Feature stores are emerging as a fundamental component of machine learning (ML) platforms. As data-driven organizations increasingly incorporate AI into their operations, they are starting to centralize the management of features within a dedicated repository, known as a feature store. This specialized storage solution, often referred to as feature store service, tackles one of the most significant and complex challenges in the ML life cycle: dealing with data or, more specifically, the process of feature engineering.
Throughout the ML life cycle, features and models constitute the most precious assets generated, and a feature store essentially acts as a specialized data warehouse tailored for data science needs. Importantly, features differ from raw data. They’re derived from raw data and are crafted for predictive or causal analysis. The capacity to produce high-quality, predictive features is a distinguishing factor between a good and an exceptional data scientist.
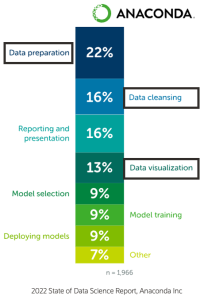
Crafting such potent features demands domain expertise related to the specific business problem at hand, experience, and a thorough comprehension of the constraints within the model production environment. Feature engineering, a resource-intensive process, greatly benefits from a cohesive framework where features are meticulously documented, shared, stored, and served in a streamlined manner. According to the 2022 State of data science report, Anaconda Inc about 51% of a data scientist’s time is spent in data-related tasks.
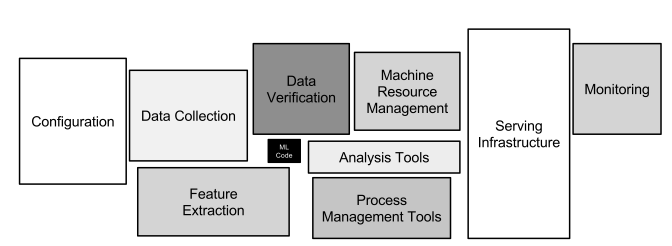
In this blog post, we detail the challenges data scientists face in feature engineering, such as inconsistency between training and serving features and redundancy in feature computation. We then introduce the OCI Data Science feature store as a centralized repository to manage, store, and serve features, ensuring consistency and saving computational resources. We illustrate how to get started on using the OCI Data Science feature by taking an example of the flights’ on-time performance dataset use case where feature stores have streamlined the feature engineering process and facilitated collaboration among data science teams. The post concludes by offering insights into best practices for setting up and managing a feature store, emphasizing the importance of versioning, monitoring, and establishing a feedback loop for continuous improvement.
Key Features of OCI Data Science Feature Store
OCI Data Science feature store is a one-stop shop for the entire life-cycle management of features with the following key benefits:
-
Centralized feature management: One of the most important advantages of a feature store is that it provides a centralized repository for features. In the world of Big Data, where data scientists and engineers are working with diverse, distributed datasets, having a single source of truth is essential. A feature store organizes features, ensures that they’re consistent, and makes them easily accessible to different teams and models.
-
Feature consistency and reproducibility: ML models are only as good as the data they’re trained on. Without a feature store, features can be inconsistently calculated, leading to inaccurate and unreliable models. Feature stores ensure that features are computed consistently and can be reused across different models, significantly improving the reproducibility of ML projects.
-
Real time and batch features: Modern ML applications often require features to be available in real-time. Feature stores enable seamless management and serving of both batch and real-time features, thus catering to a wide array of ML applications, from fraud detection to customer recommendations
-
Accelerating time to production: Feature stores significantly reduce the time needed to take a model from development to production. They allow for smooth and efficient collaboration between data scientists and engineers because the former can easily access the processed features they need, while the latter can focus on maintaining the data pipeline.
-
Reducing costs and improving resource efficiency: Feature duplication and redundant computation are major issues without a centralized feature store. By using a feature store, organizations can reduce storage and computation costs when features are computed once and reused instead of than recalculated for every new model.
-
Collaboration and governance: Feature stores encourage collaboration between teams by providing a shared, centralized repository of features. They also include tools for monitoring, validation, and version control, which are critical for governance and compliance requirements.
-
Programmatic and declarative programming support: The OCI Data Science feature store supports programmatic interfaces via SQL, Python, and Pyspark interfaces.
High Level Architecture
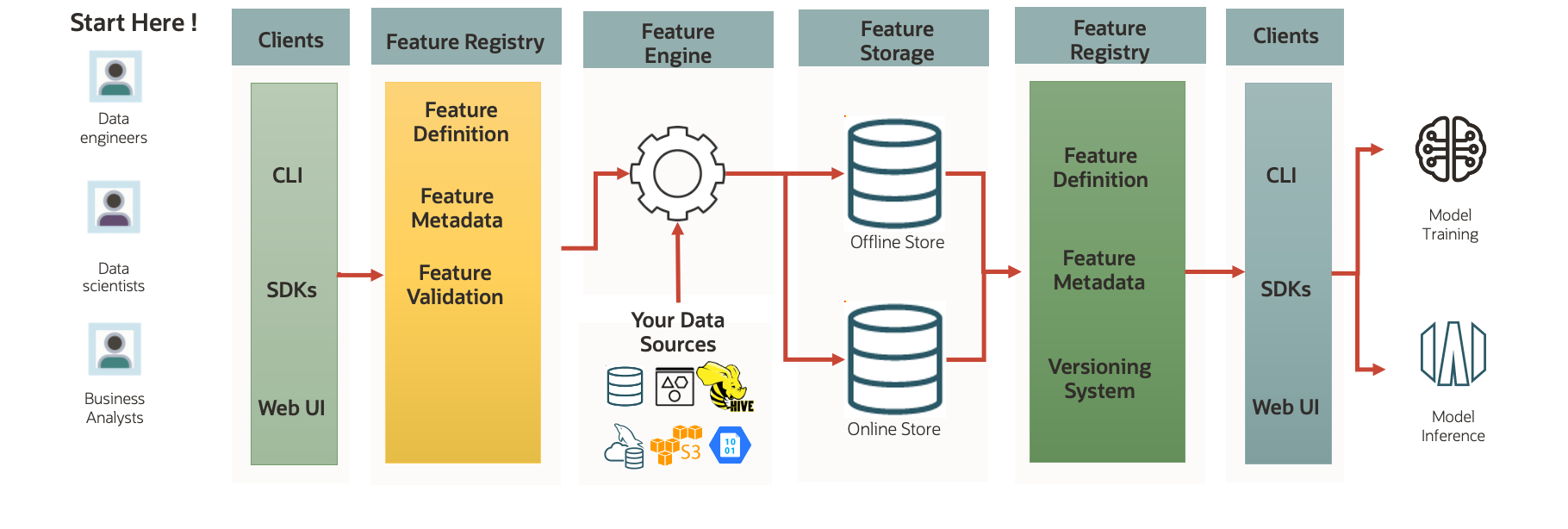
A feature store has different components, as shown in the above logical architecture diagram. The diagram also shows the following personas:
- Feature Creator or generator -This persona is typically responsible for defining, creating, and maintaining features in the feature store. Duties include ingesting raw data, performing transformations, and ensuring the resulting features are correctly saved and versioned in the feature store. Feature creators are usually data engineers, ML engineers, and sometimes data scientists with a strong background in data processing.
- Feature consumer – This persona is primarily concerned with using the features stored within the feature store for specific tasks like training ML models, running analytics, or performing inference. They rely on the feature store to provide consistent, high-quality, and up-to-date features. Feature consumers are often data scientists, ML researchers, or ML deployment engineers who need ready-to-use features for their models and applications.
Feature generators can create features through client interfaces, use of a feature engine, write the metadata and definition of features by using a feature registry, and store them depending on the latency and data refresh needs. At the same time, feature consumers can access different datasets that contain the curated features, build an ML model and deploy them to the target environments. Let’s expand on each of these components.
| Components | Description |
|---|---|
| Client interfaces |
Client interfaces such as software developer kits (SDKs), WebUI, and CLI. Users can extract the data from different data sources into the feature store using the client interfaces. Data connectors ingest customer data into a pandas or Spark data frame. |
| Feature registry | Acts as a metadata repository that stores features’ definitions, metadata, and computation logic. It allows users to discover, document, and share features across teams and enables the versioning of feature definitions. |
| Feature engine | A feature engine within the context of a feature store that refers to the set of tools, processes, and frameworks designed to facilitate feature extraction, transformation, and creation. Essentially the backbone that powers the generation and management of features used in ML workflows |
| Feature storage |
In the context of a feature store, feature storage refers to the underlying infrastructure, mechanisms, and protocols used to persistently save and manage ML features, both in their raw and processed forms. This storage is essential for ensuring consistent and rapid access to features for training and inference. There are two-tiered storage options: offline storage and online storage. We have offline storage capabilities where features and the associated metadata are stored, powered by OCI Object Storage. |
| Feature registry |
A feature registry in a feature store is akin to a catalog or a metadata repository that manages and keeps track of the various features created and stored. It provides an organized, centralized system to monitor, discover, and manage features, ensuring that data scientists and ML engineers can efficiently utilize them across different projects. |
Getting started with the OCI Data Science feature store
Maintaining feature consistency becomes paramount as ML projects grow in complexity and scale. For newcomers and seasoned professionals alike, understanding the intricacies of a feature store can be a game-changer. In this section, we offer a step-by-step walkthrough to get started with the OCI Data Science feature store. We take a flight on-time performance dataset, create a feature store instance, create entities, perform transformation on the targeted features, create feature groups and datasets, and use the feature consumer persona to select a query to extract the dataset into a ML model. Let’s look into the each of these steps in detail.
Prerequisities
Before getting started, we must set policies and authentication methods. You can check the following documentation here on setting the following requisites:
About the Dataset
We take the dataset from the US Department of Transportation’s (DOT) Bureau of Transportation Statistics, which tracks the on-time performance of domestic flights operated by large air carriers.
First, we load the flight dataset into a pandas data frame.
import pandas as pd
flights_df = pd.read_csv("https://objectstorage.us-ashburn-1.oraclecloud.com/p/Me1__H7-qfH6O9teiML2i2ZyG4ELtNGBKvbeBGerbr0fZ-zLlhR54eUL-YALcFcA/n/idogsu2ylimg/b/FeatureStore/o/flights_flights.csv") |

Setting up the Feature Store
Authentication
The Oracle Accelerated Data Science SDK (ADS) controls the authentication mechanism with the notebook cluster.
To set up authentication, use the command, ads.set_auth("resource_principal") or ads.set_auth("api_key")
import ads
ads.set_auth(auth="resource_principal", client_kwargs={"service_endpoint": "<feature-store-service-endpoint>"})
|
Refer to the authentication policies section in the Quickstart section of the feature store documentation.
To create and run a feature store, we need to specify <compartment_id> and <metastore_id> for offline feature store.
import os compartment_id = "<compartment_id>" metastore_id = "<metastore_id>" |
Step 1 – Creating the feature store
The first part of the scenario consists of creating a feature store instance. The feature store is the top-level entity for the feature store service. Run the following command:
feature_store_resource = (
FeatureStore().
with_description("Data consisting of flights").
with_compartment_id(compartment_id).
with_display_name("flights details").
with_offline_config(metastore_id=metastore_id)
)
# Call the .create() method of the Feature store instance to create a feature store.
feature_store = feature_store_resource.create()
feature_store |
Step 2 – Creating entities
An entity is a group of semantically related features. To create entities, use the following command:
entity = feature_store.create_entity(
display_name="flight_details_entity",
description="description for flight details"
)
entity |
Step 3 – Creating transformations
Transformations in a feature store refer to the operations and processes applied to raw data to create, modify or derive new features that can be used as inputs for ML models.
The following Python function defines 2 pandas transformations used for feature engineering. impute_columns replaces missing Nan with the mode value for the column and transform_flight_df which selects specific columns from the imputed dataframe.
def transform_flight_df(df, **transformation_args):
def impute_columns(flights_df, **transformation_args):
result_df = flights_df.copy()
column_labels = transformation_args.get("imputation_column_labels")
if isinstance(column_labels, list):
for col in column_labels:
result_df[col] = result_df[col].fillna(result_df[col].mode().iloc[0])
elif isinstance(column_labels, str):
result_df[column_labels] = result_df[column_labels].fillna(
result_df[column_labels].mode().iloc[0]
)
return result_df selected_columns = transformation_args.get("selected_columns")
import pandas as pd
# impute columns in the dataframe
imputed_df = impute_columns(df, **transformation_args)
date_strings = df.apply(
lambda row: f"{row['Year']}-{row['Month']}-{row['DayofMonth']}", axis=1
)
imputed_df["date"] = pd.to_datetime(date_strings)
resulted_df = imputed_df[selected_columns] if selected_columns else imputed_df
return resulted_df |
from ads.feature_store.transformation import TransformationMode
flight_transformation = feature_store.create_transformation(
transformation_mode=TransformationMode.PANDAS,
source_code_func=transform_flight_df,
display_name="transform_flight_df",
)
|
Step 4 – Creating feature groups
A feature group is an object that represents a logical group of time-series feature data as it is found in a datasource. Run the command:
transformation_arg = {
"imputation_column_labels": ["CancellationCode", "CarrierDelay"],
"selected_columns": [
"CancellationCode",
"CarrierDelay",
"date",
"DepTime",
"FlightNum",
"TailNum",
"ActualElapsedTime",
"CRSElapsedTime",
"AirTime",
"ArrDelay",
"DepDelay",
"Origin",
"Dest",
"Distance",
"TaxiIn",
"TaxiOut",
],
}
feature_group_flights = (
FeatureGroup()
.with_feature_store_id(feature_store.id)
.with_primary_keys([])
.with_name("flights_feature_group")
.with_entity_id(entity.id)
.with_compartment_id(compartment_id)
.with_schema_details_from_dataframe(flights_df)
.with_transformation_id(flight_transformation.id)
.with_transformation_kwargs(transformation_args)
)
feature_group_flights.create() |
The “.show” function shows the feature group after creation.
feature_group_flights.show() |
This method doesn’t persist any metadata or feature data in the feature store on its own. To persist the feature group and save feature data along the metadata in the feature store, call the materialise() method with a DataFrame with the following command:
feature_group_flights.materialise(flights_df) |
Step 5 – Querying a feature group
We can call the select() method of the FeatureGroup instance to return Query interface. We can use the Query interface can be used to join and filter the feature group.
