This first article in the Machine Learning Inference Architectures blog series describes how to implement a highly scalable machine learning (ML) model inference solution on OCI using platform-as-a-service (PaaS) services.
The terms “model inference solution” and “solution” are used interchangeably to refer to an ML model inferencing solution. The capabilities exposed by this solution supplement the out-of-the-box capabilities provided by OCI Data Science.
Before we delve into the specifics and internals of the solution, we must understand the rationale for implementing it. Customers need a real-time ML model inferencing solution with the following capabilities:
-
Elastically scales and can infer many ML models (1 … N)
-
Supports hybrid model deployment on OCI, other public clouds, and on-premises
-
Supports ML model deployments on the network edge, such as remote and satellite locations
-
Is easy to configure, deploy, manage, extend, and maintain and applies DevOps best practices
-
Is robust, reliable and production-grade
-
Is cost effective and economical and maximizes resource utilization and optimizes infrastructure costs
-
Automates and increases the velocity of ML model deployments and accelerates delivery of new model releases with quick time-to-value
-
Supports ML model deployments on multiple compute types: CPUs and GPUs
Challenges with serving ML models at scale
As customers use data science platforms to build ML models and create intelligent applications, they need a low-cost inferencing solution which automates ML model deployments and makes the models available for enterprise-wide consumption.
Typically, in large enterprises, dozens and hundreds of ML models can be deployed in production. Many enterprise apps owned by different departments or groups can use these models. So, it might not be feasible or cost effective for individual departments to host and manage the ML models and apps themselves. Instead, the teams need an MLOps-based solution that eliminates the need for duplicating infra resources, supports multiple environments (Development, QA, preproduction, and production), and reduces costs and management overhead.
As more ML models are built and deployed in production, sometimes managing multiple API endpoints poses challenges and complicates the deployment architecture. Exposing multiple endpoints affects API consumers because they need to constantly track and update endpoint URIs within client applications, which can affect application availability and result in downtime. To keep the management overhead and costs to a minimum, customers usually prefer deploying fewer API endpoints in production.
QA teams often need separate environments for conducting functional and regression tests on ML models, which often requires the use of more infrastructure resources and adds to the operational costs.
Business and application development teams in medium-to-large enterprises often require advanced service mesh capabilities, such as blue-green and canary deployments, A/B testing, and traffic management capabilities such as traffic shifting, traffic mirroring, fault injection, request timeouts, and circuit breaking. These features require the use of service mesh technologies, which not only add to infrastructure costs but also increase the complexity of the operational architecture.
For many customers, provisioning dedicated infrastructure resources, such as compute, networking, and storage, for running individual ML models might not be feasible and cost effective. In certain business scenarios, customers must manage multiple versions of ML models in production. So, they must provision additional infrastructure resources, such as API gateways, to route the inference requests to the correct model version. Consequently, the operational architecture becomes complicated, and expensive to manage and maintain. For production deployments, customers need a low cost highly available solution architecture that shortens the model deployment time by applying DevOps best practices, in essence an architecture that delivers quick time to value.
To support high inference API call volumes, such as concurrent API calls, and at the same time deliver low API response times and low latency, multiple ML model server instances must be provisioned, requiring more infrastructure resources, such as load balancers and virtual machines (VM). This addition has a negative impact on operational costs.
Machine learning workflow
Let’s take a quick look at the ML workflow in OCI Data Science to help us understand where and how the model inference server fits into the overall solution. For brevity, the data ingestion and preprocessing steps that are typically part of Data Science and ML pipelines have been excluded from the workflow.
A machine learning workflow primarily consists of two phases. In the training phase, data scientists run multiple model training experiments in OCI Data Science, fine-tune hyper-parameters and evaluate model performance. When you achieve the performance metrics you want, the models are registered in Data Science Model Catalog.
In the deployment phase, ML models are encapsulated within web APIs and deployed on a scalable runtime in production. Finally, the deployed models are consumed (invoked) by enterprise applications and used to infer and predict important business outcomes.
The following flow diagram depicts the two phases of the ML workflow and showcases how you can quickly expose registered ML models in OCI Data Science through a generic REST API endpoint using the model inference server.
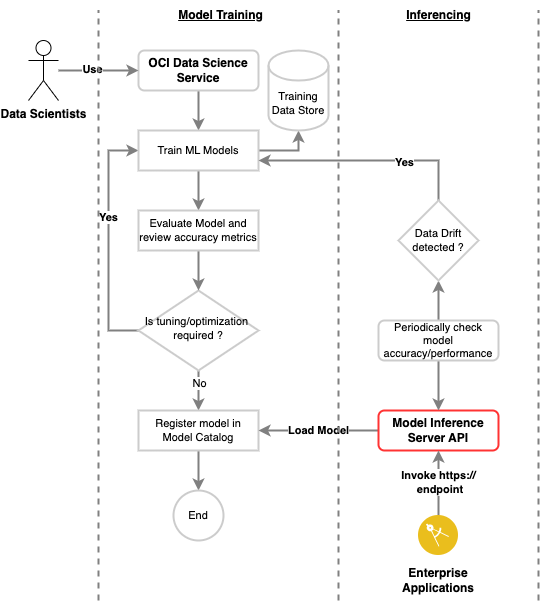
Implementing an enterprise-grade model inferencing solution with Kubernetes
OCI Data Science provides an out-of-the-box feature for deploying pretrained ML models. With this feature, customers don’t have to deal with provisioning or managing the underlying infrastructure because the service fully manages it. OCI Data Science also supports using NVIDIA Triton Inference Server and other inference servers, providing the ability for customers to deploy custom containers. However, enterprise customers who have already adopted Oracle Container Engine for Kubernetes (or standard Kubernetes) for deploying enterprise application workloads, such as web APIs and microservices, stand to benefit from implementing this model inference solution.
Let’s discuss the benefits of Kubernetes and explain its salient features.
Machine learning inferencing and Kubernetes reference architecture
Solution components
The model inference solution is comprised of the following components:
-
Model inference server (MIS): A lightweight inference server implemented as a microservice application. The inference server exposes a generic web REST API endpoint. A single instance of the inference server can handle and serve predictions for multiple (1 .. N) machine learning models. For details, refer to the section, Invoking the ML models.
-
OCI Data Science: A comprehensive data science platform that supports the end-to-end model development and deployment lifecycle. It allows you to train, evaluate, test, and deploy ML models.
-
OCI DevOps: A DevOps platform that automates inference server container image builds and server deployments to multiple environments through delivery pipelines.
-
OCI Key Vault: A secure key vault that provides secure storage for API keys.
-
OCI Artifact Registry: An artifact repository for publishing software libraries and other artifacts.
-
OCI Container Registry: A standards-based, Cloud Native Computing Foundation (CNCF) compliant container registry. The registry is primarily used for storing and publishing inference server container images and Helm charts.
-
Oracle Container Engine for Kubernetes (OKE): A robust Kubernetes container orchestration platform. Kubernetes manages the lifecycle of deployed inference server container instances within a cluster.
-
OCI Object Storage: A cloud native object storage service used for storing custom Python Conda environments, training, and inference data sets.
-
(Optional) OCI Code Repository: A full-featured GitHub based code repository. You can use any Git-based open source code repository with this solution.
Overview
In this blog, we describe the reference architecture for an internal, private deployment of the model inference solution. The inference server APIs exposed by the solution can only be consumed by applications deployed within the same OCI tenant. In a subsequent blog, we build on this reference architecture and showcase how to securely expose the inference server APIs to external applications that reside outside the OCI tenant.
Most importantly, this reference architecture uses PaaS services on OCI, listed in the Solution Components section, to provide service level guarantees that are essential for delivering a production grade solution that automates deployment, is secure, robust, highly available, reliable, and fault tolerant, and can easily scale to meet enterprise inferencing call volumes and high demands.
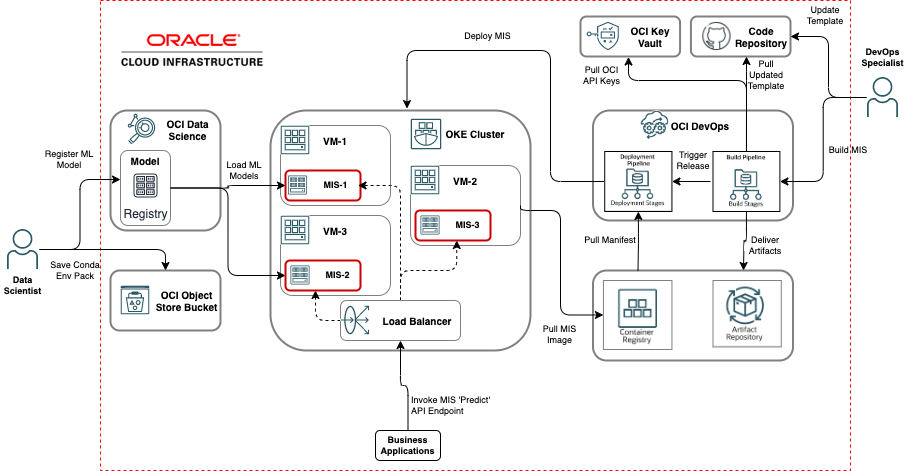
Although the reference architecture uses an OKE cluster as the deployment runtime, the inference server can just as easily be deployed on OCI VM Instance Pool, OCI Function or OCI Container Instance (with minimal changes). The entire solution can also be deployed within a private self-managed Kubernetes cluster on-premises, on OCI or other public clouds.
Using an OKE Cluster as the target deployment platform for the model inference server has several benefits. Kubernetes has built-in support for the following advanced capabilities:
-
Elastic scalability: Kubernetes can automatically scale MIS instances up or down based on API request traffic volumes.
-
High availability: Running multiple MIS instances (Greater than or equal to two) ensures that the servers are always available to handle inference requests.
-
Self-healing: Kubernetes maintains heartbeat on running MIS instances and automagically recycles them when they become unresponsive or stop unexpectedly. Kubernetes also automatically shifts application workloads from an unresponsive or unhealthy node or virtual machine (VM) to another healthy node and even recycles failed nodes. Cluster nodes and server instances deployed on the nodes self-heal and are always available.
-
Load balancing: Kubernetes intelligently distributes the incoming inference requests among available MIS instances and ensures that individual server instances aren’t overwhelmed with too many requests.
-
Zero-impact deployment: Kubernetes supports multiple deployment strategies, such as rolling and recreating upgrades, which result in little-to-no downtime when upgrading model versions. Kubernetes also supports canary, A/B, and blue-green deployments.
-
Support for advanced capabilities: Customers who need advanced traffic management, security, and observability capabilities can benefit from deploying proven open source service mesh technologies on Kubernetes, such as Istio or Linkerd, and use provided features right away.
-
Maximizes resource utilization: Kubernetes determines the compute capacity (CPUs and memory) available on each cluster node and efficiently schedules and runs multiple MIS instances concurrently on each CPU or GPU, serving multiple models.
Solution walkthrough
Data scientist
-
Data scientists use OCI Data Science platform to train and evaluate ML models. When they’re satisfied with the model’s accuracy and precision, they can register the model in OCI Data Science Model Catalog.
-
The data scientist might also need to package the Conda environment (Conda Pack) used to train the models and upload the same to an OCI Object Storage bucket.
DevOps specialist or engineer
-
The DevOps specialist updates the inference server container image build file (dockerfile) with model runtime info. (Conda Env) and saves it within their code repository, such as OCI Code Repository or any GitHub repo. The specialist might also need to update other required artifacts, such as DevOps build spec files, Helm charts, and OCI config files, and save them within the respective repositories on OCI.
-
The specialist then logs into the Oracle Cloud Console and runs the DevOps build pipeline. This pipeline builds the model inference server container image and pushes the same to an OCI container registry.
-
When the build pipeline successfully finishes, the release pipeline is triggered. This pipeline pulls the inference server deployment manifest (Helm chart) from the container registry and initiates the deployment of the inference server on the target OKE (or Kubernetes) cluster.
-
The DevOps specialist verifies that the server deployment on OKE has succeeded.
Invoking the ML models and running inference
When ML models are registered in OCI Data Science catalog, they’re immediately available for inferencing through the inference server API endpoint.
The model inference server exposes a generic, unified API endpoint with separate URI paths to list, load, remove, and upload ML models. These ML models must be registered in the model catalog within OCI Data Science Service or exported as a model artifact from OCI Data Science. The server also exposes URI paths to retrieve model and server information and run inferences with the predict API.
