Many organizations are required to retain backups for years based on end-of-month, end-of-quarter, or end-of-year operations. For databases using Autonomous Recovery Service, these compliance backups are now available with a simple click of the “Create” backup button as shown in Figure 1. This long-term backup retention operation is offloaded onto the Autonomous Recovery Service, eliminating the use of production database resources and the database costs incurred with traditional full backups. Let Autonomous Recovery Service do all the work for you.
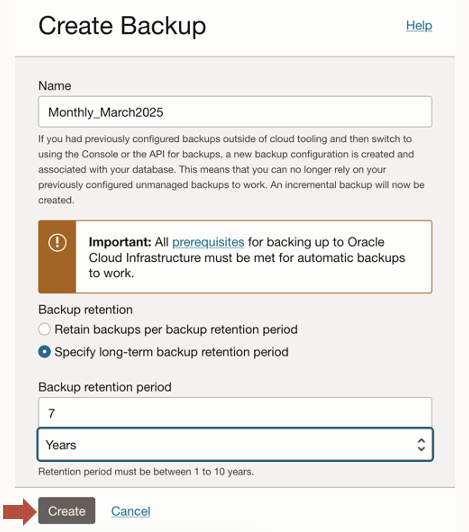
Figure 1 – Backup creation dialog with name “Monthly_March2025”, long-term backup option selected, and backup retention period of 7 years
How long term retention works
With a single click of the “Create” backup button, Autonomous Recovery Service will use its existing operational backups to create a new long-term backup that can be retained for up to 10 years. By using existing backups, you don’t need to worry about finding a window when your database can perform an additional full backup just for long-term retention. Autonomous Recovery Service will do all the work required to create the backup and manage the entire retention lifecycle.
After the long-term backup is completed, it will appear in the database’s backup history with the specified name and expiration information for the retention period you provided, as shown below in Figure 2.

Figure 2 – Database management console showing backup history, including a long-term backup expiring in March 2032 (based on 7 year retention period in backup creation in Figure 1 above)
This newly created long-term backup is stored in the lower-cost, infrequent-access tier of OCI Object Storage and fully managed by the Autonomous Recovery Service, as shown below in Figure 3.
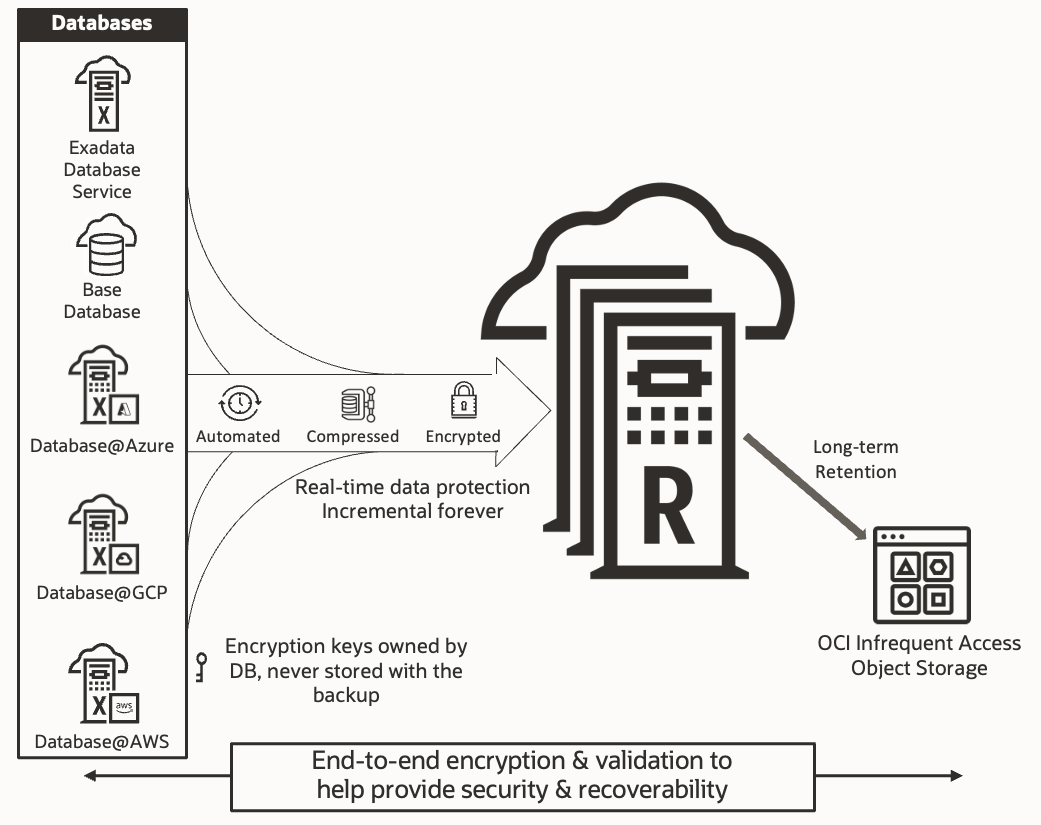
Figure 3 – Backup workflow diagram for Autonomous Recovery Service
The following operations are also available for long-term backup management:
- Change long-term backup retention period – Extend or reduce the retention of a long-term backup as needed.
- Create a new database using a long-term backup – Provision a new database instance for data auditing and analysis.
- Delete the long-term backup – Reclaim storage space by deleting any long-term backups that are no longer needed.
Refer to the Oracle Database Service documentation links below for additional information on all available operations.
Autonomous Recovery Service is the best option for Oracle Database Cloud Services
As Oracle’s strategic cloud database protection solution, Autonomous Recovery Service now offers easy on-demand creation of long-term backups with user-defined retention of up to 10 years. It offers unique capabilities not found in object storage backups or other solutions in the market, such as:
- Zero data loss recovery
- Fast, low-overhead incremental-forever backups
- Continuous anomaly detection and recovery validation
- Database-integrated insights into your Oracle protection status.
Long-term retention is available today for any Oracle Base Database, Oracle Exadata Database Service on Dedicated Infrastructure, or Oracle Exadata Database Service on Exascale Infrastructure protected by Autonomous Recovery Service in Oracle Cloud Infrastructure, Microsoft Azure, Google Cloud, or AWS.
If you don’t currently use Autonomous Recovery Service, consider all the advantages of this Oracle-recommended solution and use the checklist below to get started.
Autonomous Recovery Service documentation:
About Oracle Database Autonomous Recovery Service
https://docs.oracle.com/en/cloud/paas/recovery-service/dbrsu/about-recovery-service.html
Checklist to get started with Autonomous Recovery Service
https://blogs.oracle.com/infrastructure/post/autonomous-recovery-service-checklist
OCI Cost Estimator for Autonomous Recovery Service:
https://www.oracle.com/cloud/costestimator/#/load&tag=ZRCV
Oracle Database Services documentation:
Base Database Documentation:
https://docs.oracle.com/en/cloud/paas/base-database/backup-recover/index.html#GUID-A3F9E6F1-9D67-4E80-B91D-E0BEA74F97BD
Base Database tutorial:
https://docs.oracle.com/en/learn/basedb-ltr-backup/
Exadata Documentation:
https://docs.oracle.com/en/engineered-systems/exadata-cloud-service/ecscm/ecs-managing-db-backup-and-recovery.html#GUID-0B078728-CCAB-4717-9A7B-A706FE861542
Exadata Tutorial:
https://docs.oracle.com/en/learn/ltb-odars-exadb/
