Large language models (LLMs) have made significant strides in text generation, problem-solving, and following instructions. As businesses integrate LLMs to develop cutting-edge solutions, the need for scalable, secure, and efficient deployment platforms becomes increasingly imperative. Kubernetes has risen as the preferred option for its scalability, flexibility, portability, and resilience.
In this blog post, we demonstrate how to deploy fine-tuned LLM inference containers on Oracle Container Engine for Kubernetes (OKE), an Oracle Cloud Infrastructure (OCI)-managed Kubernetes service that simplifies deployments and operations at scale for enterprises. This service enables them to retain the custom model and datasets within their own tenancy without relying on a third-party inference API.
HuggingFace text generation inference
Text generation inference (TGI) is an open source toolkit available in containers for serving popular LLMs. The example fine-tuned model in this post is based on Llama 2, but you can use TGI to deploy other open source LLMs, including Mistral, Falcon, BLOOM, and GPT-NeoX. TGI enables high-performance text generation with various optimization features supported on multiple AI accelerators, including NVIDIA GPUs with CUDA 12.2+.
GPU memory consideration
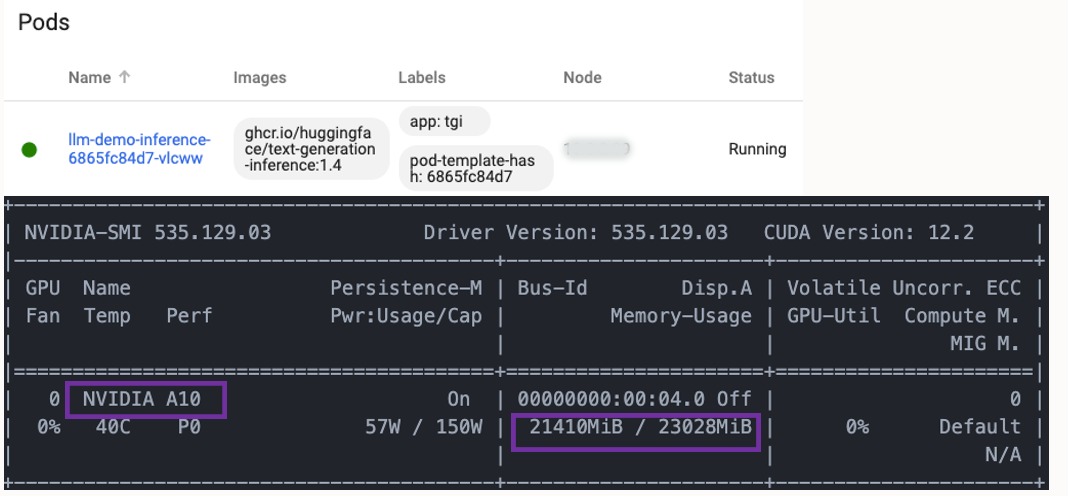
The GPU memory requirement is largely determined by pretrained LLM size. For example, Llama 2 7B (7 billion parameters) loaded in 16-bit precision requires 7 billion * 2 bytes = 14 GB for the model weights. Quantization is a technique used to reduce model size and improve inferencing performance by decreasing precision without significantly sacrificing accuracy. In this example, we use the quantization feature of TGI to load a fine-tuned model based on Llama 2 13B in 8-bit precision and fit it on VM.GPU.A10.1 (single NVIDIA A10 Tensor Core GPU with 24-GB VRAM). The following image depicts the real memory utilization after the inference container loads the quantized model. Alternatively, consider employing a smaller model, opting for a GPU instance with larger memory capacity, or selecting an instance with multiple GPUs, such as VM.GPU.A10.2 (2x NVIDIA A10 GPUs), to prevent the CUDA out-of-memory error. By default, TGI shards across and uses all available GPUs to run the model.
Model loading
TGI supports loading models from HuggingFace model hub or locally. To retrieve a custom LLM from the OCI Object Storage service, we created a Python script using the OCI Python software developer SDK, packaged it as a container, and stored the Docker image on the OCI Container Registry. This model-downloader container runs before the initialization of TGI containers. It retrieves the model files from Object Storage and stores them on the emptyDir volumes, enabling sharing with TGI containers within the same pod.
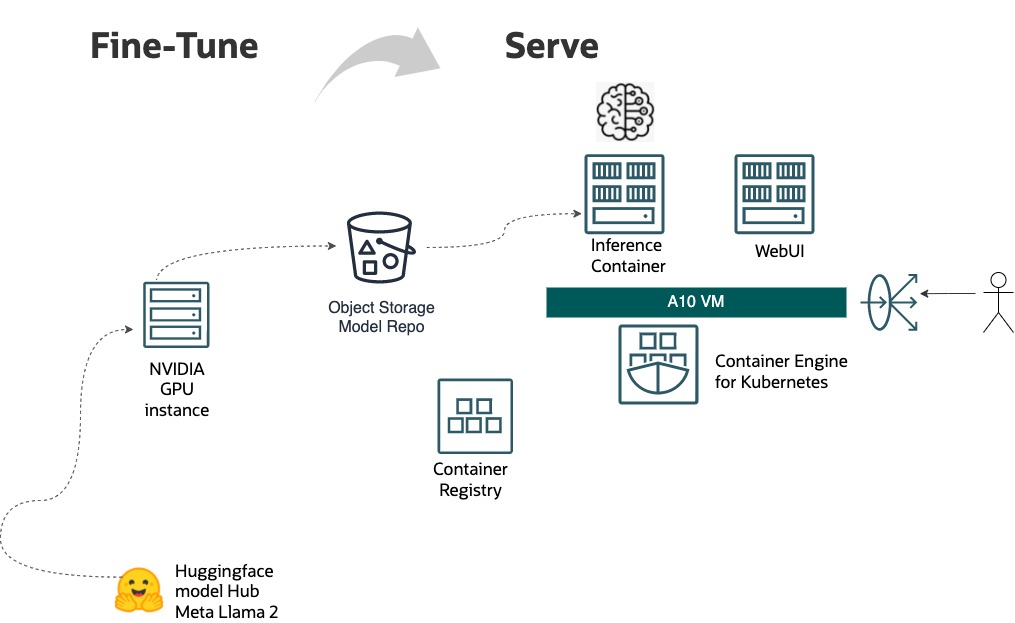
Deploying the LLM container on OKE
-
(optional) Take one of the pretrained LLMs from HuggingFace model hub, such as Meta Llama2 13B, and fine-tune it with a targeted dataset on an OCI NVIDIA GPU Compute instance.
-
Save the customized LLM locally and upload it to OCI Object Storage as a model repository.
-
Deploy an OKE cluster and create a node pool consisting of an A10.1 virtual machine (VM) Compute instance powered by NVIDIA A10 Tensor Core GPUs (or any other Compute instance you want). OKE offers worker node images with preinstalled NVIDIA GPU drivers.
-
Install NVIDIA device plugin for Kubernetes, a DaemonSet that allows you to run GPU enabled containers in the Kubernetes cluster.
-
Build a Docker image for the model-downloader container to pull model files from Object Storage service. (The previous session provides more details.)
-
Create a Kubernetes deployment to roll out the TGI containers and model-downloader container. To schedule the TGI container on GPU, specify the resources limit using “nvidia.com/gpu.” Run model-downloader as Init Container to ensure that TGI container only starts after the successful completion of model downloads.
-
Create a Kubernetes service of type “Loadbalancer.” OKE automatically spawns an OCI load balancer to expose the TGI application API externally.
-
To interact with the model, you can use curl by sending a request to <Load Balancer IP address>:<port>/generate, or deploy an inference client, such as Gradio, to observe your custom LLM in action.
Conclusion
Deploying a production-ready LLM becomes straightforward when using the HuggingFace TGI container and OKE. This approach allows you to harness the benefits of Kubernetes without the complexities of deploying and managing a Kubernetes cluster. The customized LLMs are fine-tuned and hosted within your Oracle Cloud Infrastructure tenancy, offering complete control over data privacy and model security.
For more information, see the following resources:
