
[Update from 4/18] OCI Data Science released AI Quick Actions, a no-code solution to fine-tune, deploy, and evaluate popular Large Language Models. You can open a notebook session to try it out. This blog post will guide you on how to work with LLMs via code, for optimal customization and flexibility.
In the ever-evolving realm of artificial intelligence (AI), groundbreaking advancements in large language models (LLMs) are continuously shaping our interactions with and utilization of AI capabilities. One such notable cutting-edge innovation is Mistral-7B, an open source foundation model developed by Mistral AI. Mistral-7B is released under the permissive Apache 2.0 license, allowing unrestricted usage. This model underscores the idea that the size of a language model in number of parameters isn’t the sole determining factor for its efficiency. Despite having a modest number of parameters, this optimized model excels in condensing knowledge and enhancing deep reasoning abilities.
Notably, Mistral-7B is engineered to excel in two key areas: Natural language tasks and coding tasks. This dual capability distinguishes it from other models, bridging linguistic proficiency with technical expertise essential for coding applications. Mistral-7B uses grouped-query attention (GQA) to enhance inference speed and Sliding Window Attention (SWA) for efficiently managing longer sequences at a reduced computational cost. With an extensive context length of 8,000 tokens, it exhibits minimal latency and impressive throughput, outperforming larger model counterparts while maintaining low memory requirements. Mistral-7B-Instruct is a fine-tuned version of the base model using various publicly available conversation datasets.
Comparison with Llama2 13B
Despite having 7B parameters, Mistral 7B outperforms Llama2 13B on all metrics and is on par with Llama 34B on key benchmarks. The compactness of the Mistral 7B makes it easier to fit on smaller GPU compared to Llama2 13B model. The following table depicts the hardware requirement for both the models.
| Model | VRAM minimum | Hardware required |
|---|---|---|
| Mistral 7B | 12 GB + inference | 1 A10 (24-GB VRAM) |
| Llama 2 13B | 26 GB + inference | 2 A10 (24-GB VRAM) |
The reduction in memory footprint of Mistral 7B model in terms of inference further extend to secondary aspects, notably reduced carbon footprints. To compute the approximate carbon footprint for inference of both the models, we used ML CO2 Impact calculator. The maximum power limit for a single NVIDIA A10 GPU is 150 W. Mistral 7B inference server using A10 generates 4.5 kg-equivalent CO2, whereas the CO2-equivalent estimate for running Llama2 13B on 2 A10 shape for 100 hours is 9 kg-equivalent CO2, which is the same amount of CO2-equivalent as the driving average ICE car for 39.3 km.
Deploying LLMs poses challenges because of a scarcity of high-end GPUs, prompting a time-consuming and labor-intensive quest for accessible GPU instances across diverse regions. Another challenge is the substantial expenses tied to GPUs. The compactness of Mistral 7B over Llama2 13B proves to be a valuable solution in streamlining the deployment process and reducing the financial burden associated with large language models.
Here, we present the throughput for an increasing number of concurrent users on A10.2 with a constant maximum output tokens value of 512. We utilized the vLLM inference server container for model deployments. The throughput shows the speed at which tokens are processed per second for fixed number of input and output tokens.
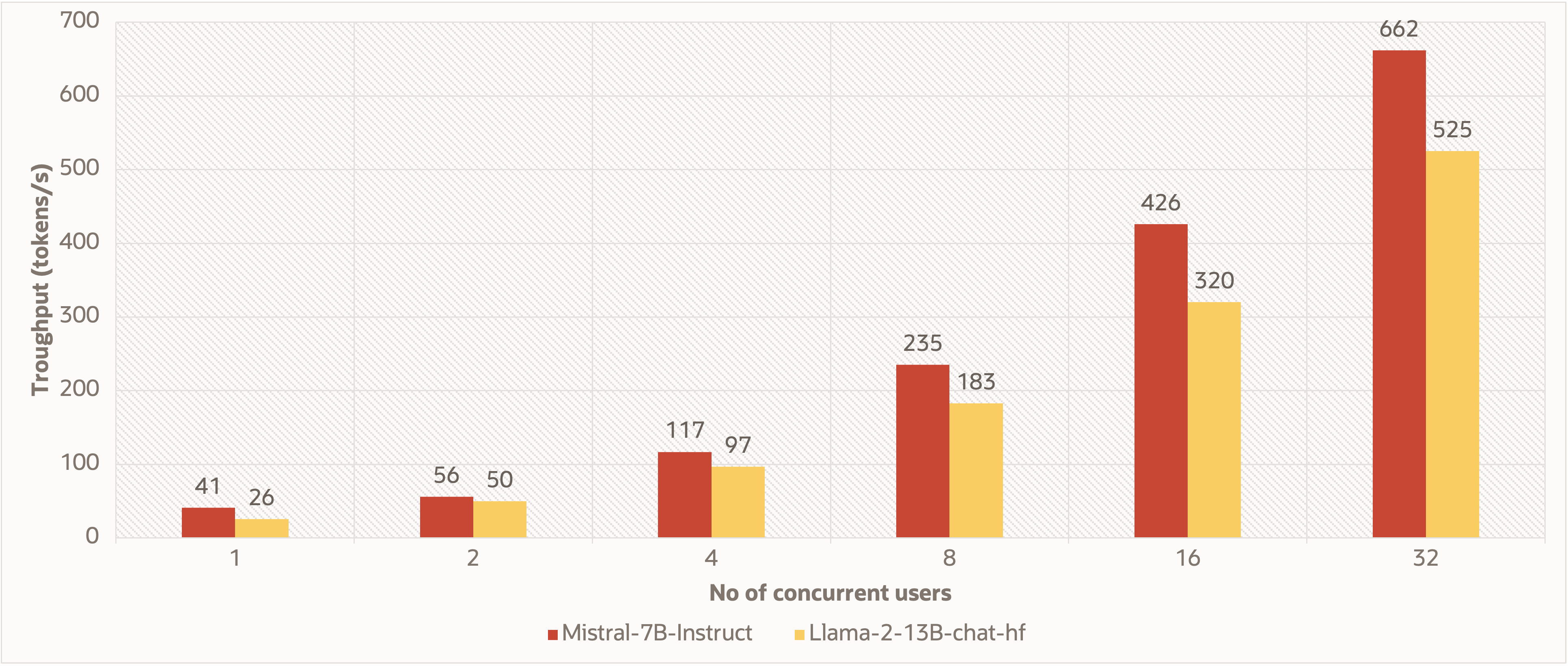
The numbers in the graph indicate the processing efficiency of these models when handling a varying number of users concurrently. The throughput for Mistral 7B Instruct is higher than that of the Llama2 13B model, regardless of the number of concurrent users.
Deployment on OCI Cloud platform
Oracle Cloud Infrastructure (OCI) Data Science is a fully managed platform for data scientists and machine learning (ML) engineers to train, manage, deploy, and monitor ML models in a scalable, secure, enterprise environment. You can train and deploy any model, including LLMs in the Data Science service.
This blog post signifies a step forward in unifying LLM deployment within the Oracle Cloud Infrastructure (OCI) Data Science Platform and further expanding on the previous blog, Deploy Llama 2 in OCI Data Science.
For the step-by-step walkthrough of the process, see the AI samples GitHub repository.
Conclusion
GPUs are costly and in high demand. Using a compact model, such as Mistral 7B significantly enhances inference times, reduces inference costs, and minimizes carbon footprints, all without compromising model efficiency.
In upcoming posts, we add more LLM depolyment guides and benchmarking. Stay tuned for more!
Try Oracle Cloud Free Tier! A 30-day trial with US$300 in free credits gives you access to Oracle Cloud Infrastructure Data Science service. For more information, see the following resources:
-
Full sample, including all files in OCI Data Science sample repository on GitHub.
-
Visit our service documentation.
-
Try one of our LiveLabs. Search for “data science.”
-
Got questions? Reach out to us at ask-oci-data-science_grp@oracle.com.