| API description | URI paths |
HTTP method |
Query parameters |
|---|---|---|---|
| List ML models registered in the model catalog within an OCI Compartment and Data Science project |
/endpoint/listmodels/ |
GET |
compartment_id – OCI Compartment ID project_id – OCI Data Science Project ID no_of_models – No. of models returned in response. Default = 400. |
| Retrieve model metadata (Taxonomy) for an ML model |
/endpoint/getmodelinfo/{model_id} |
GET |
|
| Load ML model artifacts from OCI Data Science Model catalog |
/endpoint/loadmodel/{model_id} |
GET |
|
| Upload zip file containing ML model artifacts to the inference server |
/endpoint/uploadmodel/ |
POST |
model_name – Unique name of the model to be uploaded file – Model artifact zip file |
| Remove an ML model from the inference server |
/endpoint/removemodel/ |
DELETE |
model_id – OCID of the ML model in Data Science |
| Infer upon an ML model to predict outcomes |
/endpoint/score/ |
POST |
model_id – OCID of the ML Model in Data Science data – Input data as expected by the ’Predict’ function of the ML model |
| Retrieve server instance information |
/endpoint/serverinfo/ |
GET |
|
| Get server health status |
/endpoint/healthcheck/ |
GET |
|
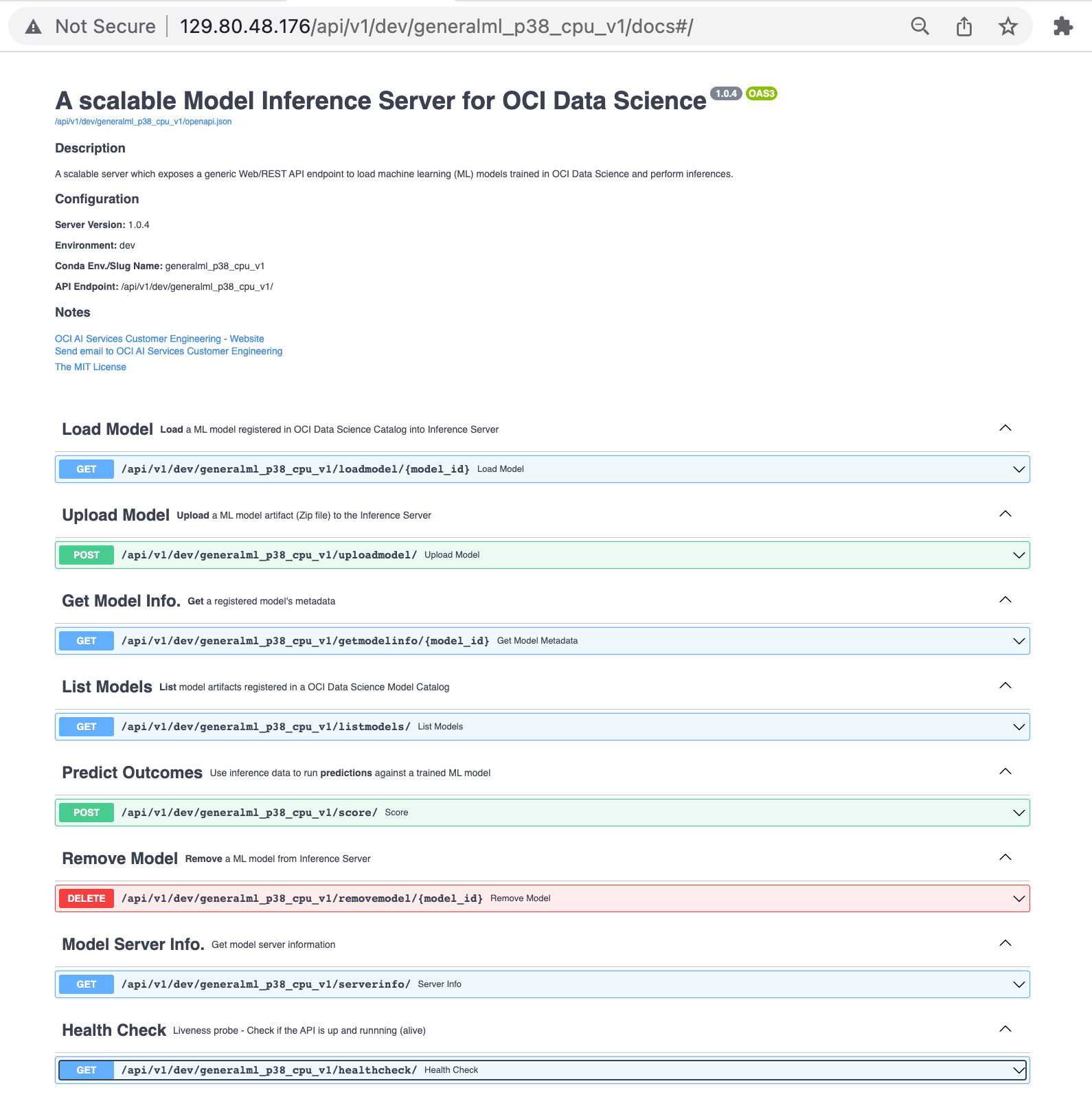
Sandbox environment
You can access a live environment running the reference architecture in A scalable Model Inference Server for OCI Data Science. The Conda environment deployed in this test inference server includes the Python ML libraries, such as scikit-Learn (v1.1.1), spacy (v3.3.1), xgboost (v1.5.0), and lightgbm (v3.3.0). This standard Conda environment available in OCI Data Science.
If you’re interested in testing you ML models in the sandbox environment, use the following steps:
-
Train an ML Model in OCI Data Science within your tenancy. Ensure that the model is trained using an algorithm included within the test Conda environment. The slug name for this test Conda environment is ’generalml_p38_cpu_v1.’
-
Register the model in the Model Catalog using the Oracle Accelerated Data Science toolkit. Then download the model artifacts to your local workstation by selecting the model download option in OCI Console.
-
Upload the model artifacts zip file to the inference server by invoking the ’/uploadmodel/’ endpoint. API endpoint descriptions are provided in the Invoking the ML Models section.
-
Run a few inferences by invoking the ’/score/’ endpoint. Verify the results.
See for yourself how easy it is to deploy and run inferencing on ML models within OCI using this model inference solution.
Multienvironment deployments
Today, IT organizations of all sizes use DevOps methodologies and best practices to deploy and promote web APIs across multiple environments. MLOps, a variation of DevOps, promotes the iterative model development approach where deployed models are frequently retrained with the latest data sets to continually help improve the accuracy of ML models.
In a typical MLOps workflow, when the ML models have been trained by data scientists in OCI Data Science, they’re deployed to a development region where business users validate the performance of the models with multiple data sets. These functional tests can also be automated and driven through separate DevOps integration pipelines.
When functional testing is complete, the models are promoted to a preproduction or QA region where the final QA is performed. In this region, you can also put the models through automated stress and volume tests. When all testing is completed and approved, the models are finally promoted to the production environment. This entire process repeats when a model’s accuracy drops and a new model needs to be trained with the latest data set.
You can easily emulate and automate iterative model development, testing, and deployment across multiple environments when using the model inference server, as depicted in the following architecture diagram.
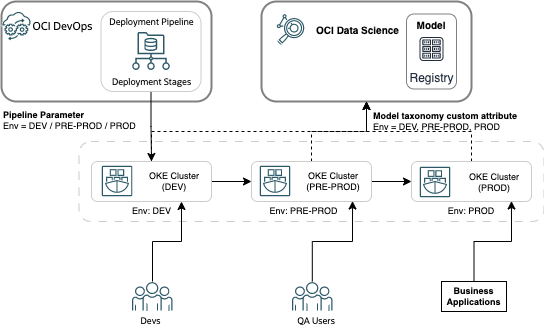
You can configure the DevOps deployment pipeline to deploy model inference server instances in each region by setting the pipeline parameter “env” value, such as when env is the same as dev. When the pipeline runs, this parameter and its value are injected as an environment variable into the inference server instances. At runtime, the inference server instance introspects the custom model attribute value stored in model metadata (Model catalog) against the env variable value and only allows inferencing when the values are identical.
By far the biggest benefit of this innovative MLOps based model deployment approach is that you can control model serving in any given environment by simply updating the model’s metadata (Custom attribute ‘env’ value) in OCI Data Science catalog. As such, there is no need to trigger or run a separate deployment or release pipeline in order to deploy the model in the target environment. This unique MLOps centric design and approach will be covered and explained at length in a subsequent blog in this series.
Conclusion
In this blog, we described how you can easily implement a highly available and scalable machine learning model inferencing Solution on OCI. In subsequent posts in this series, we describe how to extend this solution and implement reference architectures for external and edge based deployments. Stay tuned!
You can download all solution artifacts for the model inference server discussed in this blog from this GitHub repository. A step-by-step guide to configure and deploy the model inference server will be added to this Github repository soon.
If you have any feedback, questions, or suggestions to help improve this solution, submit them through the GitHub repo. We welcome all inputs and are happy to hear from you. We hope you can apply this reference architecture to scale ML workloads in one of your own customer engagements.
If you’re new to OCI, try Oracle Cloud Free Trial, a free 30-day trial with US$300 in credits. For more information, see the following resources:
