Oracle Cloud Infrastructure (OCI)’s fully managed platform for data science model deployments are managed resources to deploy machine learning (ML) models as HTTP endpoint for serving requests for model predictions. This default service-managed offering allows for a quick experience by creating many of the required component automatically, freeing you from having to create and manage them. This quick, easy way to deploy models to high-performing endpoints uses a managed, prebuilt container, which supports more dependencies through Conda packs.
However, in some scenarios, you might prefer to use your own containers. If you need to install many libraries or the libraries aren’t publicly available, it can be better to have them preinstalled in the container, or if you already use a specific server for inference and prefer to continue using it.
Introducing custom containers in OCI Data Science model deployment
With the support for custom containers we’re releasing today, OCI Data Science model deployment can pull container images from OCI Container Registry and deploy them as inference endpoints. You can package system and language dependencies, install, and configure inference servers and set up different language runtimes using your own containers. All this work happens within well-defined boundaries of an interface with the model deployment resource and keeps the infrastructure managed by the service, so you don’t have to worry about compute allocation or scale.
For more information on implementation interface, policy setup, and best practices, see the Oracle Help Center.
Deploying models with NVIDIA Triton Inference Server image
NVIDIA Triton Inference Server, part of NVIDIA AI Enterprise, the foundational software layer of NVIDIA AI, streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained AI models from any framework on any GPU- or CPU-based infrastructure. It provides AI researchers and data scientists the freedom to choose the right framework for their projects without impacting production deployment. It also helps developers deliver high-performance inference across cloud, on-premises, edge, and embedded devices.
Triton has the following key features:
-
Concurrent model processing: Serves multiple ML models simultaneously. This feature is particularly useful when you need to deploy and manage several models together in a single system.
-
Dynamic batching: Enables the server to batch requests together dynamically based on the workload and latency requirements to help improve performance.
Today, OCI Data Science’s model deployment releases support for NVIDIA Triton Inference Server, enabling you to enjoy all the benefits of working with Triton software and keeping your workloads on OCI’s scalable, reliable, enterprise-grade cloud. Data Science model deployment can use the NVIDIA Triton image to deploy ML models trained on popular ML frameworks.
Deploying NVIDIA Triton Inference Server involves a few steps. First, push the selected Triton image to OCI Container Registry, and save the model to the model catalog. Triton expects a certain model repository folder structure, which you apply into the model artifact saved to the model catalog. For details on both steps and other model serving containers, see the GitHub sample repository.
Next, create a Triton-supported model deployment. To reduce the friction and enable seamless Triton integration to OCI services, model deployment extended its custom container offering to configure the endpoint mapping by passing the following flag as an environment variable:
CONTAINER_TYPE = TRITON
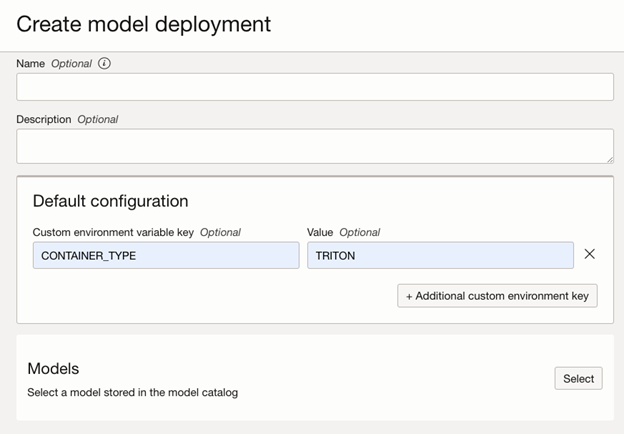
This environment variable instructs the inference server to wire the service-mandated endpoint:
GET /health --> GET /v2/health/ready
POST /predict --> POST /v2/models/${MODEL_NAME}/versions/${MODEL_VERSION}/inferIf you don’t use the environment variable, you can still deploy Triton Inference Server, but you must map the endpoint for the endpoints to work. Triton exposes HTTP and REST endpoints based on KServe V2 inference protocol standard and can’t customize them to meet the Data Science service endpoint contract. In this case, package a reverse proxy, such as NGINX, to map the service-mandated endpoints to the endpoints provided by the framework of your choice.
You can create model deployments from OCI software developer kits (SDKs), APIs, or the Oracle Cloud Console. The following screenshot shows the information that you can input to create a Triton deployment:
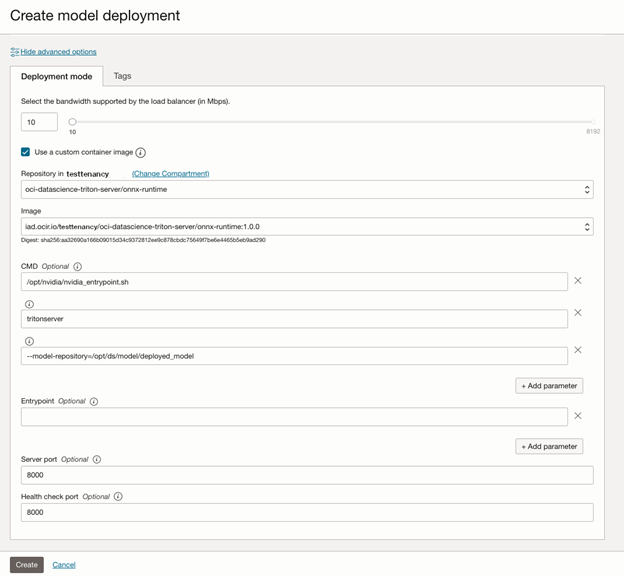
When you click Create, the model deployment pulls the Triton Inference Server image from OCI Container Registry, runs it, pulls the model from the Model Catalog, and makes it available to the Triton server to load and serve. The following graphic show the high-level architecture of how the solution works:
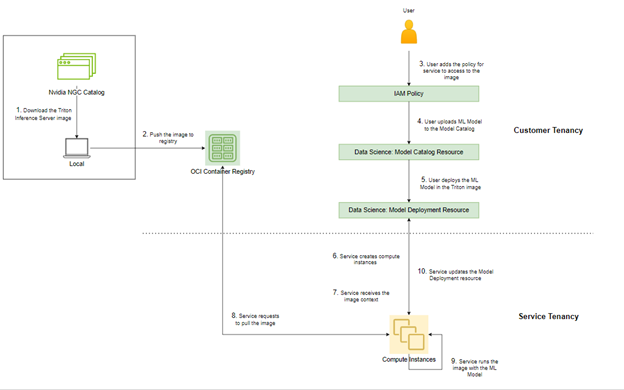
Conclusion
Custom container support for model deployment is a valuable addition to OCI Data Science, ensuring efficient and scalable deployment of ML models and enabling you to choose from a wider variety of model serving options. With personalized images, you can use any inference server and create reproducible deployment environments ensuring that the model performs consistently across different deployments. Using this support for custom containers, you can deploy ML models on NVIDIA’s Triton Inference Server, a part of NVIDIA AI Enterprise, to utilize its rich frameworks support and advanced features like concurrent model execution and dynamic batching.
Try an Oracle Cloud Free Trial! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
-
Full sample including all files in OCI Data Science sample repository on GitHub.
-
Visit our Data Science service documentation.
-
Read about Triton Inference Server and NVIDIA AI Enterprise
-
Configure your OCI tenancy with these setup instructions and start using OCI Data Science.
-
Try one of our LiveLabs. Search for “data science.”

