Oracle Analytics Cloud (OAC) is tightly integrated with the Oracle Database’s machine learning capabilities, bringing the full power of the underlying Oracle Machine Learning (OML) models to business analysts using OAC. With this integration, you are able to register OML models from the database within OAC and use it to score your own datasets and predict outcomes. As part of this scoring process, the OML model returns the prediction with the highest probability as the default output. But there are additional, interesting outputs that can be leveraged as part of the scoring process. These additional outputs fall into two categories:
1. Prediction Set – This refers to multiple prediction outcomes and is applicable to Classification and Clustering model types. With Prediction Set, for every input record, in addition to the prediction with the highest probability, you can also see additional prediction outputs and their probabilities.
2. Prediction Details – This refers to the set of columns that helps explain the model and is applicable to all model types. With Prediction Details, for every input record, you get details on the different attribute columns that contributed to arrive at a prediction or outcome. These details include the attribute name, attribute condition, weightage, and so on.
This blog covers the first category of output, the prediction set. Prediction Details will be covered in another post.
Before delving into the specifics, it’s important to understand the process of registering an OML model in OAC and using it to score a dataset.
1. How to register a model
As an admin user, open the Register Model/Function menu and choose Machine Learning Models.
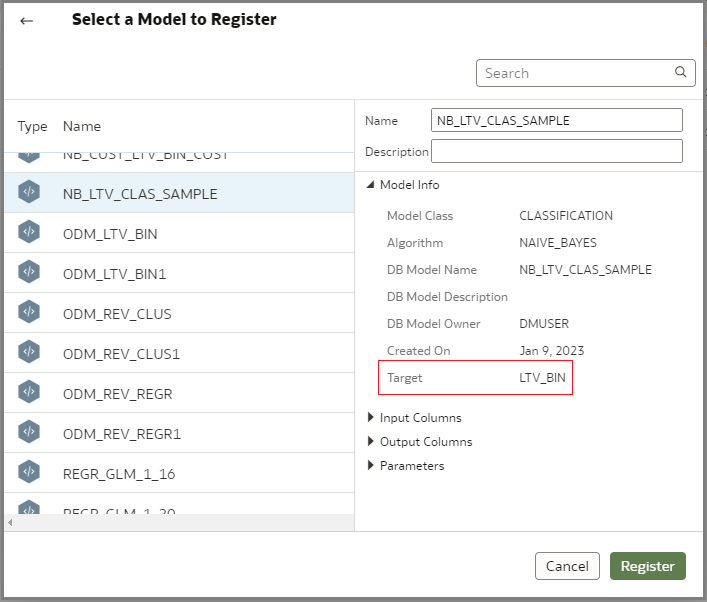
From the list of available connections, select an Oracle Database or Oracle Autonomous Data Warehouse (ADW) connection. Once you select a connection, you see the list of models accessible to you for that connection. Select a model of interest by looking at the model details on the right pane and register it. In this example, select a classification model called NB_LTV_CLAS_SAMPLE that predicts the LTV_BIN (Life Time Value) class of customer with possible values being VERY HIGH, HIGH, MEDIUM and LOW. Select this model and register it.
2. Apply the model
Once the model is registered in OAC, it is available for scoring your own datasets via dataflows. Consider a customer dataset and try to apply this OML model to predict the LTV value of each customer. To do that, first create a dataflow and add the customer dataset. Next, you’ll add the ‘Apply Model’ step.
To apply an OML model, it is mandatory to have the input dataset sourced from the same database as the registered OML model and using the same OAC connection. Only if this condition is met will you be able to see the model in the list.
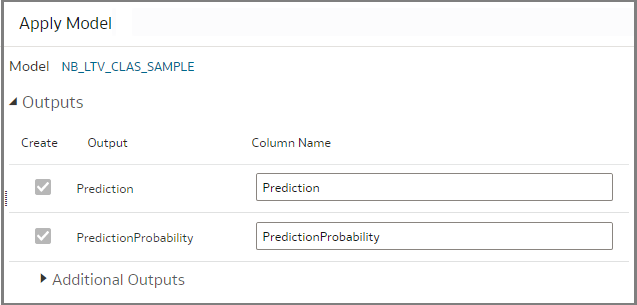
Select the model that you just registered. Once you’ve added the model, you can see the Output Section where by default there are the Prediction and Prediction Probability columns.
Use these defaults, add a Save Data step, and run the dataflow. You can see in the output dataset, for each customer record, there is a prediction of the customer LTV value and the probability of that prediction. By default, you only see the prediction with the highest probability for each record. Here’s a sample output.
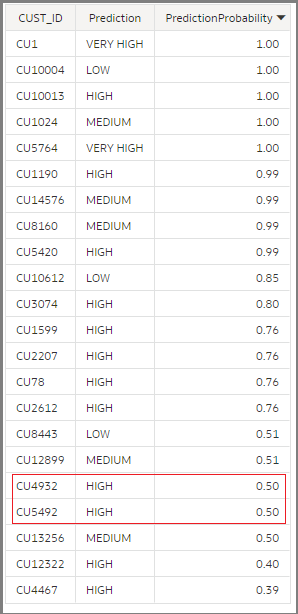
Here, for example, the model predicts that customer CU1 is likely to have ‘VERY HIGH’ as the LTV value and probability of this prediction is 1 (or 100%) , CU10004 is predicted to be ‘LOW’ LTV value again with a 100% probability. If you look further down, there are customers like CU4932 and CU5492 who are predicted to be of ‘HIGH’ value but the probability of this prediction is only 0.50 (or 50%). This is not a very strong prediction. In such cases, you’d want to see the probability of this customer belonging to a different category. This is where prediction set or multiple prediction outcomes for each input record could help.
3. Add additional prediction columns (prediction set)
To start, go back to your dataflow and look at the Apply Model step. Notice the Addition Outputs section within Outputs, collapsed by default.
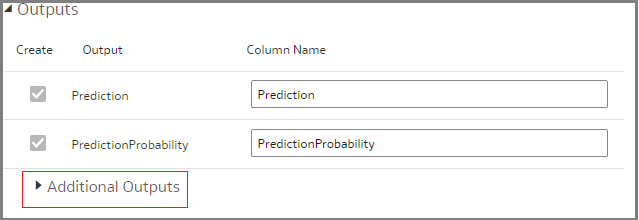
As you expand this, you see several additional columns available, which are of interest. There are two sets of columns here:
Prediction set, which includes columns Prediction_2, Probability_2, Prediction_3, Probability_3, Prediction_4 and Probability_4.
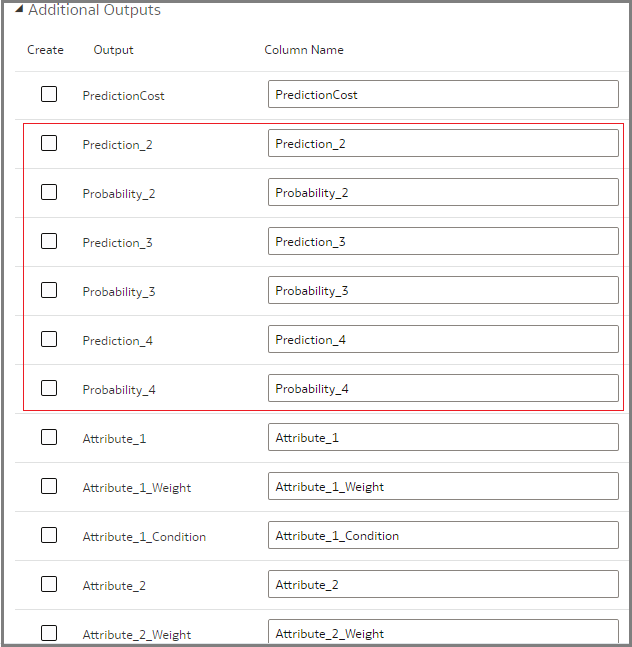
The remaining columns pertain to Prediction Details.
Select the prediction set of columns, which includes Prediction_2,3,4 and their probabilities, and rerun the dataflow. The output dataset will look as shown below.
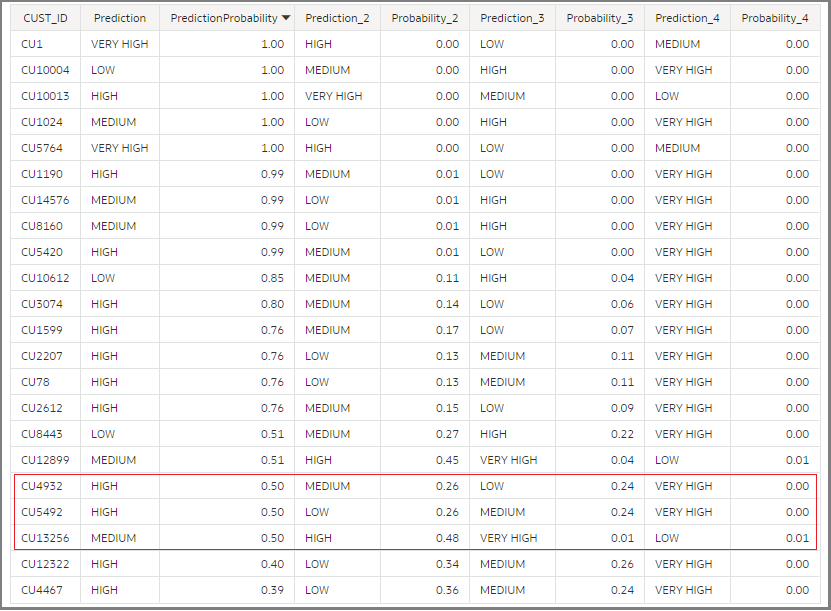
For each input record, or customer ID in this case, you can see the default Prediction column which is the prediction with the highest probability. You also see the next 3 possible predictions by the model. For CU1, the model predicted it to be VERY HIGH with a 100% probability, so the probability of the other predictions for this customer is 0%. But if you scroll down and see for instance CU4932 and CU5492, the model predicted them to be of HIGH value but only with a probability of 50%. It predicts these customers could also be MEDIUM or LOW with around 25% probability.
Now look at the customer CU13256. The model predicts this to be a MEDIUM value customer with 50% probability but a HIGH value customer with 48% probability. So this customer has two possible outcome predictions with almost equal probability. This could be business value to you – for example, if you were planning a marketing campaign targeted at customers who are predicted to be HIGH value, with a probability of >45%. If you were only looking at the default set of predictions, CU13256 would not have made the list as it would have only one prediction which would be MEDIUM. This could possibly be a miss. If you take prediction_2 as well into consideration and apply your selection criteria across prediction and prediction_2 outputs, then CU13256 will also land on the list, which could be beneficial to your campaign.
Multiple predictions (up to 4) are available by default for all Classification models in the Apply model step. In case of a binary classification model with just two possible outcomes, you would still see 4 prediction columns, but only Prediction (highest probability) and Prediction_2 (the other possible prediction) would have values. In cases of a multi-classification model, you will see up to 4 possible predictions for each input record.
Under the covers, the Oracle Database uses a PREDICTION_SET clause to retrieve these multiple predictions and their probabilities. In the Database, th PREDICTION_SET clause returns multiple predictions as different rows for each input record, thereby changing the grain of the dataset. OAC also uses the PREDICTION_SET clause, and then pivots the rows as columns to make the output dataset more analysis-friendly.
In conclusion, with OML integration, you can quickly score datasets and look at the model predictions and probability that will help you perform predictive analytics. Prediction set or multiple predictions can be leveraged to further advance predictive analytics. This will allow you to determine a target cohort that will include the right population for different business purposes.
Watch out for another blog describing Prediction Details, the second set of columns that explains models and further enriches your predictive analytics.
For more information, please see the documentation. If you have questions, please post them in the Analytics forum on Cloud Customer Connect and we’ll be happy to answer!