# Select all columns of feature group
flights_query = feature_group_flights.select()
# Select subset columns of feature group
flights_query = feature_group_flights.select(
[
"date",
"DepTime",
"FlightNum",
"TailNum",
"ActualElapsedTime",
"CRSElapsedTime",
"AirTime",
"ArrDelay",
"DepDelay",
"Origin",
"Dest",
"Distance",
]
)
# Filter feature groups
feature_group_flights.filter(feature_group_flights.Origin == "MDW").show() |
Step 6 – Creating datasets
A dataset is a collection of features used to train a model or perform model inference. In an ADS feature store module, you can either use the Python API or YAML to define a dataset. With the following medthod, you can define a dataset and give it a name.
dataset = (
Dataset()
.with_description("Combined dataset for flights")
.with_compartment_id(compartment_id)
.with_name("flights_dataset")
.with_entity_id(entity.id)
.with_feature_store_id(feature_store.id)
.with_query(flights_query.to_string())
) |
By calling the .create method, we would create the flights dataset.
dataset.create() dataset.materialise() |
We can use these datasets to train ML models.
SQL queries
We can call the sql() method of the FeatureStore instance to query a feature store.
# Fetch the entity id. Entity id is used as database name in feature store
entity_id = entity.id
# Form a query with entity id and fetch the results
sql = f"SELECT flights_dataset.* from `{entity_id}`.flights_dataset flights_dataset"
# Run the sql query and fetch the results as data-frame
df = feature_store.sql(sql) |
Using the selected dataset from the feature store, we can now train an ML model to capture patterns and insights, ensuring consistent, high-quality features that can drive the model’s predictive accuracy. In subsequent blogs, we showcase how you can use datasets to train ML models and store the models in the model catalog.
Other key functionalities
We covered how to set up a feature store instance, create entities, create transformations, feature groups, and datasets. But the features and functionalities that the OCI Data Science feature store don’t just end there. We have the followingother key features:
- Validating features using Great Expectations: Great Expectations is an open source Python tool used for data validation, profiling, and documentation. Integrating it into the OCI Data Science feature store allows you to define expectations or assertions about their feature data, ensuring that it meets specific quality benchmarks.
- Lineage: Lineage provides a visual and traceable path of a feature’s journey from its raw data sources, through various transformations, to its final form in the feature store.
- Validation output: Validation is the process of checking the output features after transformations to ensure that they meet predefined criteria or constraints.
- Feature statistics: With a quick overview of these statistics, you can gain insights into feature distributions, identify potential outliers or anomalies, and make informed decisions about feature utility and preprocessing needs.
- Visualizing through the Jupyter notebook extension: Many data scientists and ML practitioners use Jupyter notebooks for their workflows. This seamless integration means that you can fetch, visualize, and analyze features directly within your familiar notebook interface, speeding up exploratory data analysis, model training, and evaluation.
Conclusion
The world of data science and machine learning is complex, with various components working in tandem to produce actionable insights. At the heart of this ecosystem lies the concept of a feature store. Feature stores serve as centralized repositories for features meticulously crafted from raw data to be used in machine learning models. They aim to streamline the workflow of data scientists by ensuring that features are consistent, easily accessible, and primed for both real-time and batch processing.
In this blog, we covered some of the concepts related to feature stores, such as entities, feature groups, datasets, and creating datasets that are reusable in ML models. In this process, we created the fundamental building blocks of an OCI Data Science feature store.
In summary, a feature store isn’t merely a data repository, but a sophisticated platform that bridges the gap between raw data and insightful machine learning models. Feature stores are shaping the future of how data science operations are conducted by emphasizing organization, validation, transparency, and visualization, offering a blend of efficiency and assurance.
To get started on the feature store, you can try the sample notebooks or watch the demos.
Try Oracle Cloud Free Trial for yourself! A 30-day trial with US$300 in free credits gives you access to OCI Data Science service. For more information, see the following resources:
- Feature Store Documentation
- Full sample including all files in OCI Data Science sample repository on Github.
- Visit our OCI Data Science service documentation.
- Read about OCI Data Science Feature Store
- Configure your OCI tenancy with these setup instructions and start using OCI Data Science.
- Star and clone our new GitHub repo! We included notebook tutorials and code samples.
- Watch our tutorials on our YouTube playlist
- Try one of our LiveLabs. Search for “data science.”


