Large language models (LLMs) exhibit an impressive capability to comprehend prompts in natural language and produce coherent responses. This ability has introduced fresh opportunities for transforming natural language into structured query languages, such as SQL. Unlike previously, where crafting SQL queries necessitated technical proficiency, LLMs empower users to articulate their inputs in simple English, enabling the automatic generation of the corresponding SQL code.
Code Llama
The prompt is crucial when using LLMs to translate natural language into SQL queries. Using the LLM model, Code Llama, an AI model built on top of Llama 2 fine-tuned for generating and discussing code, we evaluated with different prompt engineering techniques. You can use text prompts to generate and discuss code. Code Llama stands as a cutting-edge solution among publicly accessible LLMs for coding tasks. It holds the promise of expediting workflows and enhancing efficiency for developers while also reducing the learning curve for coding novices. Code Llama has the capacity to serve as both a productivity tool and an educational resource, aiding programmers in crafting more robust and well-documented software.
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion–34 billion parameters. It acts as the repository for the 34B instruct-tuned version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. For other models, see the resources at the end of this blog post.
| Type | Base model | Python | Instruct |
| 7B | codellama/CodeLlama-7b-hf | codellama/CodeLlama-7b-Python-hf | codellama/CodeLlama-7b-Instruct-hf |
| 13B | codellama/CodeLlama-13b-hf | codellama/CodeLlama-13b-Python-hf | codellama/CodeLlama-13b-Instruct-hf |
| 34B | codellama/CodeLlama-34b-hf | codellama/CodeLlama-34b-Python-hf | codellama/CodeLlama-34b-Instruct-hf |
For detailed information about the models, see Code Llama on Hugging Face.
At a high level, you have the following important considerations for prompt engineering when doing natural language to SQL conversion:
-
Employ clear instructions: Using clear and straightforward natural language prompts facilitates the LLM’s comprehension and translation
-
Supply ample context: The LLM requires understanding that the user seeks an SQL query, along with specifics about the database schema, such as table and column names
-
Incorporate examples: Offering a few examples of natural language prompts paired with their corresponding SQL queries can assist the LLM in generating queries with the correct syntax
-
Utilize retrieval augmented generation (RAG): Retrieving pertinent sample pairs of natural language prompts and SQL queries can enhance accuracy
Challenges
With the advent of the generative AI wave, particularly the subset of LLM dedicated to text generation, nearly every organization is eager to integrate a generative AI application for their specific needs. While this trend might seem relatively straightforward, given the abundance of high-performing LLMs emerging nowadays, the reality is quite different.
While many robust LLMs effectively handle a broad spectrum of knowledge in general, they often fall significantly short when dealing with localized enterprise or domain-specific information. From an organizational standpoint, the ability to respond based on localized knowledge is often the primary requirement. For instance, a text-to-SQL generation model not only needs to generate syntactically correct SQL queries but also requires knowledge of the business semantics unique to the enterprise and the protected local information regarding data schema.
Fine-tuning
Fine-tuning is the process of further training a pretrained model on a task specific dataset. Generally in case of LLMs, the base pretraining is done on very large datasets, while the fine-tuning is on much smaller datasets.
The comprehensive training process integral to constructing an LLM is considerably expensive in both monetary and time-related aspects. Consequently, the option isn’t efficient for experimenting with business use case implementations in any enterprise. Even when considering operational costs associated with LLM usage, the expenses tend to be high because of inefficiencies in the implementation approaches employed— a reality that holds true even when employing some of the methodologies we’re about to explore.
So, let’s discuss one quick, simple technique to provide better, accurate results.
Prompt engineering
Prompting is a method that directs a language model’s response behavior by refining the provided inputs. The techniques for prompting can range from simple phrases to detailed instructions, depending on the task requirements and the capabilities of the model. The process of designing and optimizing prompts for a specific task, aiming to pose the right questions, is referred to as prompt engineering.
Essentially, prompt engineering aids LLMs in generating the most suitable response for a given purpose and context. It becomes especially crucial in enterprise business applications that require responses with a thorough understanding of the intent and context of the request. Some practiced prompting techniques include basic direct prompting, role prompting involving model role assignment strategies, few-shot prompting incorporating in-prompt demonstrations, chain-of-thought (CoT) Prompting with intermediate step guidance, and self-ask prompting involving input decomposition.
When generating SQL from natural language with LLMs, offering precise instructions in the prompt is vital for controlling the model’s output. In our experimentation with Code Llama models, an effective approach is to prompt description with the following string within the prompt to annotate distinct components:
# An example of the SQL would be 'SELECT * FROM orders WHERE DATE(orderDate) = CURDATE() - INTERVAL 1 DAY AND status = 'ORDERED'These comments with # serve as instructions, explicitly dictating how the model should format the SQL. For example, directing the model to articulate the query between ## can streamline verbose output. Without these instructions, Code Llama models tend to be talkative, explaining the SQL structure and introducing unnecessary complexity in post-processing, leading to an increased consumption of output tokens. Incorporating the table schema starting with # ### the database schema signals to the model the boundaries of the context.
Approach
-
Define the specific questions, sample or reference SQL, and table schema. The type of the questions must be very specific.
Can you tell me about the orders which are completed one day ago (Type 1) -
Reference the SQL:
Select * from orders where WHERE DATE(orderdate) = CURDATE() - INTERVAL 1 DAY AND status = 'COMPLETED' (Reference SQL for Type 1) -
Reference the schema:
CREATE TABLE IF NOT EXISTS orders ( <define your schema>); -
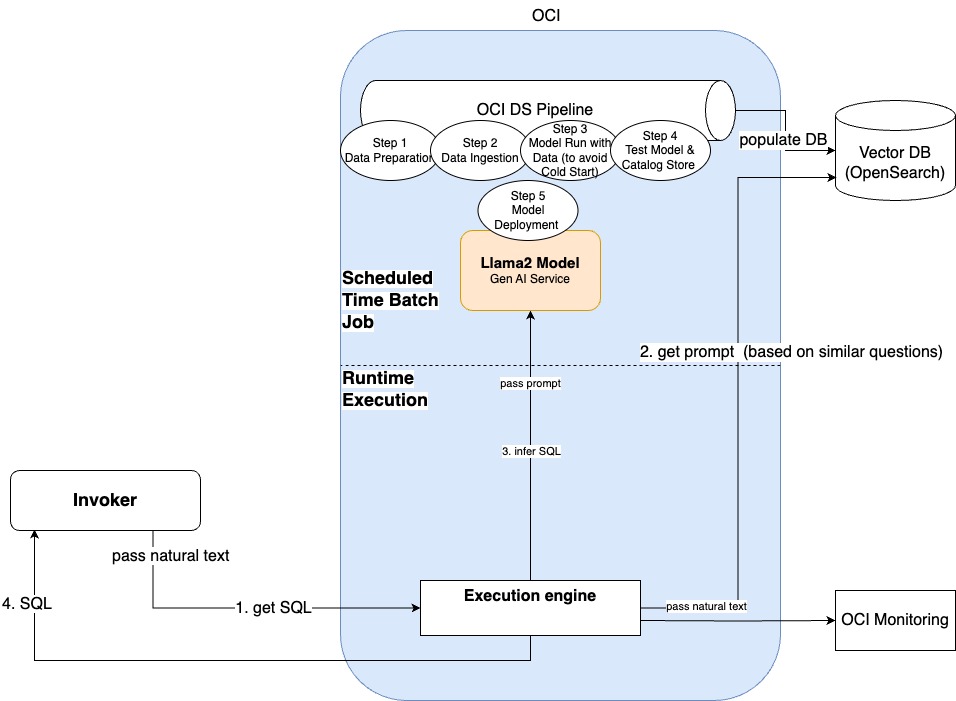
You can define this information in a vector database, such as Open Search, in an index. In the index, every document has the following attributes:
-
Reference_Question
-
Reference_SQL
-
Schema
-
-
Pass the natural language question by invoking an Open Search query with a similarity model to get the best document returned for the type defined in the index. This command returns the reference SQL and the schema.
-
Based on the question, schema, and sample SQL, the prompt is created and the model is invoked.
Let’s assume that the data is already ingested in the vector database. Now a user can ask a question: “Show me all the orders that have yet to be completed and were ordered two weeks ago.” This question gives the best similarity with a reference question. When the prompt is created, the model infers the following information:
Select * from orders where WHERE DATE(orderdate) = CURDATE() - INTERVAL 14 DAY AND status = 'INCOMPLETE'
Code snippet
You can persist model in Oracle Cloud Infrastructure (OCI) Object Storage and import it from Object Storage or download it into the PyTorch Conda environment in OCI Data Science for experimenting and use it from the Conda environment cache.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "codellama/CodeLlama-13b-Instruct-hf"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
eos_token_id = tokenizer.eos_token_id
question = "Can you tell me about the orders which are completed two days ago?"
eval_prompt = """### Task
# Generate a SQL query to answer the following question:
# `{question}
# ### Database Schema
# This query will run on a database whose schema is represented in this string:
# Don't use joins for this schema and if all columns are required give the (*) notation.
# CREATE TABLE IF NOT EXISTS orders (
# <define your table schema>;
# An example of the SQL would be 'SELECT * FROM orders WHERE DATE(orderdate) = CURDATE() - INTERVAL 1 DAY AND status = 'COMPLETED'
# ### SQL
# Given the database schema, here is the SQL query that answers `{question}`:
# ```sql
# """.format(question=question)
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
#model.eval()
import sqlparse
outputs = tokenizer.batch_decode(model.generate(**model_input,eos_token_id=eos_token_id,pad_token_id=eos_token_id,max_new_tokens=100,do_sample=False,
num_beams=1), skip_special_tokens=True)
print(sqlparse.format(outputs[0].split("```sql")[-1], reindent=True))Conclusion
In the rapidly evolving world of AI, the art of prompting LLMs offers unparalleled flexibility and ease of use, making advanced AI accessible to a wide audience. From direct and contextual prompting for straightforward queries to few-shot and chain-of-thought techniques for complex problem-solving, these methods unlock the vast potential of LLMs. They allow for rapid prototyping, efficient data processing, and customized responses across various contexts. Notably, contextual and chain-of-thought prompting enhances the models’ problem-solving capabilities by simulating a step-by-step reasoning process. Furthermore, the adaptability of these models to different tasks through simple prompting reduces the need for extensive retraining, saving valuable time and resources. This approach also encourages creative exploration, leading to innovative solutions and ideas.
Try Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
-
Full sample, including all files in OCI Data Science sample repository on GitHub.
-
Visit our service documentation.
-
Try one of our LiveLabs. Search for “data science.”
-
Got questions? Reach out to us at ask-oci-data-science_grp@oracle.com

