In 2022, 4,111 heart transplants were performed in the US, averaging 29 transplants in 144 centers. More than 3,500 people wait for a new heart with 1 in 12 deaths. Every transplant is priceless, yet the promise is sacrificed with delayed recovery times, suboptimal matches, inadequate patient data, and transport logistics. The Organ Procurement and Transplantation Network (OPTN) is a public-private partnership that links all professionals, individuals, and volunteers who support the US donation and transplantation system. OPTN membership constitutes transplant centers, organ procurement organizations (OPOs), histocompatibility laboratories, public organizations, medical scientific members, and business and individual members. The United Network for Organ Sharing (UNOS) was awarded the initial OPTN contract on September 30, 1986 and continues to administer the OPTN today.
The OPTN calls for an integrated real-time, dynamic system with the following capabilities and features:
-
Extracts donor and recipient data from electronic health recovery (EHR) provider systems, such as EPIC and Cerner, and other patient-provider registries
-
Standardizes donor and recipient data to form a complete patient longitudinal record
-
Deidentifies the donor and recipient patient data
-
Algorithmic organ data matching, considering only medical and logistical criteria
-
Ensure timely and accurate organ delivery and monitoring
-
Real-time geolocation, rerouting, and organ matching based on organ viability
-
Historical data analytics capabilities for organizations and partners
Achieving all these goals requires a modern healthcare industry-compliant data platform to fulfill and scale these tasks efficiently and effectively.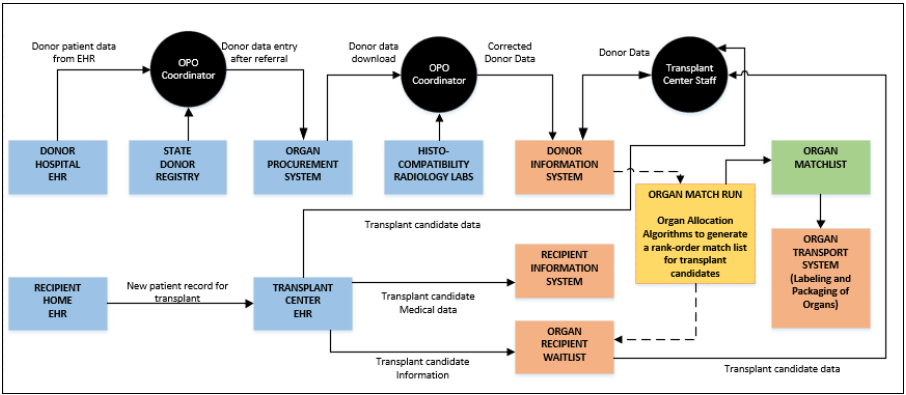
OCI architecture
The following diagram shows the architecture and key components of Oracle Cloud Infrastructure (OCI)’s solution to these issues:
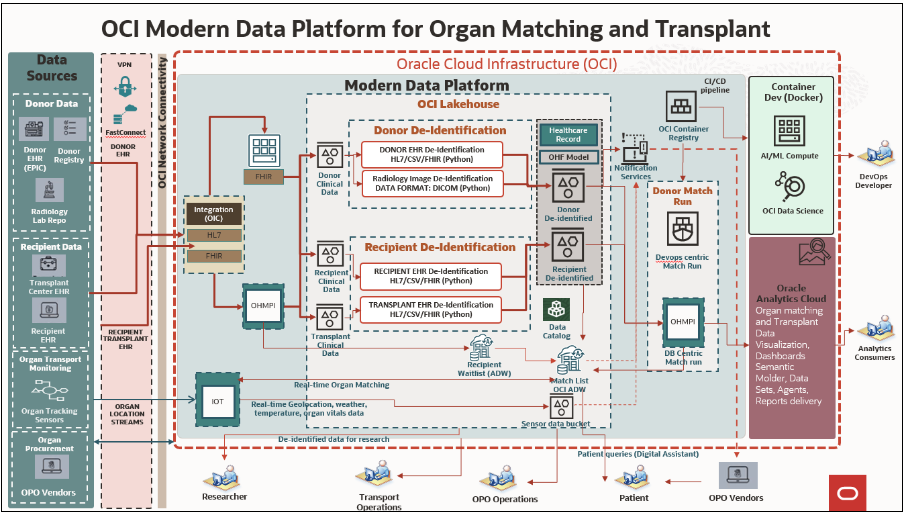
Key components
Data acquisition
The correct identification of data sources provides the foundation block for data acquisition, consisting of the following parts:
-
Donor and transplant candidate patient EHR data. The data is usually distributed across multiple providers, EHR systems, and donor registries. OPO donor registries provides the required filtration to pull EHR data for donors only.
-
Transplant candidate or recipient data also follows the same process, but recipient-specific registries might not be maintained.
-
Radiology data sources provides annotated images related to the donor
-
Organ tracking sensors provides real-time streaming geolocation and organ vitality during transport.
This process uses the following data platform features:
-
Encrypted and secured ingestion of data
-
Industry standard complaint data formats, such as HL7 and FHIR
-
Industry standard acquisition protocols, such REST and MQTT
-
Industry standard tools, such as Oracle Integration Cloud (OIC), Oracle streaming, and Oracle internet of things (IOT)
EHR data standardization
Data standardization transforms EHR input data into common representations with a single, consistent view of the patient longitudinal record from data stored across disparate systems. Data standardization has the following key elements:
-
Accurately compare data between systems
-
Parsing individual data elements to a common format
-
Data cleansing
-
Normalization (converting nicknames and short names to standardized names)
-
Data typing standardized into a common data type
-
Phonetic encoding, such as common names based on sound
Common popular standardization frameworks include the following examples:
-
Finite state machine (FSM) framework: Process encompassing multiple states where configurable rules are applied on each state. FSM includes steps like cleansing, tokenization, parsing and ambiguity resolution.
-
Patterns based framework: Process defined in configurable dictionaries enabling detectable patterns by data types. Typical steps include parsing, data type identification, normalization, and patterns resolution.
Published by HL7, Fast Healthcare Interoperability Resources (FHIR) is a standard for healthcare data exchange that supports web exchange standards formats like XML, JSON, HTTP, OAuth with RESTful architectures, and service-based architectures. Oracle Healthcare data repository and Oracle Health Master Person Index (OHMPI) provides a way to use FHIR to create patient longitudinal record efficiently and accurately.
Patient data deidentification
Patient health information (PHI) deidentification is not only required for medical research studies, comparative effectiveness studies, and policy assessments, but also in PHI agnostic matching, such as organ matching. Common industry practices include the following examples:
-
Safe-harbor method: Remove standard PHI attributes (About 18 types) such as names, identifiable numbers such as phone, account, biometric identifiers, full face photos, and license numbers. The process is widely followed and easier to automate and implement.
-
Expert determination: Requires that a healthcare statistical expert can corelate risks associated with identified attributes to justify its removal. This process is more time- and resource-intensive, custom, and provides greater accuracy.
Multiple implementations convert healthcare data into a common FHIR formats before turning it to a deidentification engine that uses the safe-harbor method for deidentification. Typical tools for deidentification consist of data redaction, dateshift, perturb, cryptohash, encrypt, substitute, and generalize.
A different method involves deidentification at the FHIR layer, which is more secure. This process involves deidentification at rest at the database or store level. Open source BERT transformer models like BioBert pretrained models, trained on several medical corpora like journals, medical articles, and publications of medical research, provide context-aware embeddings, and PHI named entity recognition (NER) can be used to clean or mask PHI identifiers.
Typically, OCI Data Science tools like OCI Autonomous Data Warehouse or OCI AI Language services and OCI Data Science platform are geared for open source deidentification processes and customizations to produce the desired outcome.
Organ matching and continuous improvement
Important key factors for matching are not only the medical factors like blood type, height, weight, and organ size but also geolocation distance between the donor and recipient, organ life, and the transport time. The organ matching process must include real-time, automated, and flexible outcomes, matching across many recipients requiring a continuous allocation process instead of a categorical with a few data points. The computation of a real-time predictive matching score must consider between continuously data updates from EHRs, geo-location, and organ vitality data streams and transplant candidate conditions.
Matching involves comparing specific fields in two standardized records and returning a weight that indicates the likelihood of a match between the two records. A higher weight between two records indicates a greater likelihood of a match. Data matching can be either deterministic or probabilistic. In deterministic matching, either record unique identifiers are compared to determine a match or an exact comparison is used between attributes. Because this process has some limitations in a probabilistic matching, several field values are compared between two records and each field is assigned a weight that indicates how closely the two field values match. Custom matching thresholds, optimum or ceiling matching, and un-matching conditional probabilities—m-prob and u-prob—allow the process to specify the range of attributes that match most to least.
You can achieve data matching using two flavors of the OCI infrastructure presented in the architecture. You can implement and tune both to determine the optimal matching. Each process has the following key points:
-
Prebuilt matching using OHMPI
-
Provides generic data matching methodology with a match engine framework with a choice of customizable parameters and weights
-
The setup is low-code, quick, database centric, runs within an Oracle Database application and is configuration-driven.
-
-
Flexible custom matching at scale using Oracle Container Engine for Kubernetes (OKE) and DevOps containers
Messaging and notifications
With multiple systems like donor data ingestion, deidentification, and geolocation sensing interacting to provide a real-time organ matching scenario, the communication between these systems must be robust, resilient, native to the cloud, and follow a standard unified messaging protocol. OCI Events and Notification services hub and functions provide the necessary infrastructure. These service are compliant with the Cloud Native Computing Foundation (CNCF) industry standard and allow interoperability between systems within OCI and across OPOs and other external systems. Rules defined on OCI services emitting events trigger various workflow steps with OCI Functions and Notification services. Typical scenarios include the following examples:
-
Initiation of the donor or recipient ingestion based on donor organ availability by OPOs
-
Initiation of donor and recipient FHIR standardization process
-
Preparing deidentified data at donor and transplant candidate levels
-
Triggering organ matching process based on organ availability, geo-location, organ viability, and other attributes
-
Status update transplant candidate on organ match
-
Status update operational monitoring of the system
You can use OCI Functions and Notification for the following processes:
-
Customizing OHMPI and IOT ingestion and standardization using the product REST API interface
-
You can also use Functions if using container-based architectures for match runs.
Organ transportation and health monitoring
Real-time organ health monitoring at rest or in motion is essential to validate the actual life of an organ before a transplant. This method aids or eliminates the need for organ viability checks because it reaches the transplant surgeons hands. The delivery is performed with real-time analysis of organ vitality and geolocation data streamed from the organ transport containers. With a short organ vitality window, transplants today are restricted by short geolocation distances between donor and recipient. Also, rematching and rerouting based on organ vitality data aren’t typically performed but highly wanted.
This process requires the following factors:
-
An efficient sensor based container that can stream data to a cloud data lakehouse continuously
-
A cold chain logistics provider responsible for delivery to the last mile
-
An effective and integrated rematching and rerouting system to find the next transplant candidate if needed
-
The streaming system provides established interfaces, such as API, across different cold chain logistics transportation vendors.
-
Transportation firms, such as Fedex and UPS, can provide API-based organ vitality and geolocation data to be quickly consumed.
The IoT service is geared to provide the following benefits:
-
Flexibility in streaming device adaptation, such as a IoT-enabled gateway, directly connected gateway or third-party gateway
-
Ingesting and integrating data from a multitude of payloads and brokers, such as HTTP or MQTT
-
Connect to OCI using Oracle Integration Cloud (OIC) and Oracle Analytics Cloud (OAC) adaptors and REST API
-
Simulation match testing possibility using a digital twin scenario
Transplant research
Transplant research areas aim to understand best practices and improve performance with a goal to increase transplants. Data inputs such as organ offer outcomes, transplant operations benchmarks, Key indicators, compliance, and performance are several key areas outlined by UNOS. However, deidentified patient records, match run outcomes, and the streaming organ vitality attributes provide a unified data platform for the researchers to investigate further. The OCI Data Platform can provide the following features and benefits:
-
A deidentified dataset access for donors and transplant patients for research
-
Patient historical and longitudinal records and geolocation attributes
-
Match run outcomes, match criteria, and match history
-
Any organ vitality attributes of importance, such as temperature and pH
-
Post-transplant outcomes
OCI Data Platform aids researchers with predictive model-based and open source data tools, such as Oracle Data Science, Spark-based real-time analytics tools, such as OCI Data Flow, OCI Streaming, and in-database ML tools within OCI Autonomous Database. This availability facilitates researchers to perform analysis directly on live and current deidentified datasets to develop models, operationalize them to test model drifts and their efficacies, operate between the cloud and local laptops or other on-premises systems, and integrate with other public data sources or pretrained and developed models. OCI CPU, GPU, and high-performance computing (HPC) Compute shapes also facilitate researchers to large, simulated workloads.
Organ transplant analytics
UNOS currently publishes many analytic reports for OPOs and the community, including the following examples:
-
Transplant benchmark reports: Customizable comparative reports providing insights to population listing practices and transplant activity for UNOS members at regional and national levels
-
Organ offer outcomes: A dashboard for visualizing organ acceptance by donor type with transplant and aggregate specific outcomes
-
Transplant compliance and performance reports: Clarifies post-transplant outcomes, waitlist outcomes by transplant and mortality and demographic waitlist by diagnosis, active status, and medical urgency factors
-
Executive level measures: Waitlist additions and management, organ offer characteristics, transplants performed, post-transplant stay, 24-hour high-level indicators, and trends
-
Enhanced staffing survey and analytics: Staffing survey experience in conjunction with transplant administration
However, these reports lack the self-service, scalability, unification, and extensibility features that a modern cloud based data platform provides. OAC with Oracle Autonomous Database on OCI Lakehouse provides the following benefits:
-
Operational dashboard covering the end-to-end organ transplant process
-
Real-time insights from the matching process
-
Customizable predictive match model simulations to aid researchers
-
Descriptive and historical data analysis on transplants
-
Prebuilt and custom reports and automated delivery from a cloud analytics system
Key takeaways of using an enterprise data platform
Implementing an enterprise cloud-based health data platform in OCI offers the following benefits:
-
Tools and integrations: The right combination of prebuilt applications, data platform tools and services, and compute infrastructure is required for successfully operating a complex data platform. OCI offers the following advantages:
-
Health industry-specific, such as HL7, and other industry-standard data source integration support with OIC adapters
-
Streaming provider and device integration flexibility with out-of-the-box adapters with OCI IoT
-
Prebuilt, configurable data-matching algorithm implemented inside the database with OHMPI and Oracle Autonomous Database
-
A flexible platform to quickly deploy code and orchestrate at scale with OCI Kubernetes engine
-
An out-of-the-box cloud based prebuilt event and notification system implementable across the entire organ transplant data fabric
-
A configurable and cloud-based analytic dashboard, reporting, and delivery solution with OAC
-
A unified data catalog to maintain the source of truth across participating data members in the system
-
-
Prebuilt health industry and government certifications: With a data platform typically operating in a hybrid multicloud environment, healthcare attestations are required at various areas of data residency. OCI Data Platform can provide attestations along the cloud boundaries and inside. OCI provides HIPPA, HITRUST CSF, and FedRamp compliance attestations. For more information, see HIPPA-accessed regions.
-
Healthcare data standardizations: Healthcare data standardizations involve more than standardizing healthcare codes. They involve various data normalizations, configuring and customizing standard data quality practices, and evolution over time. Healthy standardization requires a mix of prebuilt, configurable, and customizable platform aspects where you can take on more development by sourcing various open source libraries. OCI provides seamless standardization across healthcare applications, FHIR at EHR data ingestion, and a platform to develop custom Python libraries.
-
Scalability, performance, and cost: The utility value of this system is best realized when it automatically scales maintaining the same or higher performance at a decreasing cost rate. OCI Data Platform offers the following benefits:
-
A unified object storage-based data lakehouse to ingest various types of unstructured data and scalable autonomous data warehouse
-
A customizable data retention and archival features with OCI Object Storage and automatically managed backups and patches with live relational data storage
-
A scalable compute infrastructure with a wide range of CPU and GPU Compute shapes
-
-
Unified integration of tools and services platform: Most enterprise data platform spans and integrates across EHR data providers and tools to provide for real-time delivery and monitoring needs. OCI provides the following features:
-
A multicloud data platform across multiple EHR providers, healthcare integrations such as HL7 and FHIR, and data access through REST APIs and HTTP.
-
OIC provides necessary data transformations and imputations during ingestion
-
A unified cloud native event and messaging system that can operate independently and securely in isolation and provide for the needed workflow dependencies
-
Conclusion
The healthcare industry architecture discusses and illustrates the key areas necessary to deploy an enterprise level healthcare data platform. The core components are similar, and the platform has the following capabilities:
-
Implemented in an enterprise—whether a healthcare provider, payer, or transportation—where the criticality and automation of services are important
-
Although we developed with an OCI footprint, it can extend to a multicloud hybrid enterprise data fabric
-
Attempts to show how real-time integration between and across systems with different technologies and and can resolve services
The solution presented shows how to apply a prebuilt packaged solution’s functionality to a custom build with a cloud native solution. Enterprises can connect with Oracle Cloud Infrastructure to truly benefit from the solutions and personalized support that Oracle brings to enterprises.
For more information on the concepts in this post, see the following resources: