Accessibility Policy
Skip to content
Oracle
Oracle Database In-Memory
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Exadata
Features
General Information
Parallelization
RAC
SmartScan Deep Dive
RELATED CONTENT
DBIM Resources
Blogs Home
RSS
Oracle Database In-Memory
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
New Memory Speed Hybrid Columnar Compression feature in Oracle AI ...
Andy Rivenes
1 minute read
Database In-Memory Is Now Available on Oracle Autonomous Database ...
Andy Rivenes
1 minute read
New Database In-Memory Features in Oracle AI Database 26ai
Andy Rivenes
3 minute read
Deep Dive – In-Memory Vector Join Enhancements
Andy Rivenes
6 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Try Always Free cloud services
Start for free
Recent Posts
DBIM Resources
Andy Rivenes
3 minute read
Oracle AI Database 26ai Fast Ingest Enhancements
Andy Rivenes
2 minute read
Oracle AI Database 26ai – Wide Tables
Andy Rivenes
2 minute read
Join Us at AI World 2025 and hear how Big River Steel has used ...
Andy Rivenes
1 minute read
Questions You Asked: What is CELLMEMORY, and how do I know if it is ...
Andy Rivenes
7 minute read
Database In-Memory now supported on Autonomous Database on Dedicated ...
Andy Rivenes
1 minute read
New In-Memory Eligibility Test
Andy Rivenes
3 minute read
New Livelab available – In-Memory Advanced Features
Andy Rivenes
1 minute read
Oracle A Leader in Translytical Data Platforms
Andy Rivenes
1 minute read
Database In-Memory Simple Demo
Andy Rivenes
1 minute read
Using the POPULATE_WAIT function to monitor IM column store population
Andy Rivenes
2 minute read
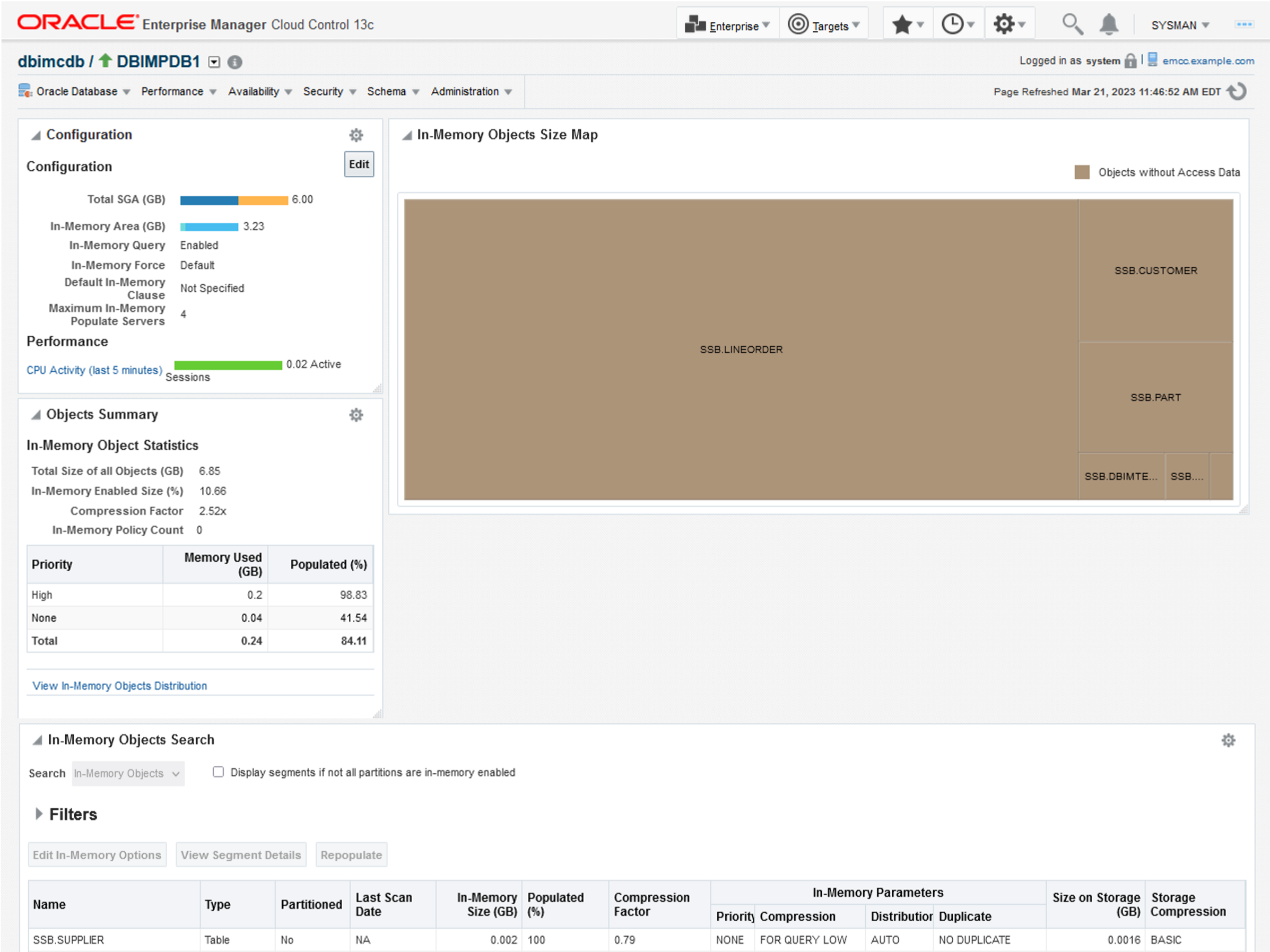
Enterprise Manager In-Memory Central
Andy Rivenes
3 minute read
View more
Try Always Free cloud services
Start for free
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers