The 80/20 rule or Medical Loss Ratio rule for health insurance requires 80% of the premium money to be spent on improving healthcare costs and quality improvement initiatives. However, about 80% of these reimbursements are spent on 20% of the insured members. One of the primary factors is patient readmission events. A readmission event occurs when a patient is admitted within a specific period, 30 or 90 days, following the previous hospital visit.
The number of readmission events is a metric for the US healthcare system, and avoidable readmission events cost $41.3B per year. Typically, health insurance companies employ specialized nurses who contact patients admitted to a hospital to ensure that proper treatment with appropriate triage is administered after they’re discharged.
The US Center for Medicare and Medicaid Services (CMS) provides a STARs rating to score hospital quality. It summarizes key measures across the following areas:
-
Patient mortality
-
Patient safety of care
-
Patient readmission
-
Patient experience
-
Patient timely and effective care by a provider
Prediction models around these area, especially patient readmission, help health insurance companies utilize nurse resources to target members with a high readmission risk, reducing medical costs. These models include the following examples:
-
Advise finance group on patient readmission risk based on hospital admittance and patient health history
-
Advise hospital staff on patient care needs based on patient vitals during admittance
-
Advise home care workers on patient vitals collected by wearables after discharge
In this blog post, we discuss the predictive aspects of patient readmission design around the second use case with Oracle Cloud Infrastructure (OCI). For another use case, see the previous installment of this series.
Use case
This solution addresses a scenario with the following attributes:
-
Patient vitals and readmissions data are collected for all patients and logged in the electronic health record (EHR) system.
-
Nurses must recognize the likelihood of patient readmission in advance to alert the hospital before the event occurs.
-
Nurses must provide quality care and minimize the risk of injury and illness.
-
Finance operations must see an optimized staffing plan to best select and distribute resources to help patients.
-
Discovery of any extra measures that work best for hospitals and patients
Architecture and workflow
In this architecture, Oracle Accelerated Data Science (ADS) and OCI Data Science AutoML rapidly deployd a machine learning (ML) model. The architecture consists of the following workflows:
-
Training workflow, where an ML model is trained using patient historic data
-
Inference workflow, where inferences are made on incoming production data
The following diagram shows a schematic of the overall workflow with the OCI Data Science platform:
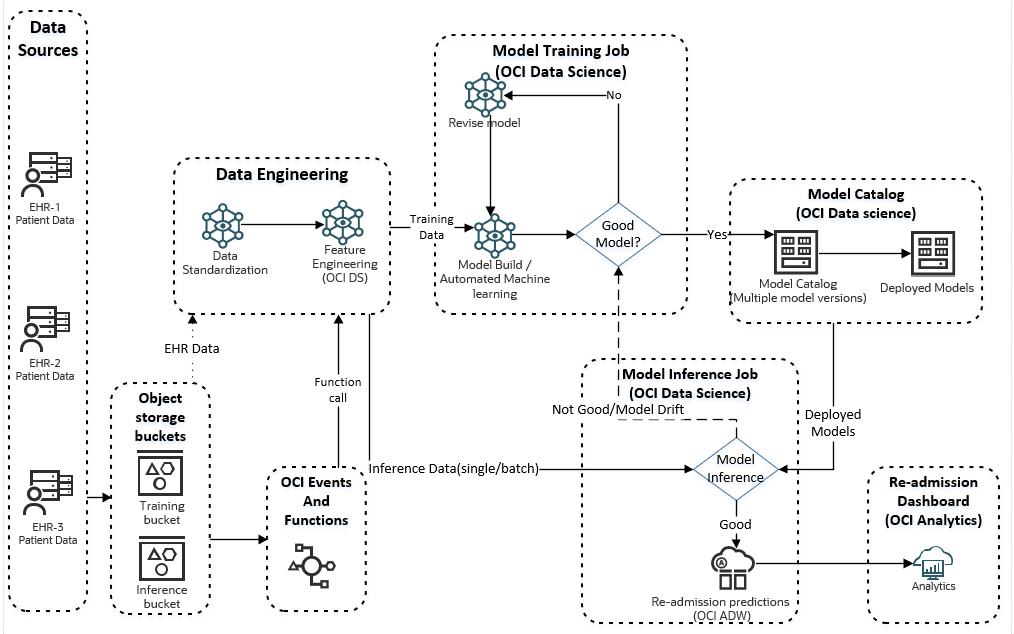
Training data
-
Synthetic patient datasets, such as Synthea, were used to generate patient longitudinal records, such as patient encounters, conditions, allergies, medications, vaccinations, observations and vitals, labs, procedures, and care plans.
-
Dataset generation was randomized based on population size, state, city, and so on.
-
A target column “readmission_flg” is identified for prediction using binary classification.
-
Data scientists manually analyze the raw training data for basic and advanced statistical analysis tools.
-
Relevant columns or features are automatically analyzed with Oracle ADS library and data grain at set at patient level. This process involves preparing the right grain of patient data for downstream predictive analysis and filtering the relevant features, such as the patient’s age, gender, and readmission status, automatically based on statistical analysis.
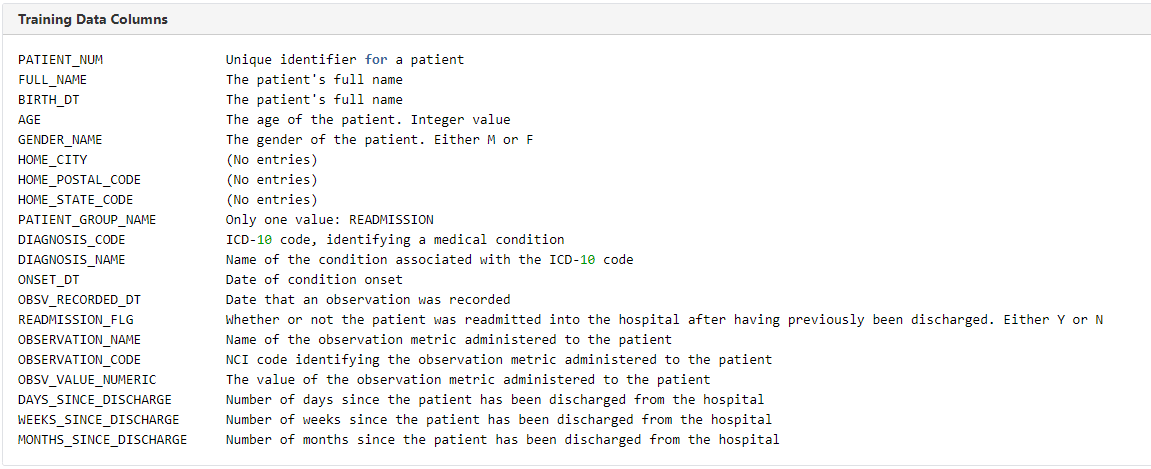
An example of the raw dataset metadata and key statistics, including mean, standard deviation, percentiles, and missing values, using show_in_notebook() in Oracle ADS provides suitability through manual introspection of the data for training purposes.
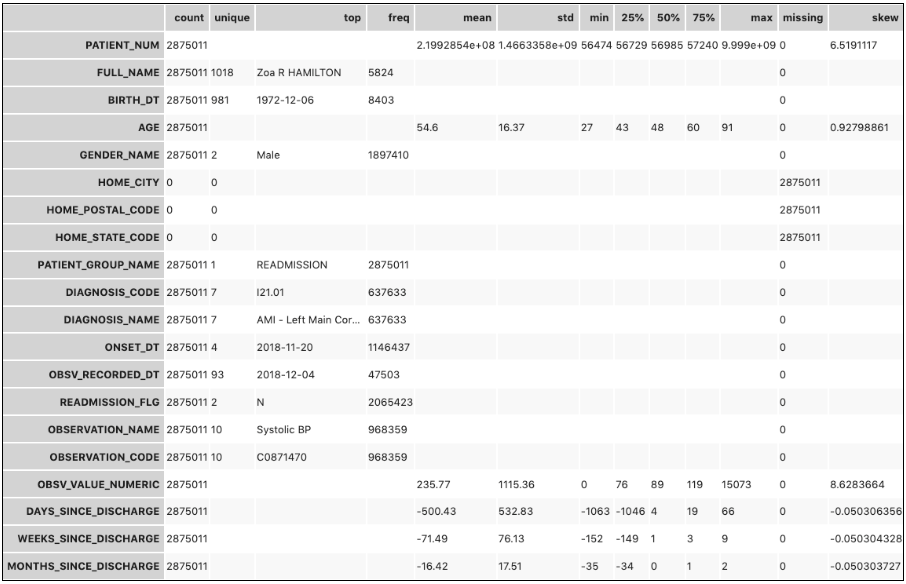
For rapid implementation purposes only, the observation values to their min, max, mean, and standard deviation are collapsed for each respective patient to transform the grain of training data to the patient level. Manual introspection of the data and statistical observations though Oracle ADS’s feature engineering can provide a way to accomplish this task.
Training process
The model training process is effective if it produces expected accurate predictions on the test or inference data. Because patient readmission scenarios are unique to each EHR and hospitals, a model trained in a particular dataset might not always perform at the expected level during inference. So, it requires the following factors:
-
Identification of an appropriate algorithm and hyperparameters that works best for a particular dataset
-
An efficient model training process that bypasses the models and hyperparameters that don’t result in improving the inference accuracy
-
The AutoMLx and ADSTuner features of Oracle ADS library
AutoML evaluates the algorithm by comparing model performance indicators across models trained using a different algorithm. Data scientists and healthcare SMEs can manually finetune models, but this step isn’t included in the automated workflow.
The trained model is then saved into the OCI Data Science Model Catalog for inference consumption. For the training runs, AutoML determined that random-forest algorithm is best suited and yields the highest model performance for the training dataset.
Training workflow
The objective of creating a training workflow is to train, retrain, and improve patient readmission models in automation with varied datasets. The process enables the following events:
-
Loading training data in a designated OCI Object Storage bucket
-
Configuring the Oracle Event Hub to capture file data drops and trigger running a function. This process is implemented using an OCI Events rule, checking for OBJECT_CREATE and OBJECT_UPDATE events, which triggers an OCI function containing a Python script calling a Data Science job.
-
Configuring a Data Science job that can be called from the function.
-
The Data Science job calls model training, tuning, and cataloging in a workflow and storing the optimized model in the model catalog.
Although you can automate a training workflow for OCI Data Science jobs and pipelines with OCI Events and functions, the framework provides a common and popular implementation method.
Another popular method of automating training datasets is following a container-based approach and cataloging them in Oracle Container Registry. We recommend this approach when you want to integrate your own custom containers or publicly available containers to your data science workflow or implement at-scale model training and inferencing in a multicloud scenario.
OCI Autonomous Database acts as storage for model catalog and versions where you can integrate them to expose them through any analytic tools, such as Oracle Analytics Cloud (OAC).
Inference workflow
Inference data
The raw inference data contains the featured columns but not the predicted column, readmission_flag. We’re working to predict this column. The following factors influence the inference data:
-
We want to reshape the inference data to extract the feature column set of interest. So, the same feature extraction logic-like training is applied.
-
Data can be a single record JSON file or multiple records in a CSV format.
-
API-based inference is performed on single records while batch inferencing is performed for multirecord batches.
-
The output data from the model inference is aggregated in the Autonomous Database table for consolidation and historical reporting.
Inference workflow
The inference workflow shows how patient readmission is predicted for single or batch records in automation using deployed models in OCI Data Science, using the following key steps:
-
An OCI event triggers when patient EHR inference data lands in the Object Storage inference bucket.
-
The event triggers a function call containing a Python script based on OBJECT_CREATE and OBJECT_UPDATE events in the bucket.
-
The Python script makes an API call to run an inference Data Science job.
-
The Data Science job consists of a Python script that performs the inference workflow, standardizes it, and prepares it by extracting the relevant patient features for model inference.
-
The prepared inference dataset passes to the model deployment endpoint, generating the predictions for whether a patient is a likely candidate for readmission.
-
Inference triggers with the best and updated deployed model in the model catalog.
-
The selected model is automatically deployed if not already deployed in the catalog. You can deploy models in ADS or industry-standard ONNX formats, as specified in deployment specification.
-
The model infrastructure is designed for an optimal scale and can be automatically decommissioned and recommissioned with a Data Science API to minimize idle runs and cost.
-
The model inference outcome (Predicted patient readmission flag) is stored with the patient information in an Autonomous Data Warehouse database.
-
The inference output is then consumed by the Oracle Analytics dashboard directly from the Autonomous Data Warehouse database.
-
Automation is built into Oracle analytics to automatically query inferences, giving results on an hourly basis.
-
If the model inference accuracy falls below the defined threshold or drifts detected, model is marked for retraining with new data.
-
Because this use case has higher data sensitivity, you can automate the process with infrequent manual updates based on drifts and threshold.
Setup and key components
The setup for this process is minimal, and OCI provides an easy way to do it. The setup process involves the following key steps:
-
Two separate Object Storage buckets for landing training data and inference data
-
An OCI Event rule that checks for OBJECT_CREATE and OBJECT_UPDATE events in the training or inference bucket as the rule’s condition to trigger a predefined function
-
Separate OCI Event rules built for training and inference buckets
-
An OCI function configured to create a Data Science job or pipeline through API calls
-
A Data Science Python script containing AutoML-based model training and cataloging in Model Catalog.
-
A Data Science Python script model inferencing and cataloging in Model Catalog
-
A Data Science notebook session to use as a workbench for developing Python artifacts, configured to jumpstart the data engineering capabilities. You have the following options:
-
A Python notebook to normalize EHR data and perform missing value imputations and other standardizations.
-
A fully custom script, which requires knowledge of various datasets
-
Standardized HL7/FHIR script
-
-
Autonomous Data Warehouse to store the latest and historical versions of Data Science Model Catalog entries
-
An OAC set up for visualizing the predictions
Visualizing the results
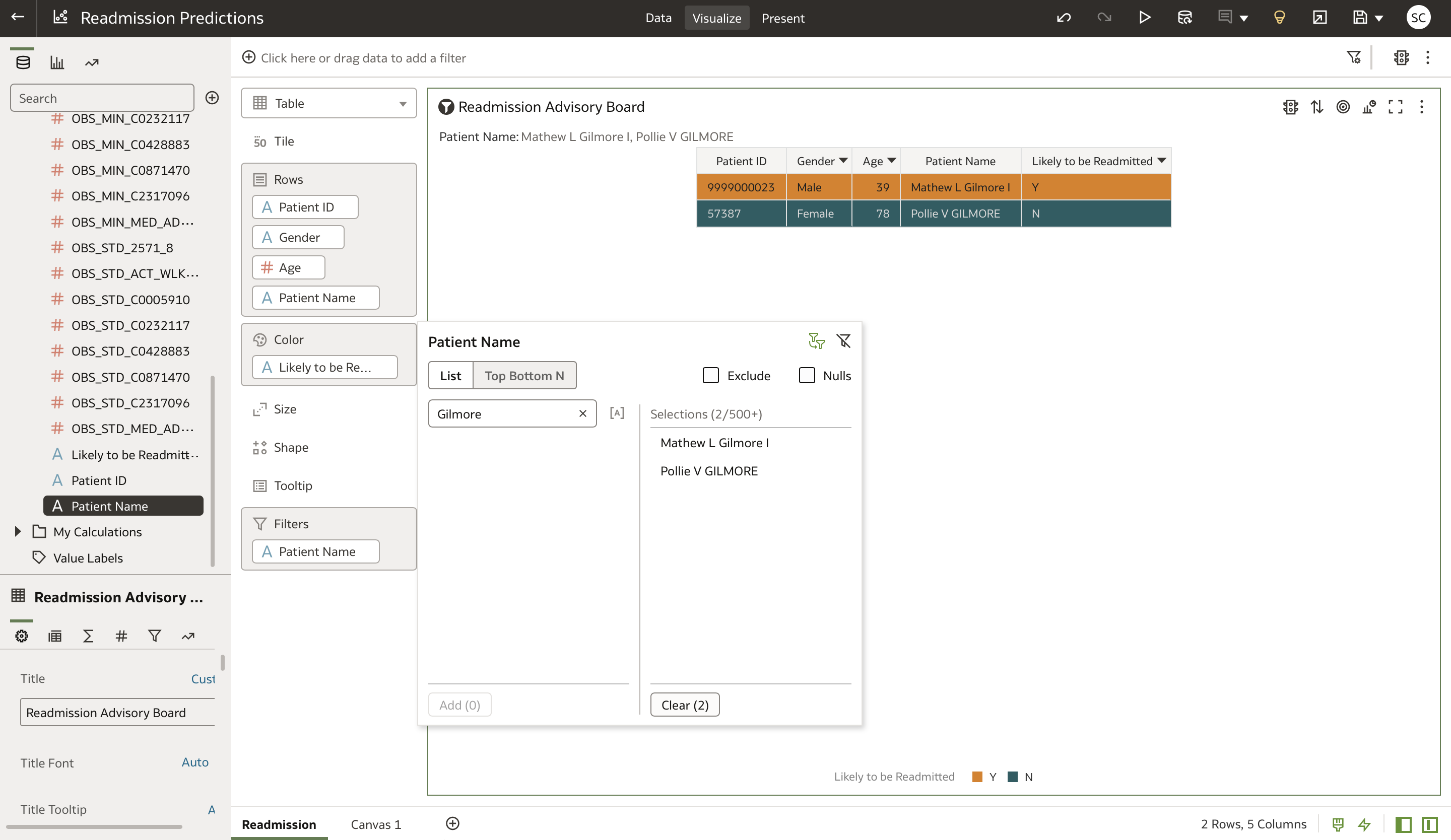
OAC provides an automated way to show the predicted patient readmission outcomes, refreshed on a scheduled or on-demand basis. You can configure it to refresh the dashboard with new predictions as they’re uploaded to Autonomous Database. This configuration allows for hospital nurses and finance administrative personnel to apply relevant filters by patients name or ID and preemptively advise on the readmission risk for a patient.
For example, in the followingvisualization, each row in the workbook represents a patient, who can be sorted by “Likely to be Readmitted” with “Y” appearing at the top. This filtering enables us to triage higher-risk patients appropriately. Combining this data model with other patient attributes, we can develope summarized or drill-down reports, analytics dashboards, and visualizations to see trends, finetune or decipher hidden causes, or relate to any readmission reduction actions taken.
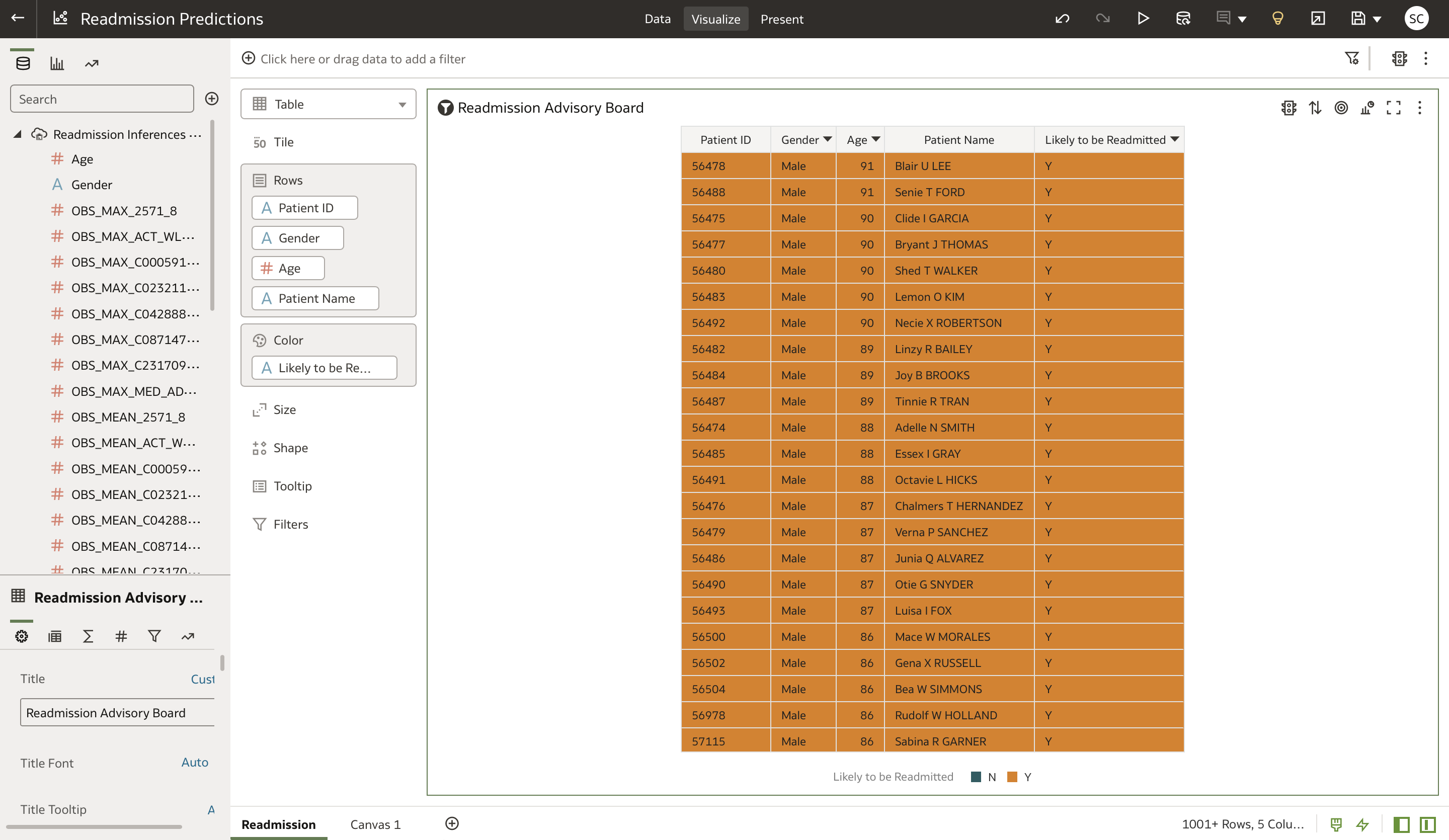
In this view, if you want to view the prediction status of a patient, you can filter the table by dragging the “Patient Name” feature into the “Filters” field.
Conclusion
This blog post provides you with a quick, easy way to set up patient readmission predictions from EHR data sources, process predictions in automation, and visualize data to analyze in an analytics dashboard, all within OCI. You can extend the solution in the following ways:
-
Include multiple EHR data sources from multiple providers
-
Implement and augment the EHR data standardization processes with standardized formats like HL7 and FHIR
-
Implement standard Python-based open source ONNX model deployments that can operate in a multicloud enterprise deployment
-
Implement easily by splitting the training and inference architecture components between on-premises and OCI or OCI and another cloud
-
Improve integrated model inferencing and training performance through automated drift detection and improvement
-
Improve models and build ensemble models by retraining and inferencing on varied EHR datasets
-
Bring value to your OAC or other analytics dashboards by integrating with the predictive readmission data seamlessly
-
Extend the infrastructure to your enterprise data platform across on-premises, OCI, and other clouds
-
Use OCI open source data science tools to publish and collaborate across larger open source data science and healthcare communities
For questions or to discuss your specific use case, contact the Oracle Cloud Infrastructure Data Platform Solutions team. To learn more, see the following resources:
-
Read the Data Science documentation.
-
Configure your OCI tenancy with these setup instructions and start using OCI Data Science.
-
Star and clone our new GitHub repo! We included notebook tutorials and code samples.
-
Subscribe to our Twitter feed.
-
Try one of our LiveLabs. Search for “data science.”
-
Join the AI and Data Science public Slack channel.
-
Contact us directly for preview access to new features.