This is part of a series of best practice blogs for Oracle Analytics.
Beginning with the September 2022 Update for Oracle Analytics Cloud (OAC), you can import data from Google Big Query sources and model the data in the repository file (.rpd). This article provides best practices for using this data source.
Prerequisites
You must have the following:
- The September 2022 or later Update for OAC.
- Version 6.5 or later of the Model Administration tool. Best practice is to use the latest version of the OAC Client Tools.
Step 1: Set up the connection in OAC
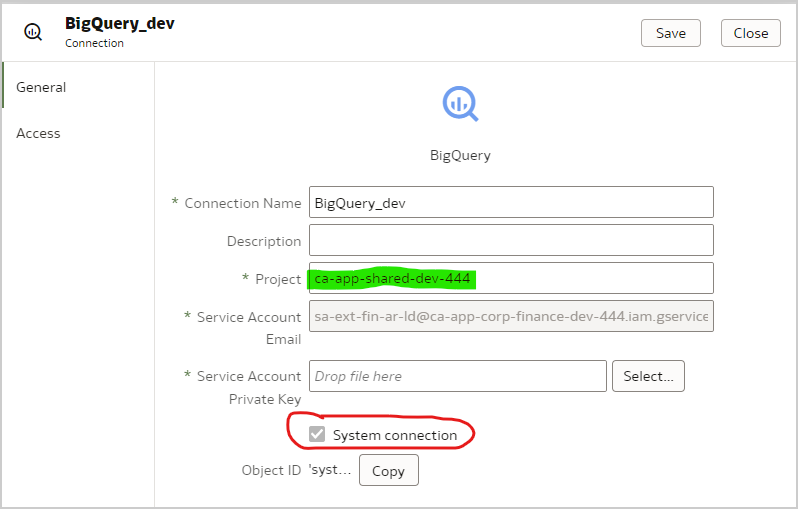
- Create a Big Query connection in OAC:
- Check System connection. The System connection box is checked only when the connection is created. If the box isn’t checked, then you can’t use the connection in the repository file. Create a connection with System connection checked.
- The Service Account Email field is populated when the Service Account Private Key is uploaded.
- A Big Query Project is synonymous with a Big Query Workbook. In the connection dialog, ensure that the project name is all lowercase.
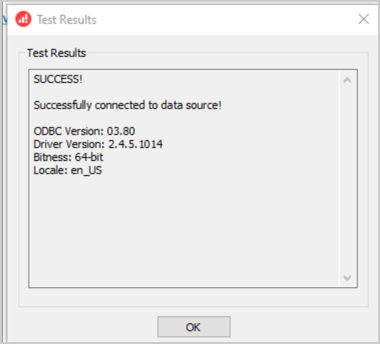
Step 2: Set up ODBC
- Install, create, and test the Big Query ODBC driver on the machine where the Oracle Analytics Client Tools are installed. Download the Simba Big Query ODBC driver at https://cloud.google.com/bigquery/docs/reference/odbc-jdbc-drivers.

Step 3: Set up the repository file (.rpd)
The following steps depend on the permissions in the Big Query key.
If the Big Query key grants access to the dataset level, simply perform Import Metadata using the Big Query ODBC driver by following the steps below.
If the Big Query key grants access to only specific tables or views, follow the steps below to create a physical schema.
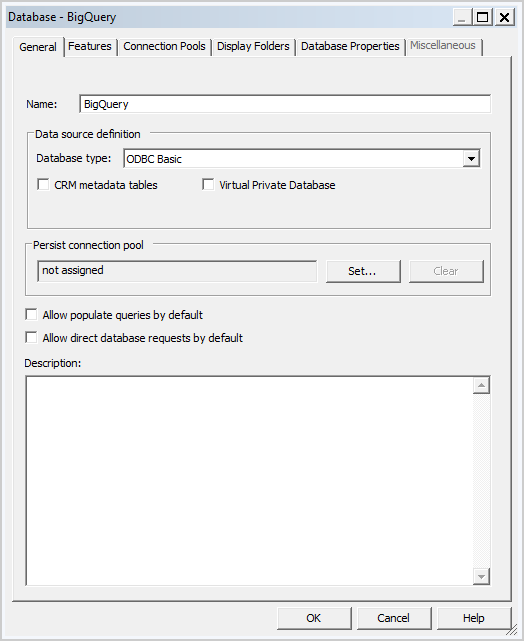
- Create a database in the repository file.
- Set the database type to ODBC Basic.
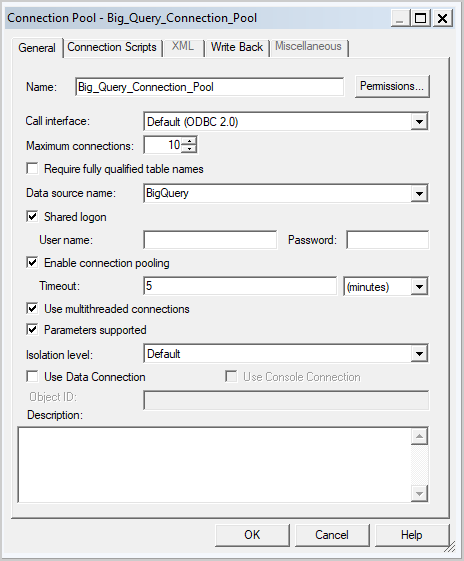
- Create a connection pool in the database:
- Leave the call interface set to Default (ODBC 2.0).
- In the Data source name field, select the Big Query ODBC driver that was created earlier.
- Create a physical schema in the database using the same name as the Big Query dataset.
- Big Query SQL requires that the dataset name prepend the table name, dataset.table. The dataset name is equivalent to a physical schema object in the repository file.
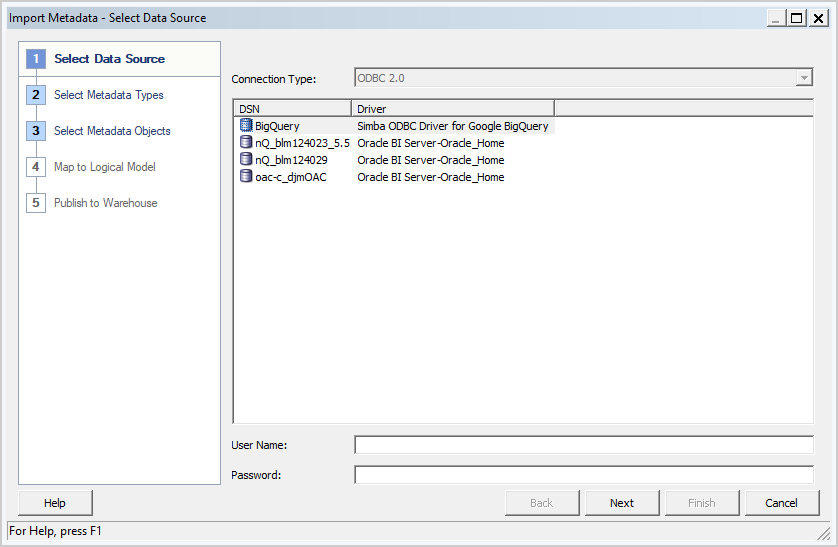
- Right-click the connection pool and select Import Metadata.
- On the Select Data Source screen, select either ODBC 2.0 or ODBC 3.5 for the connection type. Select the Big Query ODBC driver.
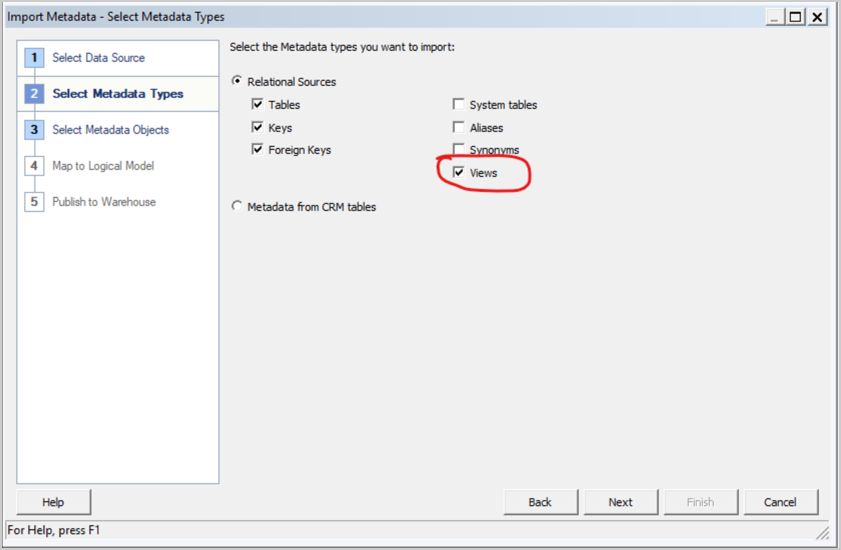
- In this case, the Big Query key has permissions only on views. Select Views on the Select Metadata Types screen.
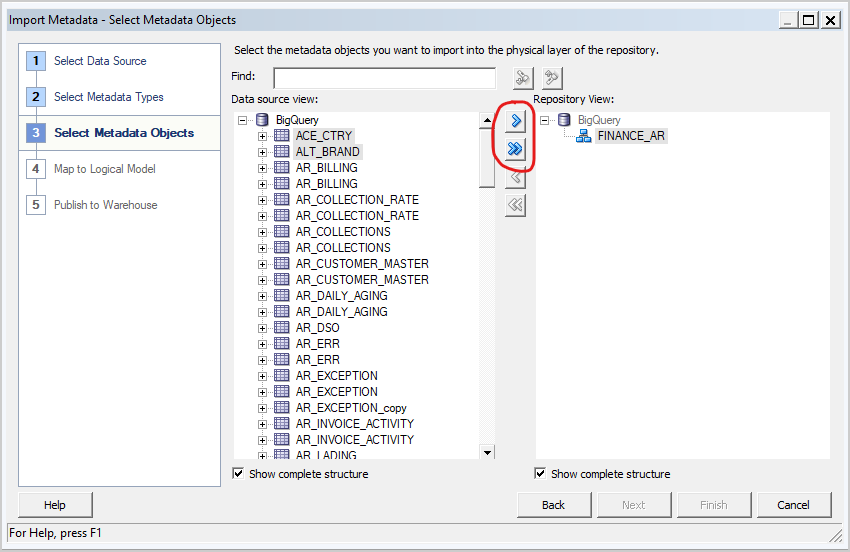
- On the Select Metadata Objects screen, select the individual tables and then click Import Selected. This imports the Big Query database and the underlying structures.
If you click Import All, you import only the database. If this happens, select Import All a second time to import the tables.
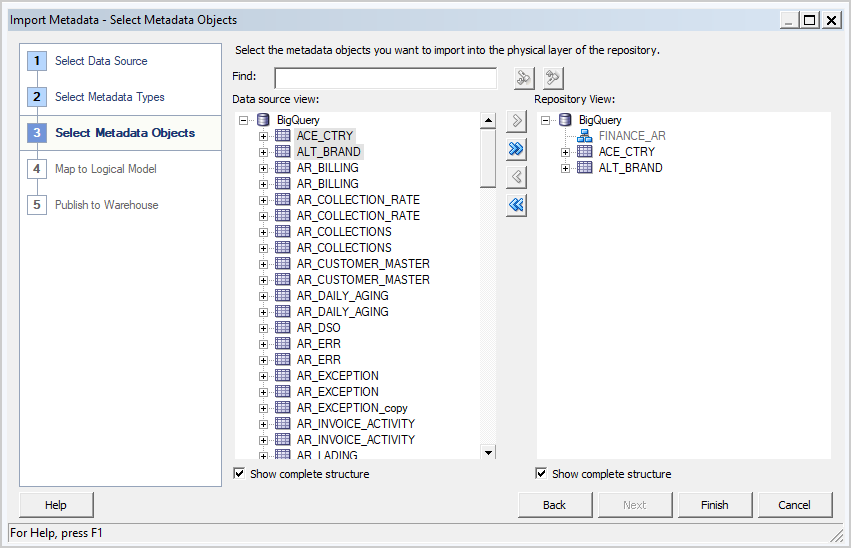
- Click Finish.
- Drag imported tables into physical schema.
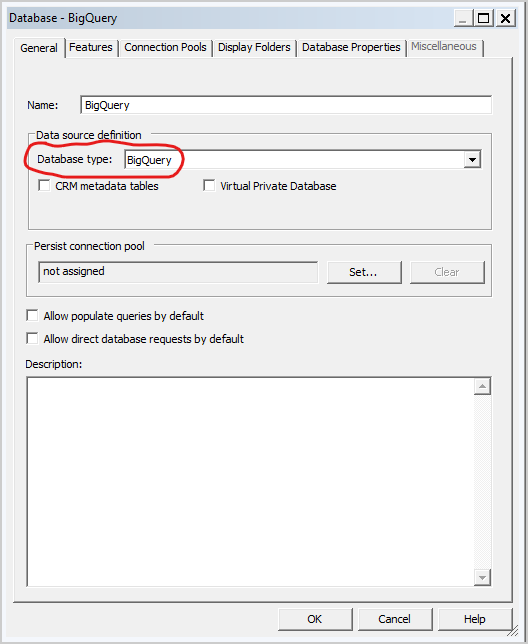
- Edit the physical database and change the database type to BigQuery.
- When changing the physical database, you see a message that states that the database type doesn’t match the call interface set in the connection pool. Edit the connection pool in the next step.
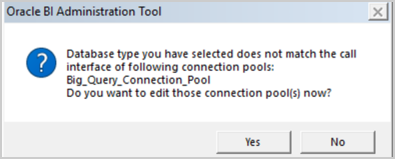
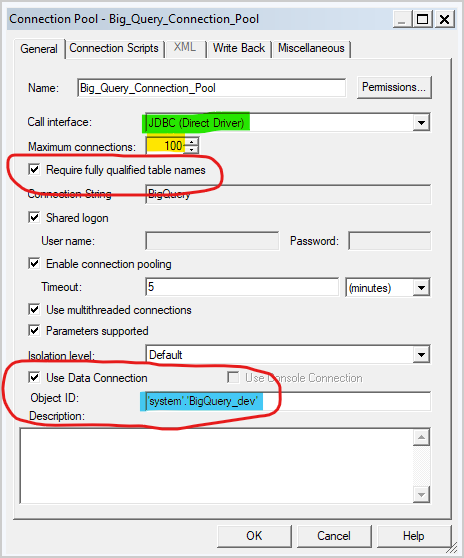
- Edit the connection pool:
- Change the call interface to JDBC (Direct Driver).
- Select Require fully qualified table names.
- Check Use Data Connection.
- In OAC, inspect the Big Query connection and copy the Object ID. Big Query is case-sensitive. To ensure that the data connection syntax is correct, use the Copy button.
- Paste the OAC Object ID into the Object ID box in the connection pool.
- Set Maximum connections to 100.

- Finish modeling in the repository file and upload it to OAC.
Troubleshooting
- If Require fully qualified table names isn’t selected and a physical schema isn’t part of the generated SQL, then queries fail with a vague message similar to Failed to read data from Java Datasource server.
If the query is run against Big Query using nqcmd or another SQL entry tool, the actual error message is displayed:
WITH SAWITH0 AS (select distinct T4.PROP_CD as c1 from FINOPS_RM_OCC_ACT T4) select 0 as c1, D1.c1 as c2 from SAWITH0 D1 order by c2
[Simba][BigQuery] (70) Invalid query: Table “FINOPS_RM_OCC_ACT” must be qualified with a dataset (e.g. dataset.table).
Statement preparation failed
The way to qualify the query with a dataset is to use a physical schema in the repository file.
- If the OAC connection uses an uppercase project name, the connection is created successfully.
You might see two different problems.
-
- Queries fail with a 404 Not Found message about a masked URL:
[2022-03-17T01:13:44.105+00:00] [OBIS] [TRACE:2] [USER-34] [] [ecid: d6382db0-1e63-427e-893b-18bc00c0424e-0000de96,0:2:1:5] [sik: bootstrap] [tid: 856a6700] [messageId: USER-34] [requestid: 6358001e] [sessionid: 63580000] [username: Testuser] ——————– Query Status: [nQSError: 46164] HTTP Server returned 404 (Not Found) for URL [masked_url]. [[
[nQSError: 46281] Failed to download metadata for dataset ‘system’.‘Big Query Test’.
[nQSError: 43119] Query Failed:
-
- Within OAC, you see datasets but the underlying tables aren’t available:
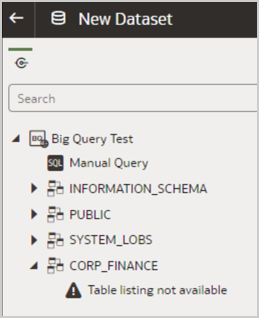
In both cases, you can modify the connection so that the project name is lowercase.
- When troubleshooting Big Query connections in OAC, use a third-party JDBC client to try to connect to Big Query using the same Service Account Key.
If the connection still fails, there is a problem with the Service Account Key.
If the connection is successful, there is a problem with OAC and a service request should be opened.
This test is helpful in cases where a .rpd is not used to connect to Big Query and the Service Account Key is not verified through ODBC.
Conclusion
Setting up Big Query isn’t as straightforward as other data sources. Hopefully this article makes the setup a bit easier.
For more information about setting up a repository file (.rpd), see https://docs.oracle.com/en/middleware/bi/analytics-server/metadata-oas/index.html.
For more information about setting up connections in OAC, see https://docs.oracle.com/en/cloud/paas/analytics-cloud/acsds/index.html.