Introduction
In previous blogs, I described how I used a JDBC driver to query my Oracle Analytics Cloud (OAC) semantic model from an Oracle Cloud Infrastructure (OCI) data science notebook. This ultimately enables data scientists to use the semantic model as a verified metrics store to retrieve accurate business information to use for data science-related tasks such as predictive modeling, forecasting, collaborative filtering, etc. In case you missed these posts, here are the links:
-
How to use your OAC Semantic Model as a verified metrics store to enhance data science objectives
-
Query your OAC semantic model from an OCI Data Science environment
After establishing a connection to OAC via a JDBC driver from a data science environment, you’ll find that the capabilities aren’t limited to querying data. It’s possible to use the JDBC connection to execute ODBC-extension functions for purging the cache. This begs the following questions: why would you need to purge the cache in the first place, and why should you use Python?
Why do you need to purge the cache?
Caching data offers several advantages. Leveraging cached data in the context of a semantic model greatly reduces the load on both data source systems and the BI Server, especially when dealing with a large amount of data. In many cases, caching alleviates the need for the BI Server to retrieve large amounts of data in real-time from databases by relying on queries that have previously been executed. That being said, you must manage the cache properly to ensure that it reflects the most up-to-date information in the backend system; you don’t want to distribute reports using stale cached data.
Be sure to have a cache management system in place. Cache management varies based on the situation and the company. Sometimes a full purge of the cache is required, and sometimes it might be more beneficial to purge by specific queries or physical tables. Seek out resources that help you identify which purge option is most appropriate for your situation.
Why use Python?
Using a Python programming approach for clearing the cache offers many benefits. In this blog post, I discuss the functions that allow you to purge the cache based on the query or a table, and purging the entire cache. These functions ultimately allow a high level of control in determining the grain of cache purging. In addition, you can include these functions in a Python script that runs on a schedule or on manual execution to allow for a greater level of control over when the cache is purged.
Getting started: Purge the cache from OCI Data Science
This section describes how to purge the cache for the semantic model using Python from OCI Data Science. The rest of this blog post assumes that you’re following the code I use in this blog to connect to your OAC semantic model from OCI Data Science (the subsequent code snippets require the use of variables defined in the blog post).
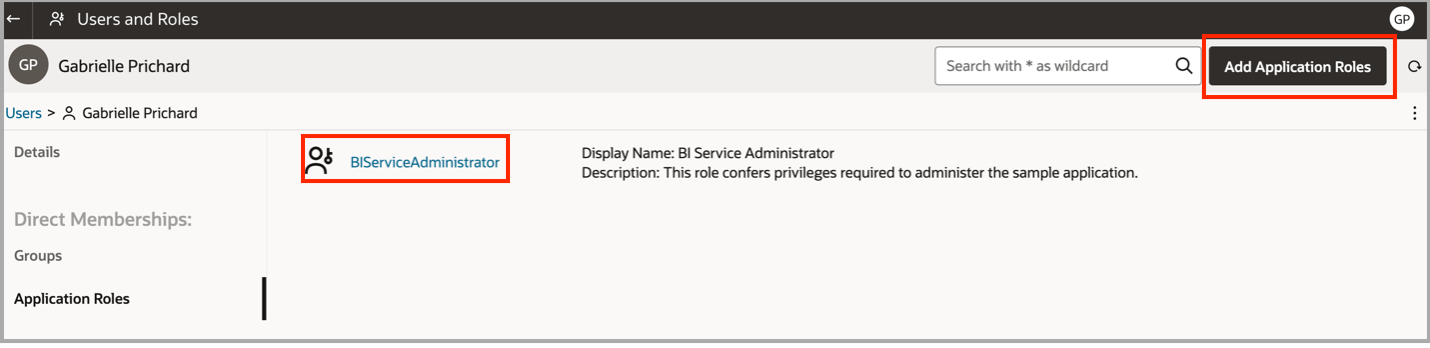
In the blog post, I mention that you must set up a confidential application configured with JWT assertion or resource owner assertion. Regardless of which assertion type you choose, the IDCS user you use for the assertion must also have a BIServiceAdministrator role in the OAC instance that you’re connecting to. The reason for this is that only administrators can purge the cache. Navigate to the Console in your OAC instance and select Users and Roles.
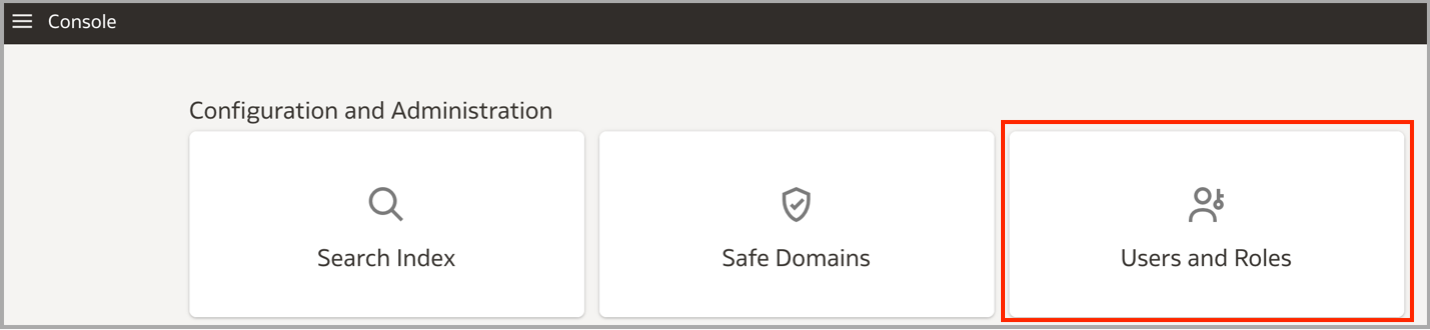
Search for and select the IDCS user and click the Application Roles tab. Ensure that the user has the application role BIServiceAdministrator. If they don’t, select Add Application Roles and add the role.
Navigate back to OCI Data Science. Once you’ve used the jaydebeapi .connect method to establish a connection to the semantic model in Oracle Analytics Cloud and have used the connection to obtain a cursor, you can move forward. The next step is to determine how you want to purge the cache. This blog contains a section called “Purging Options” that’s helpful in determining which purging option is best for you. I’ll show you the functions for purging cache by query, purging cache by table, and purging the whole cache.
Purge the cache by query
There are a few reasons why you might want to purge the cache by query. You might not want to purge an entire table that contains a large amount of data; you might want to update only certain columns within the cache, etc. The ODBC function to purge the cache by query is SAPurgeCacheByQuery(‘<logical sql>’) where the parameter is the logical SQL statement for the query that you want to purge.
Create a text file in your data science environment called cache.txt. Paste the following into the text file:
Call SAPurgeCacheByQuery(‘<logical sql>’);
See the following for an example:

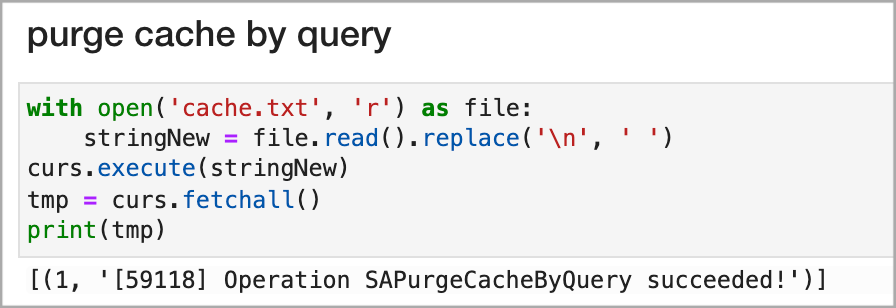
In a new notebook cell, paste the following code:
with open(‘cache.txt’,’r’) as file:
stringNew=file.read().replace(‘\n’,”)
curs.execute(stringNew)
tmp=curs.fetchall()
print(tmp)
After running the cell, you should see a success message displayed as shown in this example:
Purge the cache by table
Consider purging the cache by table if you have one table that changes frequently while the other tables do not. The function to purge the cache based on the physical table is SAPurgeCacheByTable(‘<DBName>’, ‘<CatName>’, ‘<SchName>’, ‘<TabName>’) where the parameters are individual components of a fully qualified table name (database name, catalog name, schema name, and table name). You can find the fully qualified table name by going to the physical layer of the repository (RPD). If there’s no catalog name, substitute the parameter with a set of empty single quotation marks (see the example below).
Create a text file in your data science environment called cache-table.txt. Paste the following into the text file:
Call SAPurgeCacheByTable(‘<DBName>’, ‘<CatName>’, ‘<SchName>’, ‘<TabName>’);
See the following example:
![]()
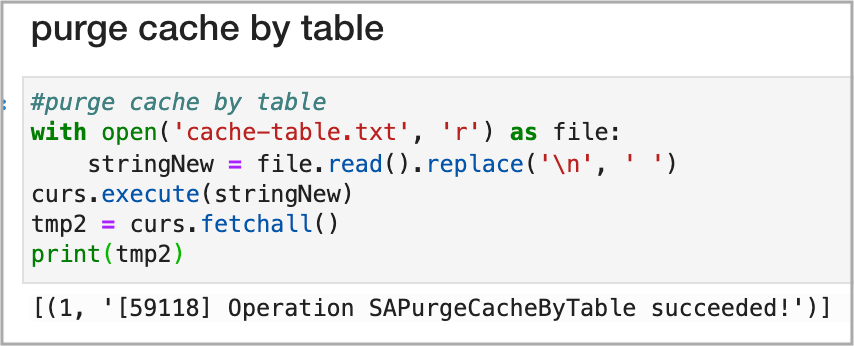
In a new notebook cell, paste the following code:
with open(‘cache-table.txt’,’r’) as file:
stringNew = file.read().replace(‘\n’, ”)
curs.execute(stringNew)
tmp2 = curs.fetchall()
print(tmp2)
After running the cell you should see a success message displayed as shown in this example:
Purge the whole cache
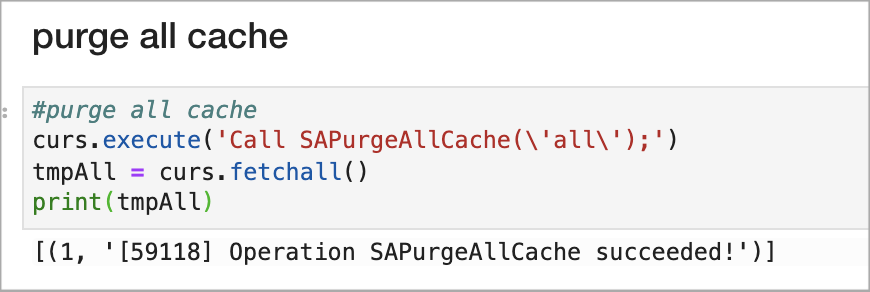
You might want to purge the whole cache if you’re dealing with a small amount of data that updates frequently. This purge option is the simplest to implement. The function to purge all cache is SAPurgeAllCache(‘all’). To purge all cache entries, run this code in a new notebook cell:
curs.execute(‘Call SAPurgeAllCache(\’all\’);’)
tmpAll = curs.fetchall()
print(tmpAll)
Summary and Call to Action
This blog post covered the importance of purging tge cache and discussed the benefits of doing this in Python. Ultimately, you must consider your business requirements when determining which purge option is right for you. If you can establish a connection to the semantic model in OAC from a data science environment, I encourage you to explore other methods of interaction with OAC. Visit this link to learn more about Oracle Analytics and find the documentation on Oracle Help Center.
