Accessibility Policy
Skip to content
Oracle
Oracle NoSQL Database
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Oracle AI
Technical Solutions
Blogs Home
RSS
Oracle NoSQL Database
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
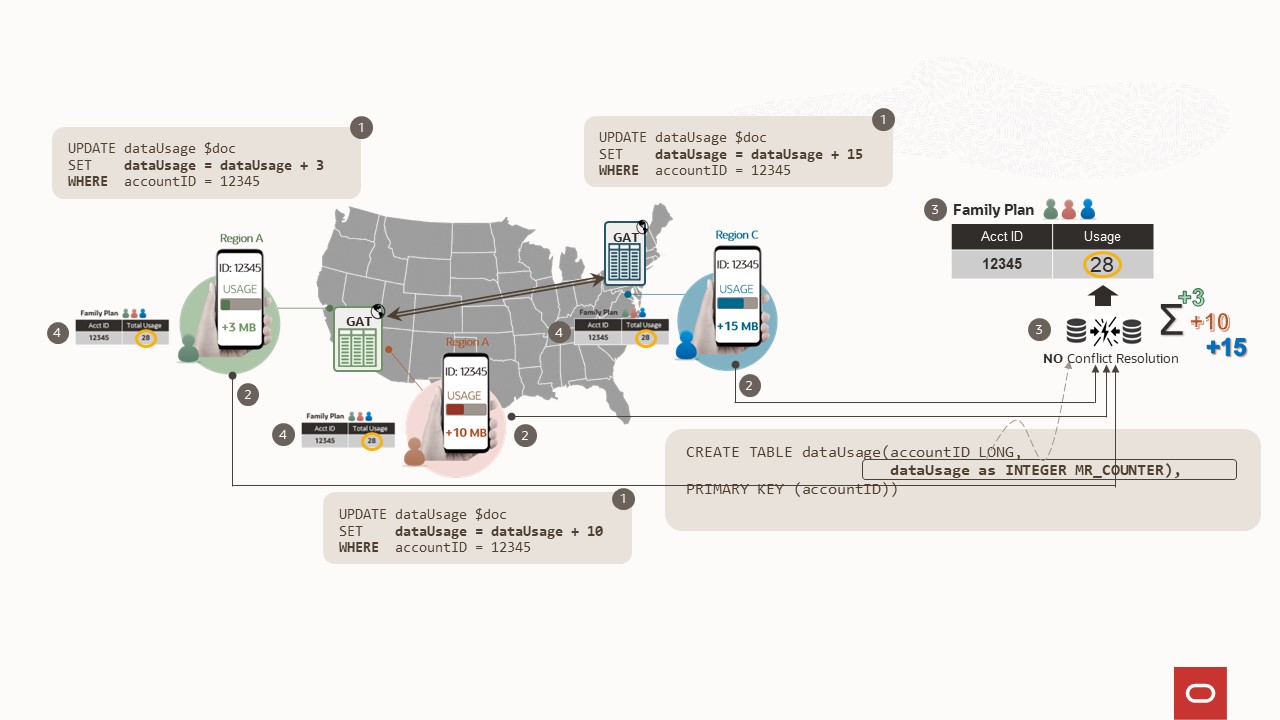
Global Active Tables – Instant Agility
Tim Goh
8 minute read
Global Active Tables – Simplicity Hides Complexity
Tim Goh
10 minute read
Global Active Tables and Conflict Free Replicated Data Type (CRDT)
Dario VEGA
5 minute read
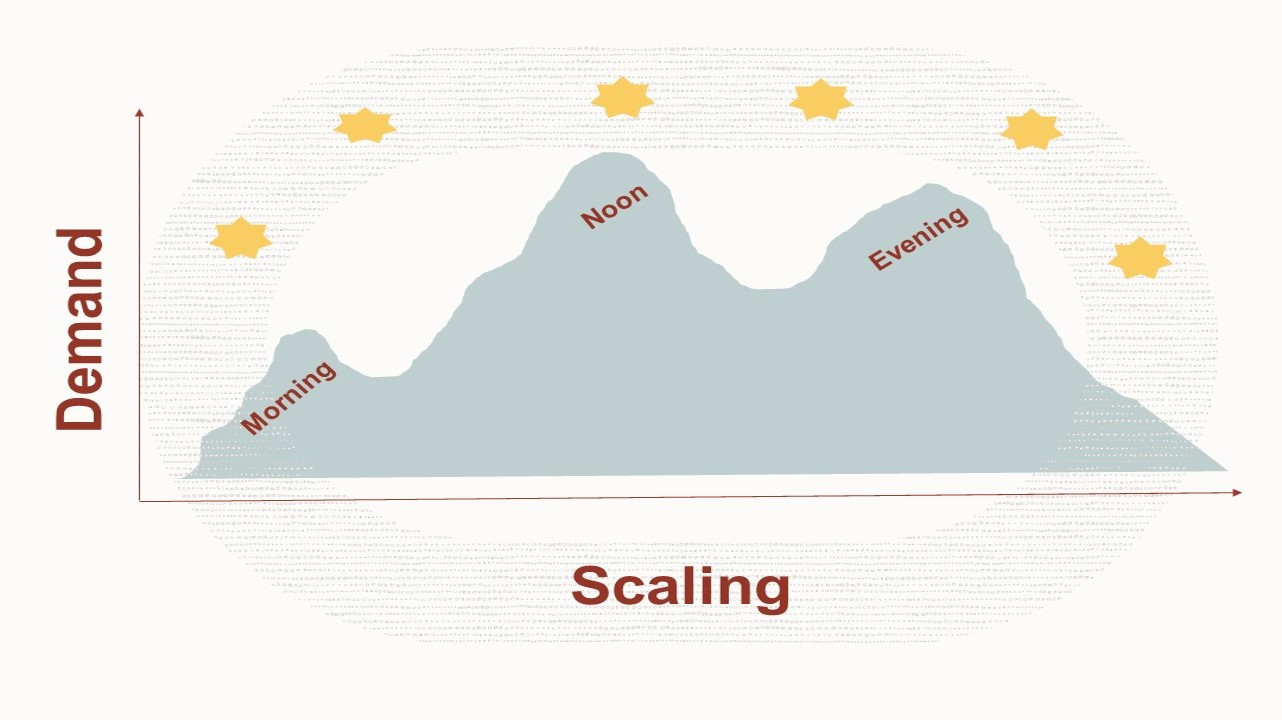
New Feature Announcement: On-Demand Capacity
Tim Goh
Michael Brey
7 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Recent Posts
Oracle NoSQL Database 25.1 Release
Tim Goh
6 minute read
Oracle NoSQL Database Cloud Service – 10 Minutes to Hello World ...
Dario VEGA
7 minute read
Oracle NoSQL Global Active Tables delivers extreme performance for ...
Kiran Makarla
4 minute read
New Feature Announcement: Dedicated Hosted Environments
Dario VEGA
2 minute read
Table Hierarchy: The Hidden Gem of Oracle NoSQL Database
Tim Goh
15 minute read
Oracle CloudWorld 2024 – Embark on a Transformative Journey ...
Tim Goh
3 minute read
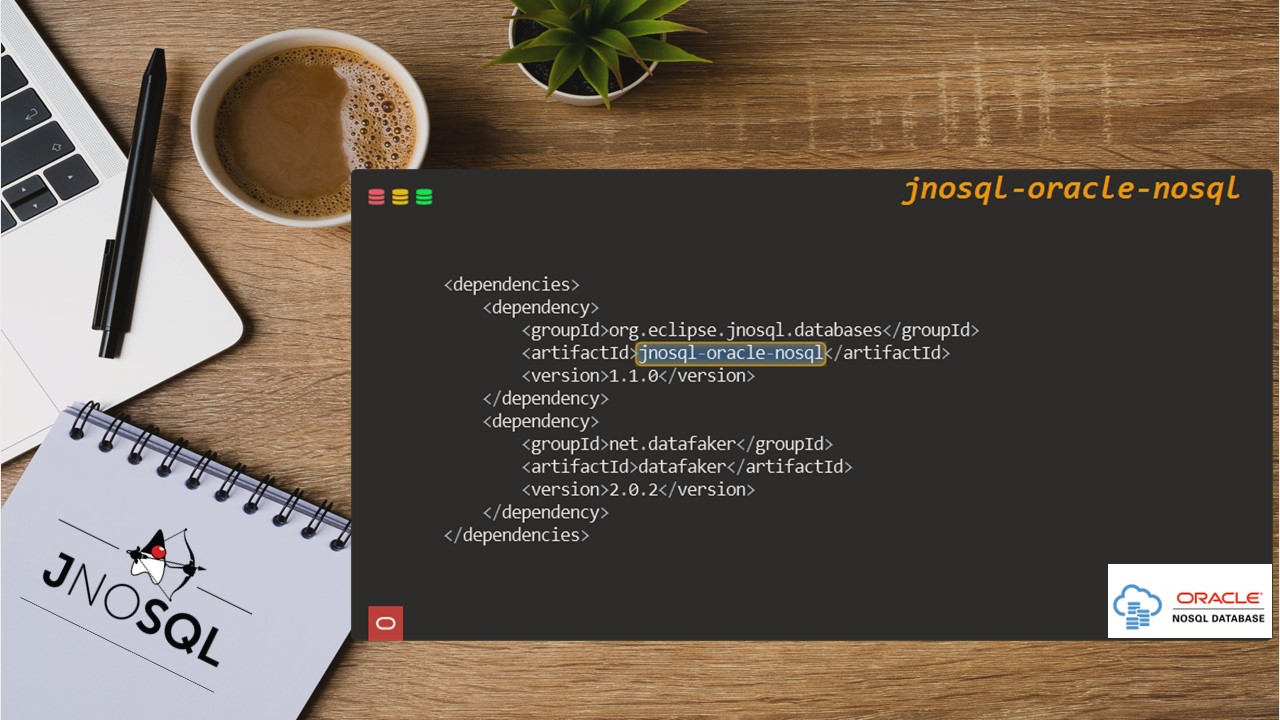
Getting Started – Accessing Oracle NoSQL Database using Jakarta ...
Dario VEGA
10 minute read
Hardware Strategies for Horizontal and Vertical Scalability for ...
Tim Goh
5 minute read
Oracle NoSQL Database 23.3 Release
Dario VEGA
3 minute read
Migrate MongoDB data to Oracle NoSQL Database
Tim Goh
13 minute read
3 Simple steps to build secure, scalable applications using NoSQL ...
Kiran Makarla
4 minute read
Data Management for Always-ON Apps : Must see NoSQL sessions at ...
Kiran Makarla
2 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers