX generated queries. By modifying the design, you can improve the MDX queries that Oracle Analytics generates. This can have a huge impact, not only on your report performance but also on the volume of resources used in the database. Be careful of how you utilize supported or non-supported functions in MDX, as this greatly impacts the MDX queries generated and performance. For more information, check the Oracle Analytics Cloud documentation in the Oracle Help Center.